 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCDiar: a streaming diarization system based on speaker change detection and speech recognition
Jan 28, 2025



In hours-long meeting scenarios, real-time speech stream often struggles with achieving accurate speaker diarization, commonly leading to speaker identification and speaker count errors. To address this challenge, we propose SCDiar, a system that operates on speech segments, split at the token level by a speaker change detection (SCD) module. Building on these segments, we introduce several enhancements to efficiently select the best available segment for each speaker. These improvements lead to significant gains across various benchmarks. Notably, on real-world meeting data involving more than ten participants, SCDiar outperforms previous systems by up to 53.6\% in accuracy, substantially narrowing the performance gap between online and offline systems.
CAMEL: Cross-Attention Enhanced Mixture-of-Experts and Language Bias for Code-Switching Speech Recognition
Dec 17, 2024



Code-switching automatic speech recognition (ASR) aims to transcribe speech that contains two or more languages accurately. To better capture language-specific speech representations and address language confusion in code-switching ASR, the mixture-of-experts (MoE) architecture and an additional language diarization (LD) decoder are commonly employed. However, most researches remain stagnant in simple operations like weighted summation or concatenation to fuse language-specific speech representations, leaving significant opportunities to explore the enhancement of integrating language bias information. In this paper, we introduce CAMEL, a cross-attention-based MoE and language bias approach for code-switching ASR. Specifically, after each MoE layer, we fuse language-specific speech representations with cross-attention, leveraging its strong contextual modeling abilities. Additionally, we design a source attention-based mechanism to incorporate the language information from the LD decoder output into text embeddings. Experimental results demonstrate that our approach achieves state-of-the-art performance on the SEAME, ASRU200, and ASRU700+LibriSpeech460 Mandarin-English code-switching ASR datasets.
XCB: an effective contextual biasing approach to bias cross-lingual phrases in speech recognition
Aug 20, 2024


Contextualized ASR models have been demonstrated to effectively improve the recognition accuracy of uncommon phrases when a predefined phrase list is available. However, these models often struggle with bilingual settings, which are prevalent in code-switching speech recognition. In this study, we make the initial attempt to address this challenge by introducing a Cross-lingual Contextual Biasing(XCB) module. Specifically, we augment a pre-trained ASR model for the dominant language by integrating an auxiliary language biasing module and a supplementary language-specific loss, aimed at enhancing the recognition of phrases in the secondary language. Experimental results conducted on our in-house code-switching dataset have validated the efficacy of our approach, demonstrating significant improvements in the recognition of biasing phrases in the secondary language, even without any additional inference overhead. Additionally, our proposed system exhibits both efficiency and generalization when is applied by the unseen ASRU-2019 test set.
An efficient text augmentation approach for contextualized Mandarin speech recognition
Jun 14, 2024



Although contextualized automatic speech recognition (ASR) systems are commonly used to improve the recognition of uncommon words, their effectiveness is hindered by the inherent limitations of speech-text data availability. To address this challenge, our study proposes to leverage extensive text-only datasets and contextualize pre-trained ASR models using a straightforward text-augmentation (TA) technique, all while keeping computational costs minimal. In particular, to contextualize a pre-trained CIF-based ASR, we construct a codebook using limited speech-text data. By utilizing a simple codebook lookup process, we convert available text-only data into latent text embeddings. These embeddings then enhance the inputs for the contextualized ASR. Our experiments on diverse Mandarin test sets demonstrate that our TA approach significantly boosts recognition performance. The top-performing system shows relative CER improvements of up to 30% on rare words and 15% across all words in general.
MMGER: Multi-modal and Multi-granularity Generative Error Correction with LLM for Joint Accent and Speech Recognition
May 06, 2024



