 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Overthinker's DIET: Cutting Token Calories with DIfficulty-AwarE Training
May 25, 2025Recent large language models (LLMs) exhibit impressive reasoning but often over-think, generating excessively long responses that hinder efficiency. We introduce DIET ( DIfficulty-AwarE Training), a framework that systematically cuts these "token calories" by integrating on-the-fly problem difficulty into the reinforcement learning (RL) process. DIET dynamically adapts token compression strategies by modulating token penalty strength and conditioning target lengths on estimated task difficulty, to optimize the performance-efficiency trade-off. We also theoretically analyze the pitfalls of naive reward weighting in group-normalized RL algorithms like GRPO, and propose Advantage Weighting technique, which enables stable and effective implementation of these difficulty-aware objectives. Experimental results demonstrate that DIET significantly reduces token counts while simultaneously improving reasoning performance. Beyond raw token reduction, we show two crucial benefits largely overlooked by prior work: (1) DIET leads to superior inference scaling. By maintaining high per-sample quality with fewer tokens, it enables better scaling performance via majority voting with more samples under fixed computational budgets, an area where other methods falter. (2) DIET enhances the natural positive correlation between response length and problem difficulty, ensuring verbosity is appropriately allocated, unlike many existing compression methods that disrupt this relationship. Our analyses provide a principled and effective framework for developing more efficient, practical, and high-performing LLMs.
MES-RAG: Bringing Multi-modal, Entity-Storage, and Secure Enhancements to RAG
Mar 17, 2025



Retrieval-Augmented Generation (RAG) improves Large Language Models (LLMs) by using external knowledge, but it struggles with precise entity information retrieval. In this paper, we proposed MES-RAG framework, which enhances entity-specific query handling and provides accurate, secure, and consistent responses. MES-RAG introduces proactive security measures that ensure system integrity by applying protections prior to data access. Additionally, the system supports real-time multi-modal outputs, including text, images, audio, and video, seamlessly integrating into existing RAG architectures. Experimental results demonstrate that MES-RAG significantly improves both accuracy and recall, highlighting its effectiveness in advancing the security and utility of question-answering, increasing accuracy to 0.83 (+0.25) on targeted task. Our code and data are available at https://github.com/wpydcr/MES-RAG.
Enhancing Legal Case Retrieval via Scaling High-quality Synthetic Query-Candidate Pairs
Oct 09, 2024



Legal case retrieval (LCR) aims to provide similar cases as references for a given fact description. This task is crucial for promoting consistent judgments in similar cases, effectively enhancing judicial fairness and improving work efficiency for judges. However, existing works face two main challenges for real-world applications: existing works mainly focus on case-to-case retrieval using lengthy queries, which does not match real-world scenarios; and the limited data scale, with current datasets containing only hundreds of queries, is insufficient to satisfy the training requirements of existing data-hungry neural models. To address these issues, we introduce an automated method to construct synthetic query-candidate pairs and build the largest LCR dataset to date, LEAD, which is hundreds of times larger than existing datasets. This data construction method can provide ample training signals for LCR models. Experimental results demonstrate that model training with our constructed data can achieve state-of-the-art results on two widely-used LCR benchmarks. Besides, the construction method can also be applied to civil cases and achieve promising results. The data and codes can be found in https://github.com/thunlp/LEAD.
Configurable Foundation Models: Building LLMs from a Modular Perspective
Sep 04, 2024



