 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-SPIN: Multi-Access Speculative Inference for Cooperative Token Generation at the Edge
Jun 03, 2026Speculative inference (SPIN) was originally developed as an efficient architecture to accelerate Large Language Models (LLMs). In this work, we propose its distributed deployment to enable cooperative token generation in a multiuser edge system; its advantage is to effectively balance computational loads between resource-constrained devices and servers. The resulting architecture, termed Multi-access SPIN (Multi-SPIN), utilizes on-device small language models to generate and upload candidate token drafts, while an edge server operates the LLM to verify them in parallel batches. Given the severe heterogeneity in users' computation and communication capabilities, the draft length emerges as a critical control variable that influences node-level computation loads and multi-access latency, thereby governing the sum token goodput. Consequently, considering frequency-division multiple access, we investigate the problem of multi-access draft control, a joint optimization of draft-length control and bandwidth allocation to maximize sum token goodput. We examine two cases: (1) homogeneous draft lengths across users to facilitate server-side batching, and (2) heterogeneous draft lengths to introduce a new dimension for goodput enhancement. By developing decomposition methods, we reduce these complex optimizations into tractable sub-problems, which allow efficient draft control algorithms to be derived in closed form. Our analysis shows that the optimal bandwidth allocation compensates users with weaker computation-and-communication capabilities in the homogeneous case due to the batching synchronization requirements, whereas its heterogeneous-case counterpart rewards users with higher acceptance rates by relaxing such requirements. Experiments using Llama-2 and Qwen3.5 model pairs across diverse tasks demonstrate that Multi-SPIN improves goodput by up to 88% over heterogeneity-agnostic baselines.
Adaptive Pruning for Large Language Models with Structural Importance Awareness
Dec 19, 2024



The recent advancements in large language models (LLMs) have significantly improved language understanding and generation capabilities. However, it is difficult to deploy LLMs on resource-constrained edge devices due to their high computational and storage resource demands. To address this issue, we propose a novel LLM model pruning method, namely structurally-aware adaptive pruning (SAAP), to significantly reduce the computational and memory costs while maintaining model performance. We first define an adaptive importance fusion metric to evaluate the importance of all coupled structures in LLMs by considering their homoscedastic uncertainty. Then, we rank the importance of all modules to determine the specific layers that should be pruned to meet particular performance requirements. Furthermore, we develop a new group fine-tuning strategy to improve the inference efficiency of LLMs. Finally, we evaluate the proposed SAAP method on multiple LLMs across two common tasks, i.e., zero-shot classification and text generation. Experimental results show that our SAAP method outperforms several state-of-the-art baseline methods, achieving 2.17%, 2.37%, and 2.39% accuracy gains on LLaMA-7B, Vicuna-7B, and LLaMA-13B. Additionally, SAAP improves the token generation speed by 5%, showcasing its practical advantages in resource-constrained scenarios.
Enhancing 3D Object Detection by Using Neural Network with Self-adaptive Thresholding
May 13, 2024


Robust 3D object detection remains a pivotal concern in the domain of autonomous field robotics. Despite notable enhancements in detection accuracy across standard datasets, real-world urban environments, characterized by their unstructured and dynamic nature, frequently precipitate an elevated incidence of false positives, thereby undermining the reliability of existing detection paradigms. In this context, our study introduces an advanced post-processing algorithm that modulates detection thresholds dynamically relative to the distance from the ego object. Traditional perception systems typically utilize a uniform threshold, which often leads to decreased efficacy in detecting distant objects. In contrast, our proposed methodology employs a Neural Network with a self-adaptive thresholding mechanism that significantly attenuates false negatives while concurrently diminishing false positives, particularly in complex urban settings. Empirical results substantiate that our algorithm not only augments the performance of 3D object detection models in diverse urban and adverse weather scenarios but also establishes a new benchmark for adaptive thresholding techniques in field robotics.
Intelligent Robotic Control System Based on Computer Vision Technology
Apr 01, 2024



