 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePanoptic-DeepLab: A Simple, Strong, and Fast Baseline for Bottom-Up Panoptic Segmentation
Dec 06, 2019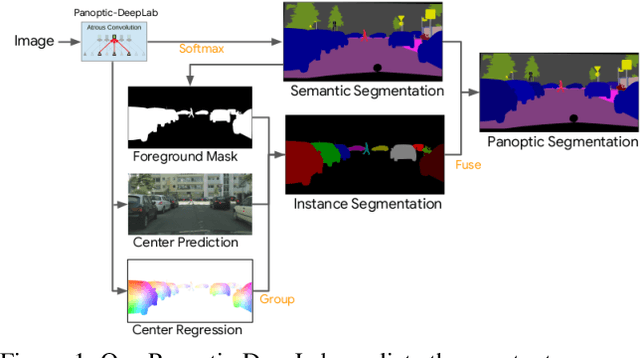

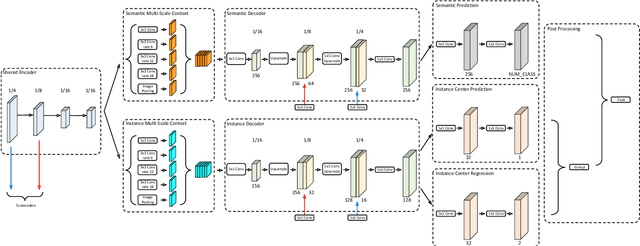
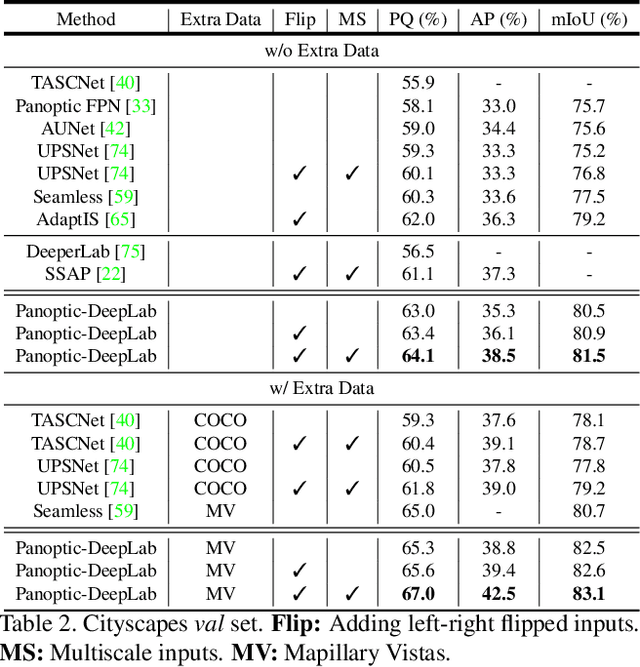
In this work, we introduce Panoptic-DeepLab, a simple, strong, and fast system for panoptic segmentation, aiming to establish a solid baseline for bottom-up methods that can achieve comparable performance of two-stage methods while yielding fast inference speed. In particular, PanopticDeepLab adopts the dual-ASPP and dual-decoder structures specific to semantic, and instance segmentation, respectively. The semantic segmentation branch is the same as the typical design of any semantic segmentation model (e.g., DeepLab), while the instance segmentation branch is class-agnostic, involving a simple instance center regression. As a result, our single Panoptic-DeepLab simultaneously ranks first at all three Cityscapes benchmarks, setting the new state-of-art of 84.2% mIoU, 39.0% AP, and 65.5% PQ on test set. Additionally, equipped with MobileNetV3, Panoptic-DeepLab runs nearly in real-time with a single 1025 x 2049 image (15.8 frames per second), while achieving a competitive performance on Cityscapes (54.1 PQ% on test set). On Mapillary Vistas test set, our ensemble of six models attains 42.7% PQ, outperforming the challenge winner in 2018 by a healthy margin of 1.5%. Finally, our Panoptic-DeepLab also performs on par with several topdown approaches on the challenging COCO dataset. For the first time, we demonstrate a bottom-up approach could deliver state-of-the-art results on panoptic segmentation.