Advancements in LLMs have recently unveiled challenges tied to computational efficiency and continual scalability due to their requirements of huge parameters, making the applications and evolution of these models on devices with limited computation resources and scenarios requiring various abilities increasingly cumbersome. Inspired by modularity within the human brain, there is a growing tendency to decompose LLMs into numerous functional modules, allowing for inference with part of modules and dynamic assembly of modules to tackle complex tasks, such as mixture-of-experts. To highlight the inherent efficiency and composability of the modular approach, we coin the term brick to represent each functional module, designating the modularized structure as configurable foundation models. In this paper, we offer a comprehensive overview and investigation of the construction, utilization, and limitation of configurable foundation models. We first formalize modules into emergent bricks - functional neuron partitions that emerge during the pre-training phase, and customized bricks - bricks constructed via additional post-training to improve the capabilities and knowledge of LLMs. Based on diverse functional bricks, we further present four brick-oriented operations: retrieval and routing, merging, updating, and growing. These operations allow for dynamic configuration of LLMs based on instructions to handle complex tasks. To verify our perspective, we conduct an empirical analysis on widely-used LLMs. We find that the FFN layers follow modular patterns with functional specialization of neurons and functional neuron partitions. Finally, we highlight several open issues and directions for future research. Overall, this paper aims to offer a fresh modular perspective on existing LLM research and inspire the future creation of more efficient and scalable foundational models.
PersLLM: A Personified Training Approach for Large Language Models
Jul 18, 2024



Large language models exhibit aspects of human-level intelligence that catalyze their application as human-like agents in domains such as social simulations, human-machine interactions, and collaborative multi-agent systems. However, the absence of distinct personalities, such as displaying ingratiating behaviors, inconsistent opinions, and uniform response patterns, diminish LLMs utility in practical applications. Addressing this, the development of personality traits in LLMs emerges as a crucial area of research to unlock their latent potential. Existing methods to personify LLMs generally involve strategies like employing stylized training data for instruction tuning or using prompt engineering to simulate different personalities. These methods only capture superficial linguistic styles instead of the core of personalities and are therefore not stable. In this study, we propose PersLLM, integrating psychology-grounded principles of personality: social practice, consistency, and dynamic development, into a comprehensive training methodology. We incorporate personality traits directly into the model parameters, enhancing the model's resistance to induction, promoting consistency, and supporting the dynamic evolution of personality. Single-agent evaluation validates our method's superiority, as it produces responses more aligned with reference personalities compared to other approaches. Case studies for multi-agent communication highlight its benefits in enhancing opinion consistency within individual agents and fostering collaborative creativity among multiple agents in dialogue contexts, potentially benefiting human simulation and multi-agent cooperation. Additionally, human-agent interaction evaluations indicate that our personified models significantly enhance interactive experiences, underscoring the practical implications of our research.
Zero-Shot Generalization during Instruction Tuning: Insights from Similarity and Granularity
Jun 17, 2024



Understanding alignment techniques begins with comprehending zero-shot generalization brought by instruction tuning, but little of the mechanism has been understood. Existing work has largely been confined to the task level, without considering that tasks are artificially defined and, to LLMs, merely consist of tokens and representations. This line of research has been limited to examining transfer between tasks from a task-pair perspective, with few studies focusing on understanding zero-shot generalization from the perspective of the data itself. To bridge this gap, we first demonstrate through multiple metrics that zero-shot generalization during instruction tuning happens very early. Next, we investigate the facilitation of zero-shot generalization from both data similarity and granularity perspectives, confirming that encountering highly similar and fine-grained training data earlier during instruction tuning, without the constraints of defined "tasks", enables better generalization. Finally, we propose a more grounded training data arrangement method, Test-centric Multi-turn Arrangement, and show its effectiveness in promoting continual learning and further loss reduction. For the first time, we show that zero-shot generalization during instruction tuning is a form of similarity-based generalization between training and test data at the instance level. We hope our analysis will advance the understanding of zero-shot generalization during instruction tuning and contribute to the development of more aligned LLMs. Our code is released at https://github.com/HBX-hbx/dynamics_of_zero-shot_generalization.
Advancing LLM Reasoning Generalists with Preference Trees
Apr 02, 2024



