 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-fidelity Multiphysics Modelling for Rapid Predictions Using Physics-informed Parallel Neural Operator
Feb 26, 2025



Modelling complex multiphysics systems governed by nonlinear and strongly coupled partial differential equations (PDEs) is a cornerstone in computational science and engineering. However, it remains a formidable challenge for traditional numerical solvers due to high computational cost, making them impractical for large-scale applications. Neural operators' reliance on data-driven training limits their applicability in real-world scenarios, as data is often scarce or expensive to obtain. Here, we propose a novel paradigm, physics-informed parallel neural operator (PIPNO), a scalable and unsupervised learning framework that enables data-free PDE modelling by leveraging only governing physical laws. The parallel kernel integration design, incorporating ensemble learning, significantly enhances both compatibility and computational efficiency, enabling scalable operator learning for nonlinear and strongly coupled PDEs. PIPNO efficiently captures nonlinear operator mappings across diverse physics, including geotechnical engineering, material science, electromagnetism, quantum mechanics, and fluid dynamics. The proposed method achieves high-fidelity and rapid predictions, outperforming existing operator learning approaches in modelling nonlinear and strongly coupled multiphysics systems. Therefore, PIPNO offers a powerful alternative to conventional solvers, broadening the applicability of neural operators for multiphysics modelling while ensuring efficiency, robustness, and scalability.
FetchBot: Object Fetching in Cluttered Shelves via Zero-Shot Sim2Real
Feb 25, 2025



Object fetching from cluttered shelves is an important capability for robots to assist humans in real-world scenarios. Achieving this task demands robotic behaviors that prioritize safety by minimizing disturbances to surrounding objects, an essential but highly challenging requirement due to restricted motion space, limited fields of view, and complex object dynamics. In this paper, we introduce FetchBot, a sim-to-real framework designed to enable zero-shot generalizable and safety-aware object fetching from cluttered shelves in real-world settings. To address data scarcity, we propose an efficient voxel-based method for generating diverse simulated cluttered shelf scenes at scale and train a dynamics-aware reinforcement learning (RL) policy to generate object fetching trajectories within these scenes. This RL policy, which leverages oracle information, is subsequently distilled into a vision-based policy for real-world deployment. Considering that sim-to-real discrepancies stem from texture variations mostly while from geometric dimensions rarely, we propose to adopt depth information estimated by full-fledged depth foundation models as the input for the vision-based policy to mitigate sim-to-real gap. To tackle the challenge of limited views, we design a novel architecture for learning multi-view representations, allowing for comprehensive encoding of cluttered shelf scenes. This enables FetchBot to effectively minimize collisions while fetching objects from varying positions and depths, ensuring robust and safety-aware operation. Both simulation and real-robot experiments demonstrate FetchBot's superior generalization ability, particularly in handling a broad range of real-world scenarios, includ
UASTrack: A Unified Adaptive Selection Framework with Modality-Customization in Single Object Tracking
Feb 25, 2025



Multi-modal tracking is essential in single-object tracking (SOT), as different sensor types contribute unique capabilities to overcome challenges caused by variations in object appearance. However, existing unified RGB-X trackers (X represents depth, event, or thermal modality) either rely on the task-specific training strategy for individual RGB-X image pairs or fail to address the critical importance of modality-adaptive perception in real-world applications. In this work, we propose UASTrack, a unified adaptive selection framework that facilitates both model and parameter unification, as well as adaptive modality discrimination across various multi-modal tracking tasks. To achieve modality-adaptive perception in joint RGB-X pairs, we design a Discriminative Auto-Selector (DAS) capable of identifying modality labels, thereby distinguishing the data distributions of auxiliary modalities. Furthermore, we propose a Task-Customized Optimization Adapter (TCOA) tailored to various modalities in the latent space. This strategy effectively filters noise redundancy and mitigates background interference based on the specific characteristics of each modality. Extensive comparisons conducted on five benchmarks including LasHeR, GTOT, RGBT234, VisEvent, and DepthTrack, covering RGB-T, RGB-E, and RGB-D tracking scenarios, demonstrate our innovative approach achieves comparative performance by introducing only additional training parameters of 1.87M and flops of 1.95G. The code will be available at https://github.com/wanghe/UASTrack.
Watch Less, Feel More: Sim-to-Real RL for Generalizable Articulated Object Manipulation via Motion Adaptation and Impedance Control
Feb 20, 2025Articulated object manipulation poses a unique challenge compared to rigid object manipulation as the object itself represents a dynamic environment. In this work, we present a novel RL-based pipeline equipped with variable impedance control and motion adaptation leveraging observation history for generalizable articulated object manipulation, focusing on smooth and dexterous motion during zero-shot sim-to-real transfer. To mitigate the sim-to-real gap, our pipeline diminishes reliance on vision by not leveraging the vision data feature (RGBD/pointcloud) directly as policy input but rather extracting useful low-dimensional data first via off-the-shelf modules. Additionally, we experience less sim-to-real gap by inferring object motion and its intrinsic properties via observation history as well as utilizing impedance control both in the simulation and in the real world. Furthermore, we develop a well-designed training setting with great randomization and a specialized reward system (task-aware and motion-aware) that enables multi-staged, end-to-end manipulation without heuristic motion planning. To the best of our knowledge, our policy is the first to report 84\% success rate in the real world via extensive experiments with various unseen objects.
SoFar: Language-Grounded Orientation Bridges Spatial Reasoning and Object Manipulation
Feb 18, 2025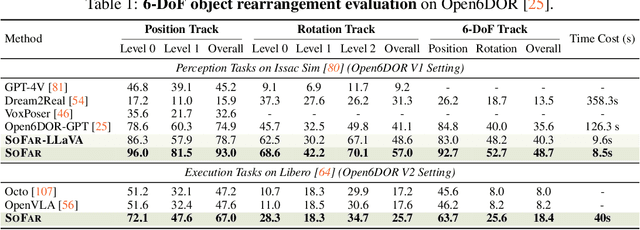