View-Invariant Probabilistic Embedding for Human Pose
Dec 02, 2019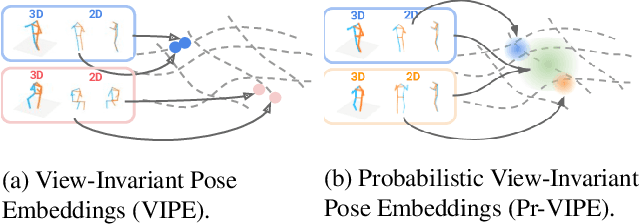
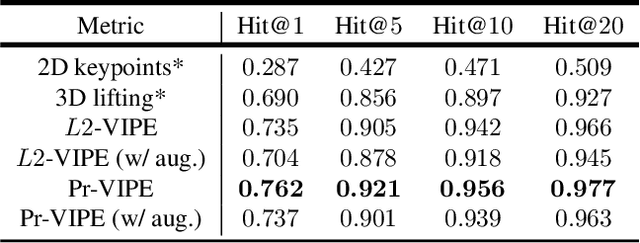
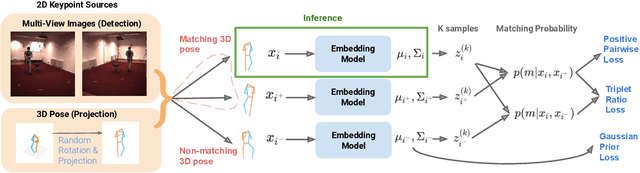
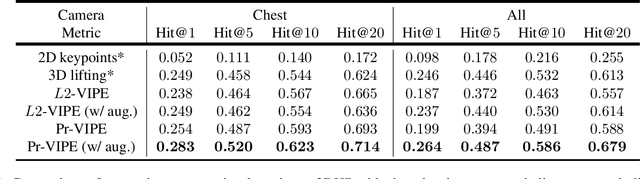
Depictions of similar human body configurations can vary with changing viewpoints. Using only 2D information, we would like to enable vision algorithms to recognize similarity in human body poses across multiple views. This ability is useful for analyzing body movements and human behaviors in images and videos. In this paper, we propose an approach for learning a compact view-invariant embedding space from 2D joint keypoints alone, without explicitly predicting 3D poses. Since 2D poses are projected from 3D space, they have an inherent ambiguity, which is difficult to represent through a deterministic mapping. Hence, we use probabilistic embeddings to model this input uncertainty. Experimental results show that our embedding model achieves higher accuracy when retrieving similar poses across different camera views, in comparison with 2D-to-3D pose lifting models. The results also suggest that our model is able to generalize across datasets, and our embedding variance correlates with input pose ambiguity.
Panoptic-DeepLab
Oct 24, 2019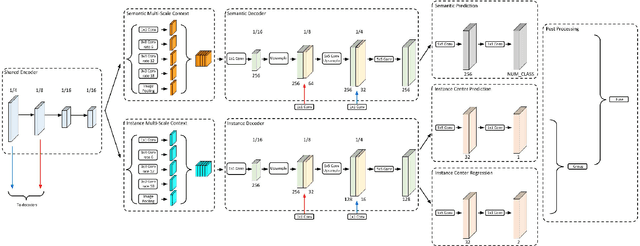
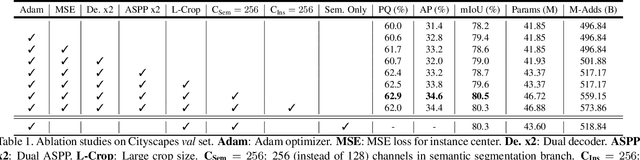
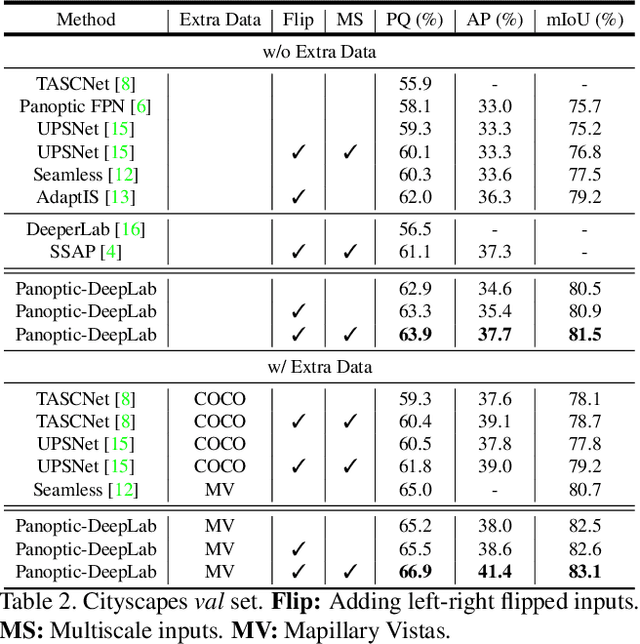
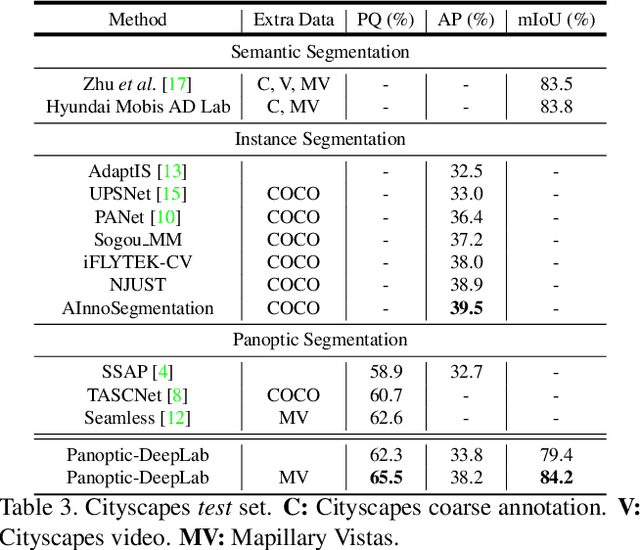
We present Panoptic-DeepLab, a bottom-up and single-shot approach for panoptic segmentation. Our Panoptic-DeepLab is conceptually simple and delivers state-of-the-art results. In particular, we adopt the dual-ASPP and dual-decoder structures specific to semantic, and instance segmentation, respectively. The