 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture-of-Modality-Experts with Holistic Token Learning for Fine-Grained Multimodal Visual Analytics in Driver Action Recognition
Apr 07, 2026Robust multimodal visual analytics remains challenging when heterogeneous modalities provide complementary but input-dependent evidence for decision-making.Existing multimodal learning methods mainly rely on fixed fusion modules or predefined cross-modal interactions, which are often insufficient to adapt to changing modality reliability and to capture fine-grained action cues. To address this issue, we propose a Mixture-of-Modality-Experts (MoME) framework with a Holistic Token Learning (HTL) strategy. MoME enables adaptive collaboration among modality-specific experts, while HTL improves both intra-expert refinement and inter-expert knowledge transfer through class tokens and spatio-temporal tokens. In this way, our method forms a knowledge-centric multimodal learning framework that improves expert specialization while reducing ambiguity in multimodal fusion.We validate the proposed framework on driver action recognition as a representative multimodal understanding taskThe experimental results on the public benchmark show that the proposed MoME framework and the HTL strategy jointly outperform representative single-modal and multimodal baselines. Additional ablation, validation, and visualization results further verify that the proposed HTL strategy improves subtle multimodal understanding and offers better interpretability.
CTooth+: A Large-scale Dental Cone Beam Computed Tomography Dataset and Benchmark for Tooth Volume Segmentation
Aug 02, 2022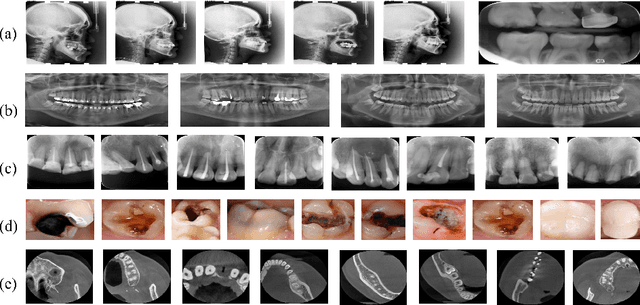
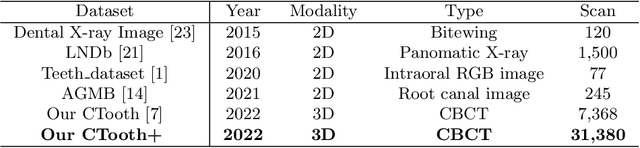
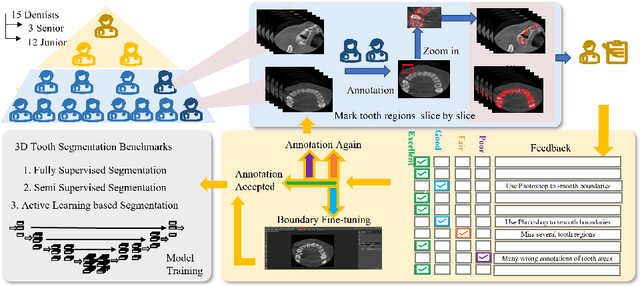
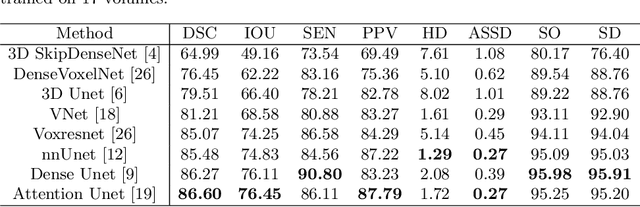
Accurate tooth volume segmentation is a prerequisite for computer-aided dental analysis. Deep learning-based tooth segmentation methods have achieved satisfying performances but require a large quantity of tooth data with ground truth. The dental data publicly available is limited meaning the existing methods can not be reproduced, evaluated and applied in clinical practice. In this paper, we establish a 3D dental CBCT dataset CTooth+, with 22 fully annotated volumes and 146 unlabeled volumes. We further evaluate several state-of-the-art tooth volume segmentation strategies based on fully-supervised learning, semi-supervised learning and active learning, and define the performance principles. This work provides a new benchmark for the tooth volume segmentation task, and the experiment can serve as the baseline for future AI-based dental imaging research and clinical application development.