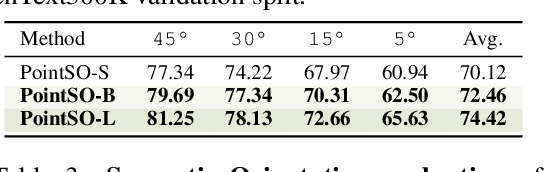
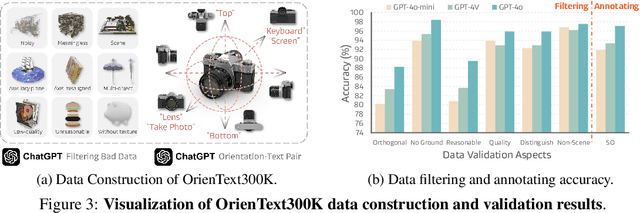
Spatial intelligence is a critical component of embodied AI, promoting robots to understand and interact with their environments. While recent advances have enhanced the ability of VLMs to perceive object locations and positional relationships, they still lack the capability to precisely understand object orientations-a key requirement for tasks involving fine-grained manipulations. Addressing this limitation not only requires geometric reasoning but also an expressive and intuitive way to represent orientation. In this context, we propose that natural language offers a more flexible representation space than canonical frames, making it particularly suitable for instruction-following robotic systems. In this paper, we introduce the concept of semantic orientation, which defines object orientations using natural language in a reference-frame-free manner (e.g., the ''plug-in'' direction of a USB or the ''handle'' direction of a knife). To support this, we construct OrienText300K, a large-scale dataset of 3D models annotated with semantic orientations that link geometric understanding to functional semantics. By integrating semantic orientation into a VLM system, we enable robots to generate manipulation actions with both positional and orientational constraints. Extensive experiments in simulation and real world demonstrate that our approach significantly enhances robotic manipulation capabilities, e.g., 48.7% accuracy on Open6DOR and 74.9% accuracy on SIMPLER.
MobileH2R: Learning Generalizable Human to Mobile Robot Handover Exclusively from Scalable and Diverse Synthetic Data
Jan 08, 2025