semantic segmentation branch is the same as the typical design of any semantic segmentation model (e.g., DeepLab), while the instance segmentation branch is class-agnostic, involving a simple instance center regression. Our single Panoptic-DeepLab sets the new state-of-art at all three Cityscapes benchmarks, reaching 84.2% mIoU, 39.0% AP, and 65.5% PQ on test set, and advances results on the other challenging Mapillary Vistas.
The iMaterialist Fashion Attribute Dataset
Jun 14, 2019
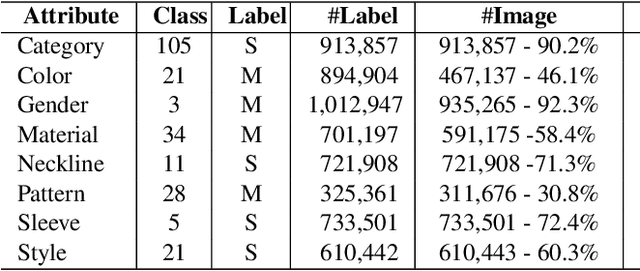
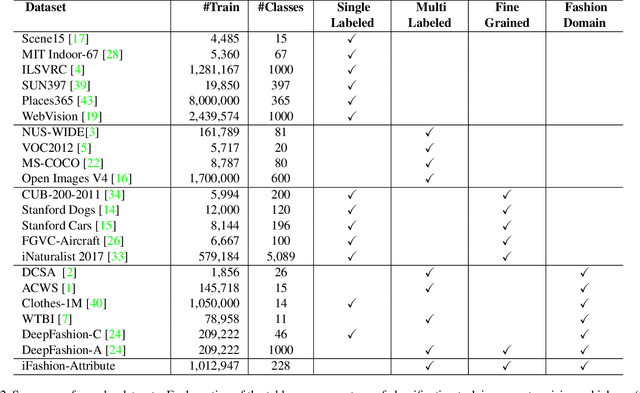
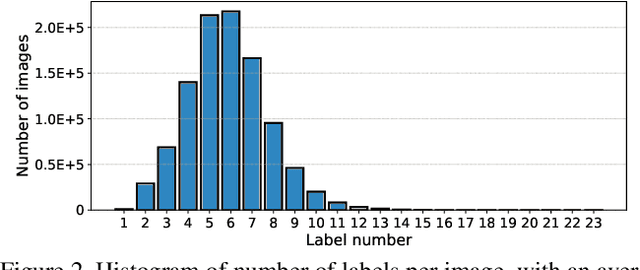
Large-scale image databases such as ImageNet have significantly advanced image classification and other visual recognition tasks. However much of these datasets are constructed only for single-label and coarse object-level classification. For real-world applications, multiple labels and fine-grained categories are often needed, yet very few such datasets exist publicly, especially those of large-scale and high quality. In this work, we contribute to the community a new dataset called iMaterialist Fashion Attribute (iFashion-Attribute) to address this problem in the fashion domain. The dataset is constructed from over one million fashion images with a label space that includes 8 groups of 228 fine-grained attributes in total. Each image is annotated by experts with multiple, high-quality fashion attributes. The result is the first known million-scale multi-label and fine-grained image dataset. We conduct extensive experiments and provide baseline results with modern deep Convolutional Neural Networks (CNNs). Additionally, we demonstrate models pre-trained on iFashion-Attribute achieve superior transfer learning performance on fashion related tasks compared with pre-training from ImageNet or other fashion datasets. Data is available at: https://github.com/visipedia/imat_fashion_comp