We introduce Eurus, a suite of large language models (LLMs) optimized for reasoning. Finetuned from Mistral-7B and CodeLlama-70B, Eurus models achieve state-of-the-art results among open-source models on a diverse set of benchmarks covering mathematics, code generation, and logical reasoning problems. Notably, Eurus-70B beats GPT-3.5 Turbo in reasoning through a comprehensive benchmarking across 12 tests covering five tasks, and achieves a 33.3% pass@1 accuracy on LeetCode and 32.6% on TheoremQA, two challenging benchmarks, substantially outperforming existing open-source models by margins more than 13.3%. The strong performance of Eurus can be primarily attributed to UltraInteract, our newly-curated large-scale, high-quality alignment dataset specifically designed for complex reasoning tasks. UltraInteract can be used in both supervised fine-tuning and preference learning. For each instruction, it includes a preference tree consisting of (1) reasoning chains with diverse planning strategies in a unified format, (2) multi-turn interaction trajectories with the environment and the critique, and (3) pairwise data to facilitate preference learning. UltraInteract allows us to conduct an in-depth exploration of preference learning for reasoning tasks. Our investigation reveals that some well-established preference learning algorithms may be less suitable for reasoning tasks compared to their effectiveness in general conversations. Inspired by this, we derive a novel reward modeling objective which, together with UltraInteract, leads to a strong reward model.
Controllable Preference Optimization: Toward Controllable Multi-Objective Alignment
Feb 29, 2024



Alignment in artificial intelligence pursues the consistency between model responses and human preferences as well as values. In practice, the multifaceted nature of human preferences inadvertently introduces what is known as the "alignment tax" -a compromise where enhancements in alignment within one objective (e.g.,harmlessness) can diminish performance in others (e.g.,helpfulness). However, existing alignment techniques are mostly unidirectional, leading to suboptimal trade-offs and poor flexibility over various objectives. To navigate this challenge, we argue the prominence of grounding LLMs with evident preferences. We introduce controllable preference optimization (CPO), which explicitly specifies preference scores for different objectives, thereby guiding the model to generate responses that meet the requirements. Our experimental analysis reveals that the aligned models can provide responses that match various preferences among the "3H" (helpfulness, honesty, harmlessness) desiderata. Furthermore, by introducing diverse data and alignment goals, we surpass baseline methods in aligning with single objectives, hence mitigating the impact of the alignment tax and achieving Pareto improvements in multi-objective alignment.
Exploration into Optimal State Estimation with Event-triggered Communication
Sep 15, 2023