The article explores the intersection of computer vision technology and robotic control, highlighting its importance in various fields such as industrial automation, healthcare, and environmental protection. Computer vision technology, which simulates human visual observation, plays a crucial role in enabling robots to perceive and understand their surroundings, leading to advancements in tasks like autonomous navigation, object recognition, and waste management. By integrating computer vision with robot control, robots gain the ability to interact intelligently with their environment, improving efficiency.
Intelligent Classification and Personalized Recommendation of E-commerce Products Based on Machine Learning
Mar 28, 2024With the rapid evolution of the Internet and the exponential proliferation of information, users encounter information overload and the conundrum of choice. Personalized recommendation systems play a pivotal role in alleviating this burden by aiding users in filtering and selecting information tailored to their preferences and requirements. Such systems not only enhance user experience and satisfaction but also furnish opportunities for businesses and platforms to augment user engagement, sales, and advertising efficacy.This paper undertakes a comparative analysis between the operational mechanisms of traditional e-commerce commodity classification systems and personalized recommendation systems. It delineates the significance and application of personalized recommendation systems across e-commerce, content information, and media domains. Furthermore, it delves into the challenges confronting personalized recommendation systems in e-commerce, including data privacy, algorithmic bias, scalability, and the cold start problem. Strategies to address these challenges are elucidated.Subsequently, the paper outlines a personalized recommendation system leveraging the BERT model and nearest neighbor algorithm, specifically tailored to address the exigencies of the eBay e-commerce platform. The efficacy of this recommendation system is substantiated through manual evaluation, and a practical application operational guide and structured output recommendation results are furnished to ensure the system's operability and scalability.
MatchSeg: Towards Better Segmentation via Reference Image Matching
Mar 23, 2024



Recently, automated medical image segmentation methods based on deep learning have achieved great success. However, they heavily rely on large annotated datasets, which are costly and time-consuming to acquire. Few-shot learning aims to overcome the need for annotated data by using a small labeled dataset, known as a support set, to guide predicting labels for new, unlabeled images, known as the query set. Inspired by this paradigm, we introduce MatchSeg, a novel framework that enhances medical image segmentation through strategic reference image matching. We leverage contrastive language-image pre-training (CLIP) to select highly relevant samples when defining the support set. Additionally, we design a joint attention module to strengthen the interaction between support and query features, facilitating a more effective knowledge transfer between support and query sets. We validated our method across four public datasets. Experimental results demonstrate superior segmentation performance and powerful domain generalization ability of MatchSeg against existing methods for domain-specific and cross-domain segmentation tasks. Our code is made available at https://github.com/keeplearning-again/MatchSeg
Enhancing Multi-Hop Knowledge Graph Reasoning through Reward Shaping Techniques
Mar 09, 2024



In the realm of computational knowledge representation, Knowledge Graph Reasoning (KG-R) stands at the forefront of facilitating sophisticated inferential capabilities across multifarious domains. The quintessence of this research elucidates the employment of reinforcement learning (RL) strategies, notably the REINFORCE algorithm, to navigate the intricacies inherent in multi-hop KG-R. This investigation critically addresses the prevalent challenges introduced by the inherent incompleteness of Knowledge Graphs (KGs), which frequently results in erroneous inferential outcomes, manifesting as both false negatives and misleading positives. By partitioning the Unified Medical Language System (UMLS) benchmark dataset into rich and sparse subsets, we investigate the efficacy of pre-trained BERT embeddings and Prompt Learning methodologies to refine the reward shaping process. This approach not only enhances the precision of multi-hop KG-R but also sets a new precedent for future research in the field, aiming to improve the robustness and accuracy of knowledge inference within complex KG frameworks. Our work contributes a novel perspective to the discourse on KG reasoning, offering a methodological advancement that aligns with the academic rigor and scholarly aspirations of the Natural journal, promising to invigorate further advancements in the realm of computational knowledge representation.
A Protein Structure Prediction Approach Leveraging Transformer and CNN Integration
Mar 08, 2024