Geo-Aware Networks for Fine Grained Recognition
Jun 04, 2019
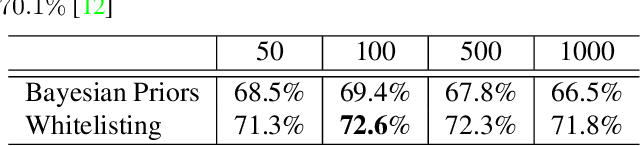
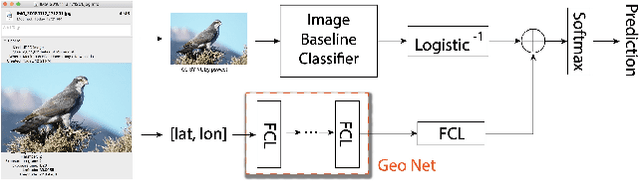
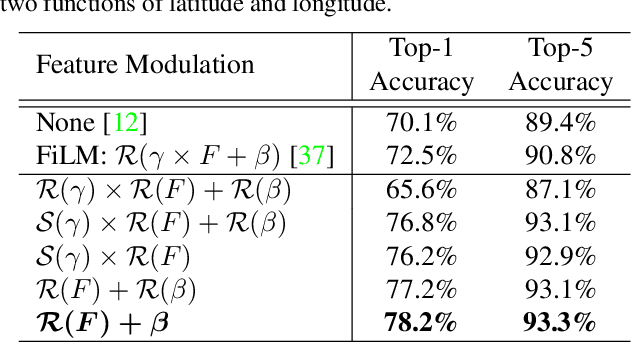
Fine grained recognition distinguishes among categories with subtle visual differences. To help identify fine grained categories, other information besides images has been used. However, there has been little effort on using geolocation information to improve fine grained classification accuracy. Our contributions to this field are twofold. First, to the best of our knowledge, this is the first paper which systematically examined various ways of incorporating geolocation information to fine grained images classification - from geolocation priors, to post-processing, to feature modulation. Secondly, to overcome the situation where no fine grained dataset has complete geolocation information, we introduce, and will make public, two fine grained datasets with geolocation by providing complementary information to existing popular datasets - iNaturalist and YFCC100M. Results on these datasets show that, the best geo-aware network can achieve 8.9% top-1 accuracy increase on iNaturalist and 5.9% increase on YFCC100M, compared with image only models' results. In addition, for small image baseline models like Mobilenet V2, the best geo-aware network gives 12.6% higher top-1 accuracy than image only model, achieving even higher performance than Inception V3 models without geolocation. Our work gives incentives to use geolocation information to improve fine grained recognition for both server and on-device models.