This paper deals with the problem of remote estimation of the state of a discrete-time stochastic linear system observed by a sensor with computational capacity to calculate local estimates. We design an event-triggered communication (ETC) scheme and a remote state estimator to optimally calibrate the tradeoff between system performance and limited communication resources. The novel communication scheme is the time-varying thresholding version for the cumulative innovation-driven communication scheme in [1], and its transmission probability is given. We derive the corresponding remote minimum mean square error (MMSE) estimator and present a tight upper bound for its MSE matrices. We also show that by employing a couple of weak assumptions, the optimality problem becomes (asymptotically) exact and can be addressed in an Markov Decision Process (MDP) framework, which delivers optimal policy and cost in an algorithmic procedure. The simulation results illustrate the effectiveness of our approach.
Country Image in COVID-19 Pandemic: A Case Study of China
Sep 12, 2020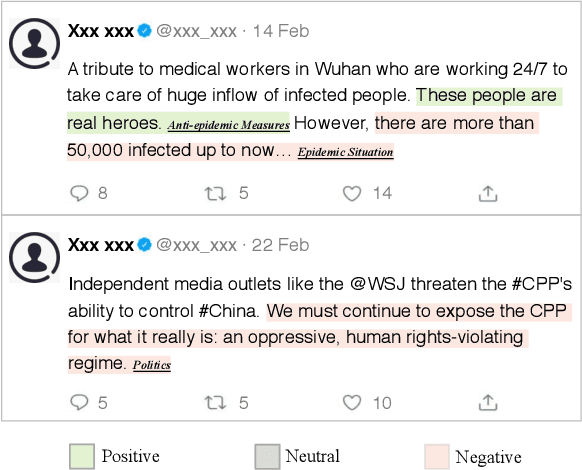
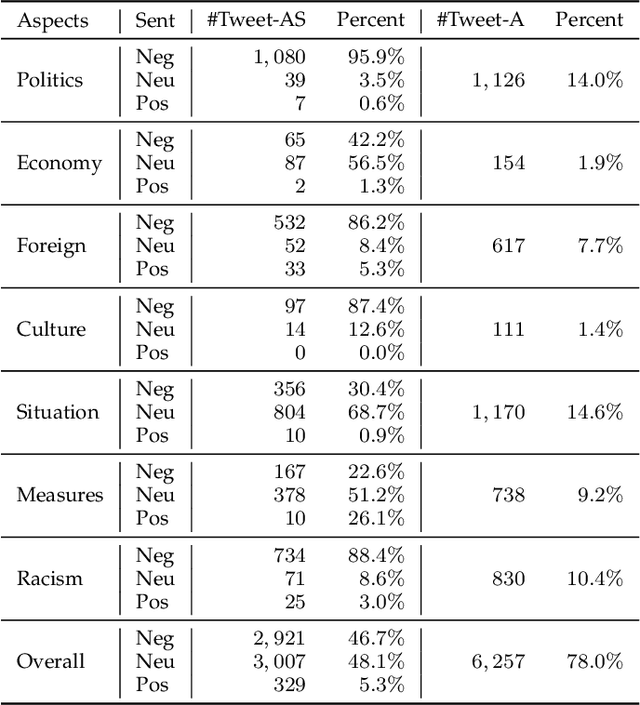
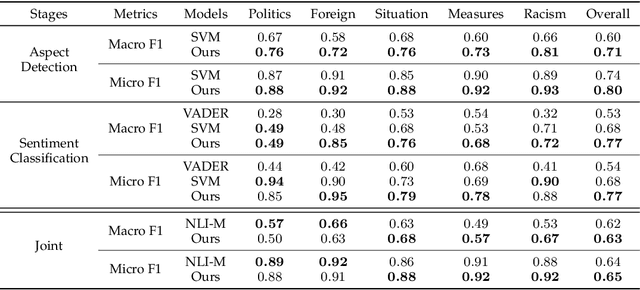
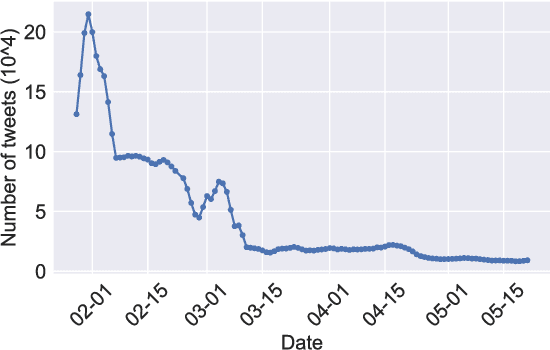
Country image has a profound influence on international relations and economic development. In the worldwide outbreak of COVID-19, countries and their people display different reactions, resulting in diverse perceived images among foreign public. Therefore, in this study, we take China as a specific and typical case and investigate its image with aspect-based sentiment analysis on a large-scale Twitter dataset. To our knowledge, this is the first study to explore country image in such a fine-grained way. To perform the analysis, we first build a manually-labeled Twitter dataset with aspect-level sentiment annotations. Afterward, we conduct the aspect-based sentiment analysis with BERT to explore the image of China. We discover an overall sentiment change from non-negative to negative in the general public, and explain it with the increasing mentions of negative ideology-related aspects and decreasing mentions of non-negative fact-based aspects. Further investigations into different groups of Twitter users, including U.S. Congress members, English media, and social bots, reveal different patterns in their attitudes toward China. This study provides a deeper understanding of the changing image of China in COVID-19 pandemic. Our research also demonstrates how aspect-based sentiment analysis can be applied in social science researches to deliver valuable insights.