Proteins are essential for life, and their structure determines their function. The protein secondary structure is formed by the folding of the protein primary structure, and the protein tertiary structure is formed by the bending and folding of the secondary structure. Therefore, the study of protein secondary structure is very helpful to the overall understanding of protein structure. Although the accuracy of protein secondary structure prediction has continuously improved with the development of machine learning and deep learning, progress in the field of protein structure prediction, unfortunately, remains insufficient to meet the large demand for protein information. Therefore, based on the advantages of deep learning-based methods in feature extraction and learning ability, this paper adopts a two-dimensional fusion deep neural network model, DstruCCN, which uses Convolutional Neural Networks (CCN) and a supervised Transformer protein language model for single-sequence protein structure prediction. The training features of the two are combined to predict the protein Transformer binding site matrix, and then the three-dimensional structure is reconstructed using energy minimization.
Out-of-distribution Detection Learning with Unreliable Out-of-distribution Sources
Nov 06, 2023Out-of-distribution (OOD) detection discerns OOD data where the predictor cannot make valid predictions as in-distribution (ID) data, thereby increasing the reliability of open-world classification. However, it is typically hard to collect real out-of-distribution (OOD) data for training a predictor capable of discerning ID and OOD patterns. This obstacle gives rise to data generation-based learning methods, synthesizing OOD data via data generators for predictor training without requiring any real OOD data. Related methods typically pre-train a generator on ID data and adopt various selection procedures to find those data likely to be the OOD cases. However, generated data may still coincide with ID semantics, i.e., mistaken OOD generation remains, confusing the predictor between ID and OOD data. To this end, we suggest that generated data (with mistaken OOD generation) can be used to devise an auxiliary OOD detection task to facilitate real OOD detection. Specifically, we can ensure that learning from such an auxiliary task is beneficial if the ID and the OOD parts have disjoint supports, with the help of a well-designed training procedure for the predictor. Accordingly, we propose a powerful data generation-based learning method named Auxiliary Task-based OOD Learning (ATOL) that can relieve the mistaken OOD generation. We conduct extensive experiments under various OOD detection setups, demonstrating the effectiveness of our method against its advanced counterparts.
Synthesize Efficient Safety Certificates for Learning-Based Safe Control using Magnitude Regularization
Sep 23, 2022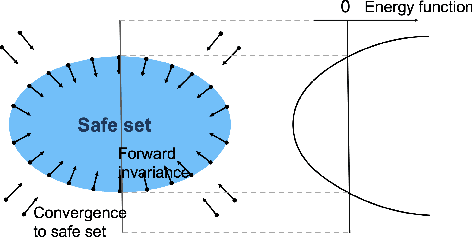
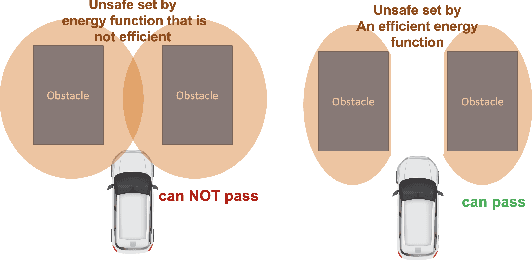
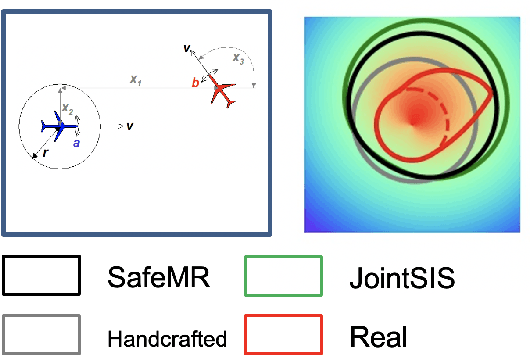

Energy-function-based safety certificates can provide provable safety guarantees for the safe control tasks of complex robotic systems. However, all recent studies about learning-based energy function synthesis only consider the feasibility, which might cause over-conservativeness and result in less efficient controllers. In this work, we proposed the magnitude regularization technique to improve the efficiency of safe controllers by reducing the conservativeness inside the energy function while keeping the promising provable safety guarantees. Specifically, we quantify the conservativeness by the magnitude of the energy function, and we reduce the conservativeness by adding a magnitude regularization term to the synthesis loss. We propose the SafeMR algorithm that uses reinforcement learning (RL) for the synthesis to unify the learning processes of safe controllers and energy functions. Experimental results show that the proposed method does reduce the conservativeness of the energy functions and outperforms the baselines in terms of the controller efficiency while guaranteeing safety.