Searching for MobileNetV3
May 14, 2019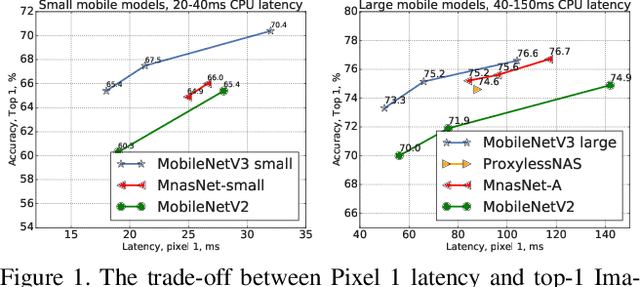
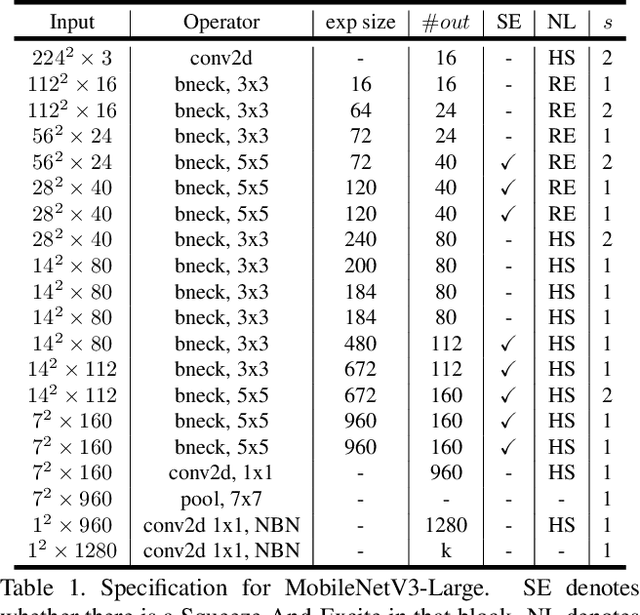
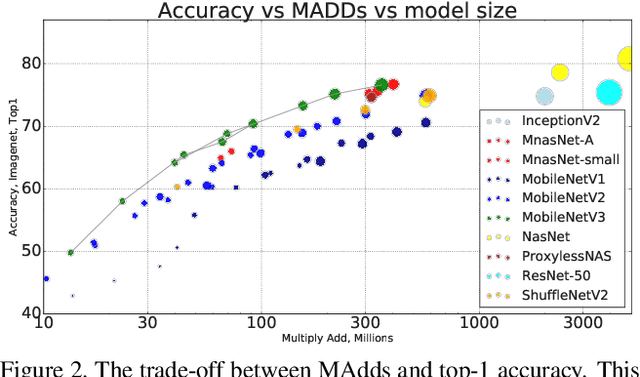
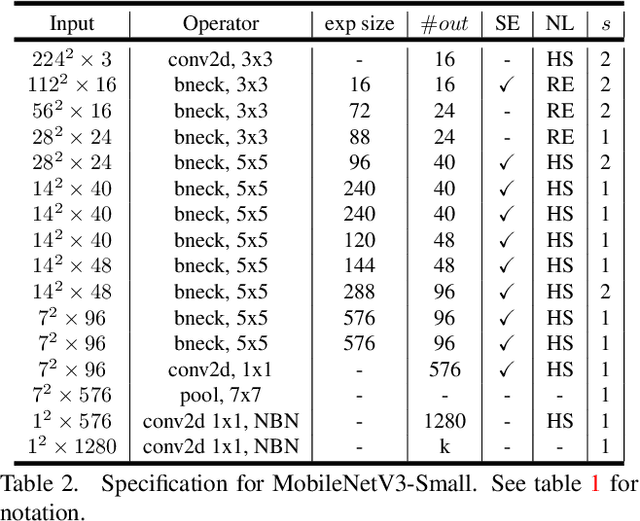
We present the next generation of MobileNets based on a combination of complementary search techniques as well as a novel architecture design. MobileNetV3 is tuned to mobile phone CPUs through a combination of hardware aware network architecture search (NAS) complemented by the NetAdapt algorithm and then subsequently improved through novel architecture advances. This paper starts the exploration of how automated search algorithms and network design can work together to harness complementary approaches improving the overall state of the art. Through this process we create two new MobileNet models for release: MobileNetV3-Large and MobileNetV3-Small which are targeted for high and low resource use cases. These models are then adapted and applied to the tasks of object detection and semantic segmentation. For the task of semantic segmentation (or any dense pixel prediction), we propose a new efficient segmentation decoder Lite Reduced Atrous Spatial Pyramid Pooling (LR-ASPP). We achieve new state of the art results for mobile classification, detection and segmentation. MobileNetV3-Large is 3.2% more accurate on ImageNet classification while reducing latency by 15% compared to MobileNetV2. MobileNetV2-Small is 4.6% more accurate while reducing latency by 5% compared to MobileNetV2. MobileNetV3-Large detection is 25% faster at roughly the same accuracy as MobileNetV2 on COCO detection. MobileNetV3-Large LR-ASPP is 30% faster than MobileNetV2 R-ASPP at similar accuracy for Cityscapes segmentation.