Despite notable advancements in automatic speech recognition (ASR), performance tends to degrade when faced with adverse conditions. Generative error correction (GER) leverages the exceptional text comprehension capabilities of large language models (LLM), delivering impressive performance in ASR error correction, where N-best hypotheses provide valuable information for transcription prediction. However, GER encounters challenges such as fixed N-best hypotheses, insufficient utilization of acoustic information, and limited specificity to multi-accent scenarios. In this paper, we explore the application of GER in multi-accent scenarios. Accents represent deviations from standard pronunciation norms, and the multi-task learning framework for simultaneous ASR and accent recognition (AR) has effectively addressed the multi-accent scenarios, making it a prominent solution. In this work, we propose a unified ASR-AR GER model, named MMGER, leveraging multi-modal correction, and multi-granularity correction. Multi-task ASR-AR learning is employed to provide dynamic 1-best hypotheses and accent embeddings. Multi-modal correction accomplishes fine-grained frame-level correction by force-aligning the acoustic features of speech with the corresponding character-level 1-best hypothesis sequence. Multi-granularity correction supplements the global linguistic information by incorporating regular 1-best hypotheses atop fine-grained multi-modal correction to achieve coarse-grained utterance-level correction. MMGER effectively mitigates the limitations of GER and tailors LLM-based ASR error correction for the multi-accent scenarios. Experiments conducted on the multi-accent Mandarin KeSpeech dataset demonstrate the efficacy of MMGER, achieving a 26.72% relative improvement in AR accuracy and a 27.55% relative reduction in ASR character error rate, compared to a well-established standard baseline.
BA-MoE: Boundary-Aware Mixture-of-Experts Adapter for Code-Switching Speech Recognition
Oct 08, 2023Mixture-of-experts based models, which use language experts to extract language-specific representations effectively, have been well applied in code-switching automatic speech recognition. However, there is still substantial space to improve as similar pronunciation across languages may result in ineffective multi-language modeling and inaccurate language boundary estimation. To eliminate these drawbacks, we propose a cross-layer language adapter and a boundary-aware training method, namely Boundary-Aware Mixture-of-Experts (BA-MoE). Specifically, we introduce language-specific adapters to separate language-specific representations and a unified gating layer to fuse representations within each encoder layer. Second, we compute language adaptation loss of the mean output of each language-specific adapter to improve the adapter module's language-specific representation learning. Besides, we utilize a boundary-aware predictor to learn boundary representations for dealing with language boundary confusion. Our approach achieves significant performance improvement, reducing the mixture error rate by 16.55\% compared to the baseline on the ASRU 2019 Mandarin-English code-switching challenge dataset.
Partially Fake Audio Detection by Self-attention-based Fake Span Discovery
Feb 15, 2022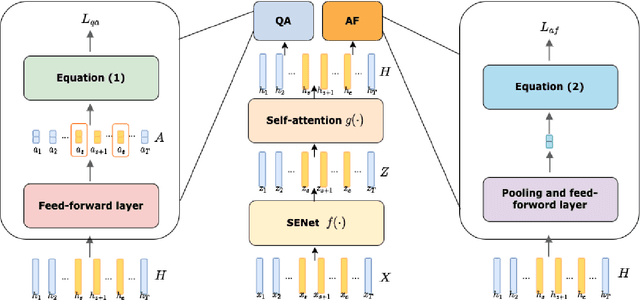
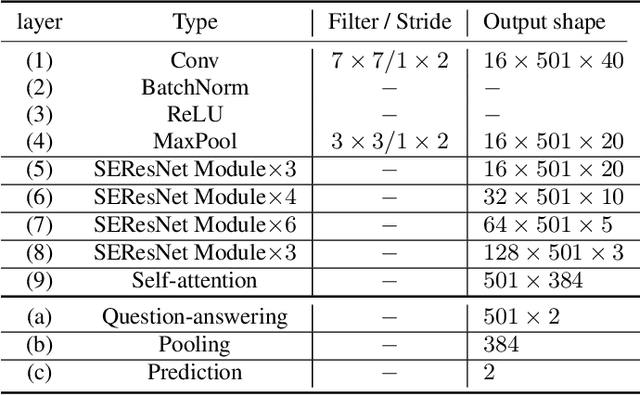