This paper introduces MobileH2R, a framework for learning generalizable vision-based human-to-mobile-robot (H2MR) handover skills. Unlike traditional fixed-base handovers, this task requires a mobile robot to reliably receive objects in a large workspace enabled by its mobility. Our key insight is that generalizable handover skills can be developed in simulators using high-quality synthetic data, without the need for real-world demonstrations. To achieve this, we propose a scalable pipeline for generating diverse synthetic full-body human motion data, an automated method for creating safe and imitation-friendly demonstrations, and an efficient 4D imitation learning method for distilling large-scale demonstrations into closed-loop policies with base-arm coordination. Experimental evaluations in both simulators and the real world show significant improvements (at least +15% success rate) over baseline methods in all cases. Experiments also validate that large-scale and diverse synthetic data greatly enhances robot learning, highlighting our scalable framework.
Mimicking-Bench: A Benchmark for Generalizable Humanoid-Scene Interaction Learning via Human Mimicking
Dec 23, 2024Learning generic skills for humanoid robots interacting with 3D scenes by mimicking human data is a key research challenge with significant implications for robotics and real-world applications. However, existing methodologies and benchmarks are constrained by the use of small-scale, manually collected demonstrations, lacking the general dataset and benchmark support necessary to explore scene geometry generalization effectively. To address this gap, we introduce Mimicking-Bench, the first comprehensive benchmark designed for generalizable humanoid-scene interaction learning through mimicking large-scale human animation references. Mimicking-Bench includes six household full-body humanoid-scene interaction tasks, covering 11K diverse object shapes, along with 20K synthetic and 3K real-world human interaction skill references. We construct a complete humanoid skill learning pipeline and benchmark approaches for motion retargeting, motion tracking, imitation learning, and their various combinations. Extensive experiments highlight the value of human mimicking for skill learning, revealing key challenges and research directions.
Chumor 2.0: Towards Benchmarking Chinese Humor Understanding
Dec 23, 2024



Existing humor datasets and evaluations predominantly focus on English, leaving limited resources for culturally nuanced humor in non-English languages like Chinese. To address this gap, we construct Chumor, the first Chinese humor explanation dataset that exceeds the size of existing humor datasets. Chumor is sourced from Ruo Zhi Ba, a Chinese Reddit-like platform known for sharing intellectually challenging and culturally specific jokes. We test ten LLMs through direct and chain-of-thought prompting, revealing that Chumor poses significant challenges to existing LLMs, with their accuracy slightly above random and far below human. In addition, our analysis highlights that human-annotated humor explanations are significantly better than those generated by GPT-4o and ERNIE-4-turbo. We release Chumor at https://huggingface.co/datasets/dnaihao/Chumor, our project page is at https://dnaihao.github.io/Chumor-dataset/, our leaderboard is at https://huggingface.co/spaces/dnaihao/Chumor, and our codebase is at https://github.com/dnaihao/Chumor-dataset.
BODex: Scalable and Efficient Robotic Dexterous Grasp Synthesis Using Bilevel Optimization
Dec 21, 2024



Robotic dexterous grasping is a key step toward human-like manipulation. To fully unleash the potential of data-driven models for dexterous grasping, a large-scale, high-quality dataset is essential. While gradient-based optimization offers a promising way for constructing such datasets, existing works suffer from limitations, such as restrictive assumptions in energy design or limited experiments on small object sets. Moreover, the lack of a standard benchmark for comparing synthesis methods and datasets hinders progress in this field. To address these challenges, we develop a highly efficient synthesis system and a comprehensive benchmark with MuJoCo for dexterous grasping. Our system formulates grasp synthesis as a bilevel optimization problem, combining a novel lower-level quadratic programming (QP) with an upper-level gradient descent process. By leveraging recent advances in CUDA-accelerated robotic libraries and GPU-based QP solvers, our system can parallelize thousands of grasps and synthesize over 49 grasps per second on a single NVIDIA 3090 GPU. Our synthesized grasps for Shadow Hand and Allegro Hand achieve a success rate above 75% in MuJoCo, with a penetration depth and contact distance of under 1 mm, outperforming existing baselines on nearly all metrics. Compared to the previous large-scale dataset, DexGraspNet, our dataset significantly improves the performance of learning models, with a simulation success rate from around 40% to 80%. Real-world testing of the trained model on the Shadow Hand achieves an 81% success rate across 20 diverse objects.
CAMEL: Cross-Attention Enhanced Mixture-of-Experts and Language Bias for Code-Switching Speech Recognition
Dec 17, 2024



Code-switching automatic speech recognition (ASR) aims to transcribe speech that contains two or more languages accurately. To better capture language-specific speech representations and address language confusion in code-switching ASR, the mixture-of-experts (MoE) architecture and an additional language diarization (LD) decoder are commonly employed. However, most researches remain stagnant in simple operations like weighted summation or concatenation to fuse language-specific speech representations, leaving significant opportunities to explore the enhancement of integrating language bias information. In this paper, we introduce CAMEL, a cross-attention-based MoE and language bias approach for code-switching ASR. Specifically, after each MoE layer, we fuse language-specific speech representations with cross-attention, leveraging its strong contextual modeling abilities. Additionally, we design a source attention-based mechanism to incorporate the language information from the LD decoder output into text embeddings. Experimental results demonstrate that our approach achieves state-of-the-art performance on the SEAME, ASRU200, and ASRU700+LibriSpeech460 Mandarin-English code-switching ASR datasets.