FEELVOS: Fast End-to-End Embedding Learning for Video Object Segmentation
Apr 08, 2019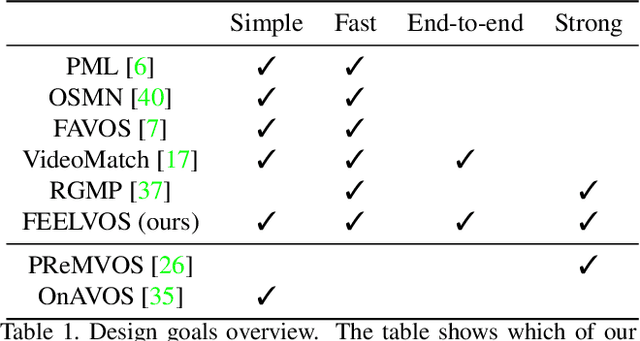
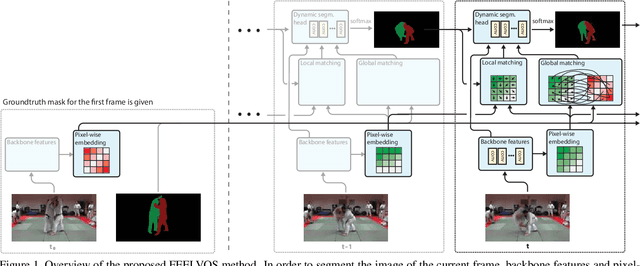
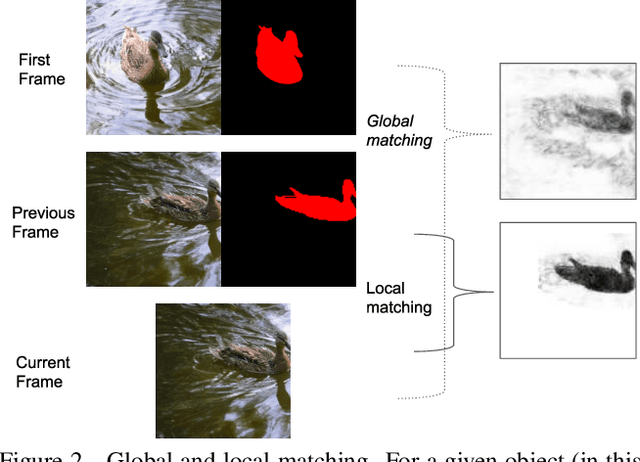
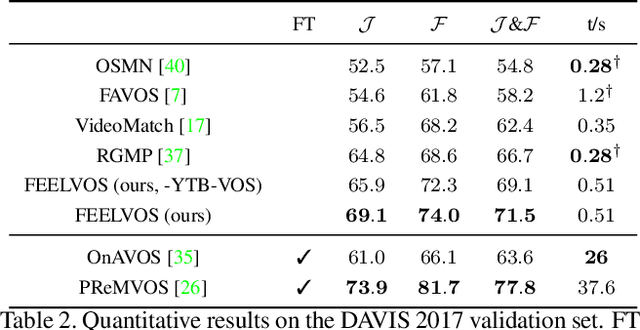
Many of the recent successful methods for video object segmentation (VOS) are overly complicated, heavily rely on fine-tuning on the first frame, and/or are slow, and are hence of limited practical use. In this work, we propose FEELVOS as a simple and fast method which does not rely on fine-tuning. In order to segment a video, for each frame FEELVOS uses a semantic pixel-wise embedding together with a global and a local matching mechanism to transfer information from the first frame and from the previous frame of the video to the current frame. In contrast to previous work, our embedding is only used as an internal guidance of a convolutional network. Our novel dynamic segmentation head allows us to train the network, including the embedding, end-to-end for the multiple object segmentation task with a cross entropy loss. We achieve a new state of the art in video object segmentation without fine-tuning with a J&F measure of 71.5% on the DAVIS 2017 validation set. We make our code and models available at https://github.com/tensorflow/models/tree/master/research/feelvos.
* CVPR 2019 camera-ready version
Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation
Jan 10, 2019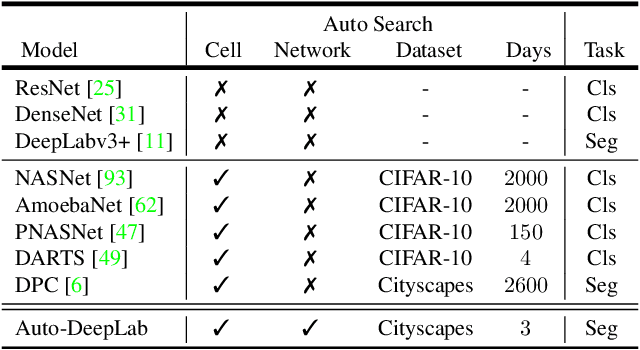
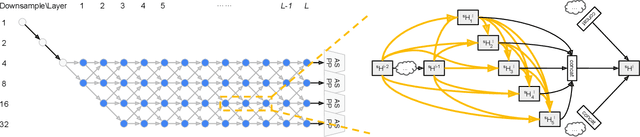
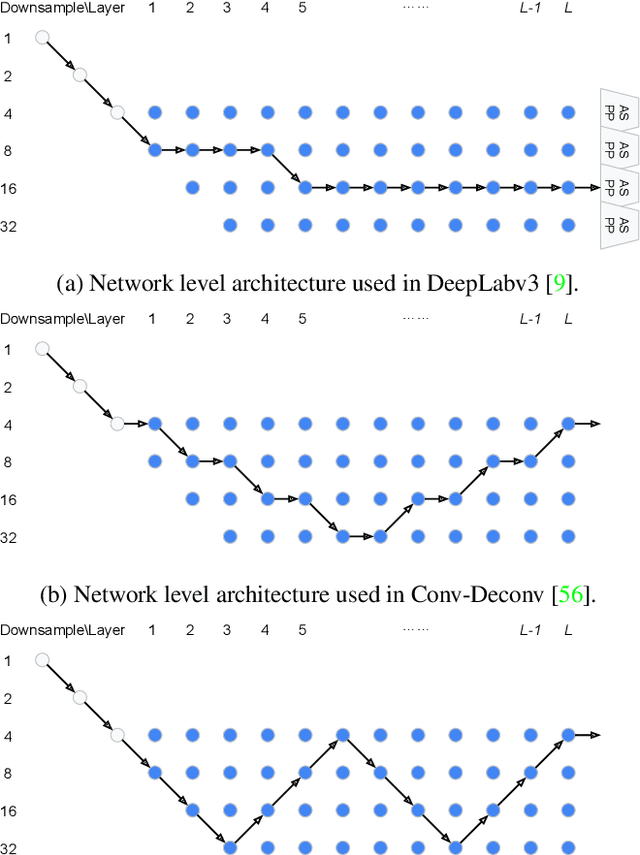
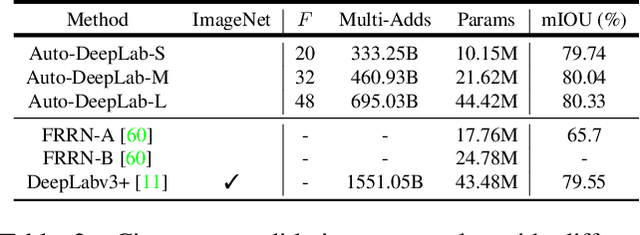
Recently, Neural Architecture Search (NAS) has successfully identified neural network architectures that exceed human designed ones on large-scale image classification problems. In this paper, we study NAS for semantic image segmentation, an important computer vision task that assigns a semantic label to every pixel in an image. Existing works often focus on searching the repeatable cell structure, while hand-designing the outer