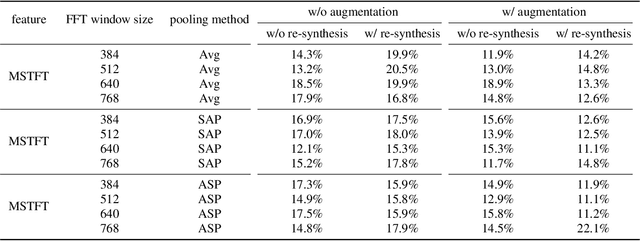
The past few years have witnessed the significant advances of speech synthesis and voice conversion technologies. However, such technologies can undermine the robustness of broadly implemented biometric identification models and can be harnessed by in-the-wild attackers for illegal uses. The ASVspoof challenge mainly focuses on synthesized audios by advanced speech synthesis and voice conversion models, and replay attacks. Recently, the first Audio Deep Synthesis Detection challenge (ADD 2022) extends the attack scenarios into more aspects. Also ADD 2022 is the first challenge to propose the partially fake audio detection task. Such brand new attacks are dangerous and how to tackle such attacks remains an open question. Thus, we propose a novel framework by introducing the question-answering (fake span discovery) strategy with the self-attention mechanism to detect partially fake audios. The proposed fake span detection module tasks the anti-spoofing model to predict the start and end positions of the fake clip within the partially fake audio, address the model's attention into discovering the fake spans rather than other shortcuts with less generalization, and finally equips the model with the discrimination capacity between real and partially fake audios. Our submission ranked second in the partially fake audio detection track of ADD 2022.
The CUHK-TENCENT speaker diarization system for the ICASSP 2022 multi-channel multi-party meeting transcription challenge
Feb 04, 2022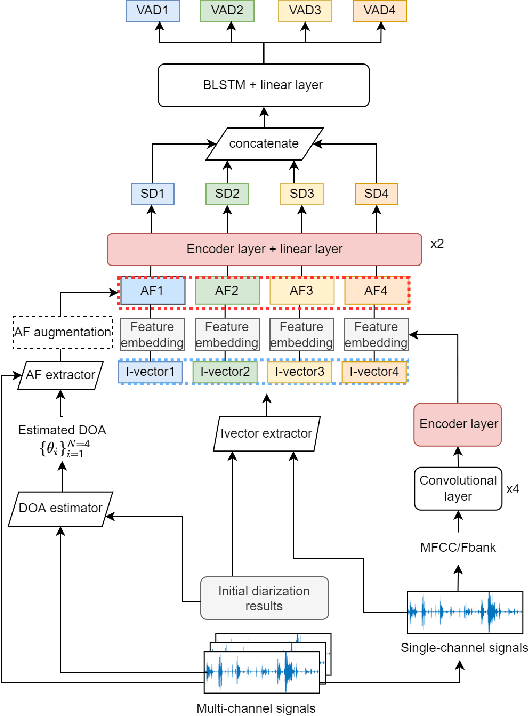
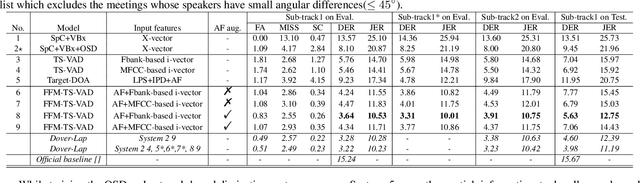
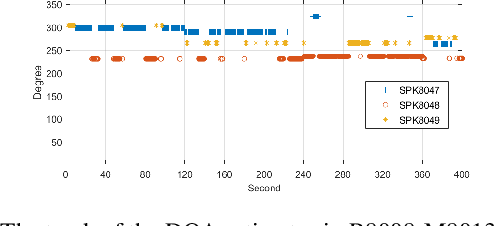
This paper describes our speaker diarization system submitted to the Multi-channel Multi-party Meeting Transcription (M2MeT) challenge, where Mandarin meeting data were recorded in multi-channel format for diarization and automatic speech recognition (ASR) tasks. In these meeting scenarios, the uncertainty of the speaker number and the high ratio of overlapped speech present great challenges for diarization. Based on the assumption that there is valuable complementary information between acoustic features, spatial-related and speaker-related features, we propose a multi-level feature fusion mechanism based target-speaker voice activity detection (FFM-TS-VAD) system to improve the performance of the conventional TS-VAD system. Furthermore, we propose a data augmentation method during training to improve the system robustness when the angular difference between two speakers is relatively small. We provide comparisons for different sub-systems we used in M2MeT challenge. Our submission is a fusion of several sub-systems and ranks second in the diarization task.