network structure that controls the spatial resolution changes. This choice simplifies the search space, but becomes increasingly problematic for dense image prediction which exhibits a lot more network level architectural variations. Therefore, we propose to search the network level structure in addition to the cell level structure, which forms a hierarchical architecture search space. We present a network level search space that includes many popular designs, and develop a formulation that allows efficient gradient-based architecture search (3 P100 GPU days on Cityscapes images). We demonstrate the effectiveness of the proposed method on the challenging Cityscapes, PASCAL VOC 2012, and ADE20K datasets. Without any ImageNet pretraining, our architecture searched specifically for semantic image segmentation attains state-of-the-art performance.
NetAdapt: Platform-Aware Neural Network Adaptation for Mobile Applications
Sep 28, 2018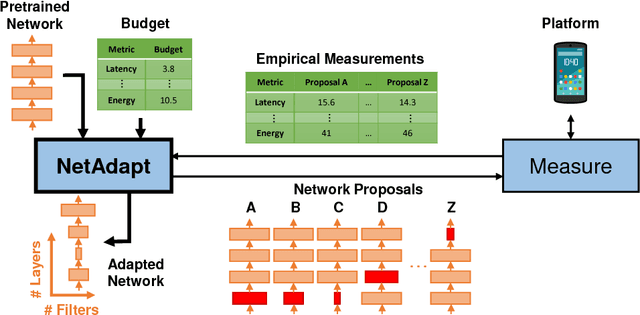
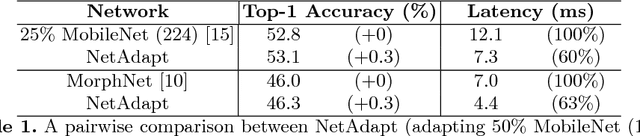
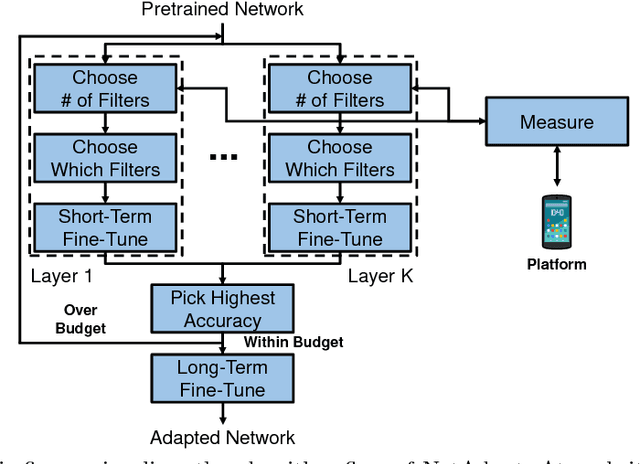
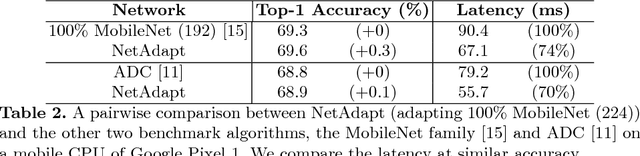
This work proposes an algorithm, called NetAdapt, that automatically adapts a pre-trained deep neural network to a mobile platform given a resource budget. While many existing algorithms simplify networks based on the number of MACs or weights, optimizing those indirect metrics may not necessarily reduce the direct metrics, such as latency and energy consumption. To solve this problem, NetAdapt incorporates direct metrics into its adaptation algorithm. These direct metrics are evaluated using empirical measurements, so that detailed knowledge of the platform and toolchain is not required. NetAdapt automatically and progressively simplifies a pre-trained network until the resource budget is met while maximizing the accuracy. Experiment results show that NetAdapt achieves better accuracy versus latency trade-offs on both mobile CPU and mobile GPU, compared with the state-of-the-art automated network simplification algorithms. For image classification on the ImageNet dataset, NetAdapt achieves up to a 1.7$\times$ speedup in measured inference latency with equal or higher accuracy on MobileNets (V1&V2).
Searching for Efficient Multi-Scale Architectures for Dense Image Prediction
Sep 11, 2018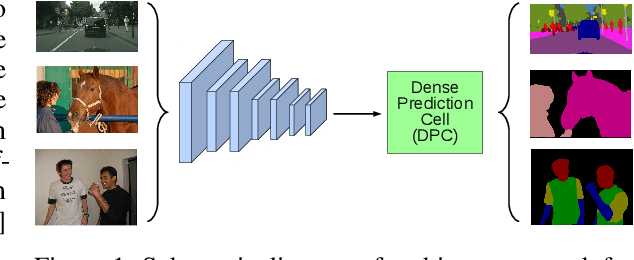
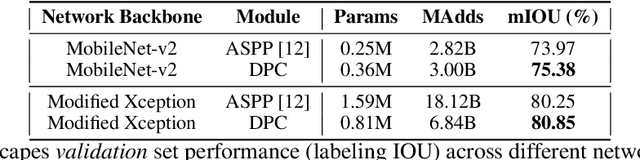
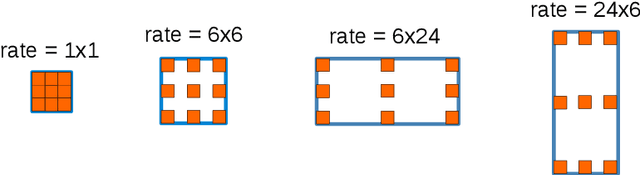
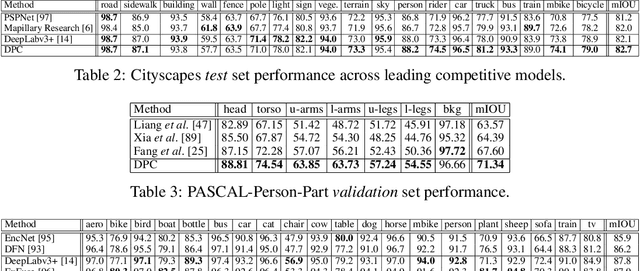
The design of neural network architectures is an important component for achieving state-of-the-art performance with machine learning systems across a broad array of tasks. Much work has endeavored to design and build architectures automatically through clever construction of a search space paired with simple learning algorithms. Recent progress has demonstrated that such meta-learning methods may exceed scalable human-invented architectures on image classification tasks. An open question is the degree to which such methods may generalize to new domains. In this work we explore the construction of meta-learning techniques for dense image prediction focused on the tasks of scene parsing, person-part segmentation, and semantic image segmentation. Constructing viable search spaces in this domain is challenging because of the multi-scale representation of visual information and the necessity to operate on high resolution imagery. Based on a survey of techniques in dense image prediction, we construct a recursive search space and demonstrate that even with efficient random search, we can identify architectures that outperform human-invented architectures and achieve state-of-the-art performance on three dense prediction tasks including 82.7\% on Cityscapes (street scene parsing), 71.3\% on PASCAL-Person-Part (person-part segmentation), and 87.9\% on PASCAL VOC 2012 (semantic image segmentation). Additionally, the resulting architecture is more computationally efficient, requiring half the parameters and half the computational cost as previous state of the art systems.