 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLARGO: Low-Rank Regulated Gradient Projection for Robust Parameter Efficient Fine-Tuning
Jun 14, 2025



The advent of parameter-efficient fine-tuning methods has significantly reduced the computational burden of adapting large-scale pretrained models to diverse downstream tasks. However, existing approaches often struggle to achieve robust performance under domain shifts while maintaining computational efficiency. To address this challenge, we propose Low-rAnk Regulated Gradient Projection (LARGO) algorithm that integrates dynamic constraints into low-rank adaptation methods. Specifically, LARGO incorporates parallel trainable gradient projections to dynamically regulate layer-wise updates, retaining the Out-Of-Distribution robustness of pretrained model while preserving inter-layer independence. Additionally, it ensures computational efficiency by mitigating the influence of gradient dependencies across layers during weight updates. Besides, through leveraging singular value decomposition of pretrained weights for structured initialization, we incorporate an SVD-based initialization strategy that minimizing deviation from pretrained knowledge. Through extensive experiments on diverse benchmarks, LARGO achieves state-of-the-art performance across in-domain and out-of-distribution scenarios, demonstrating improved robustness under domain shifts with significantly lower computational overhead compared to existing PEFT methods. The source code will be released soon.
Synesthesia of Machines (SoM)-Aided Online FDD Precoding via Heterogeneous Multi-Modal Sensing: A Vertical Federated Learning Approach
Jun 09, 2025This paper investigates a heterogeneous multi-vehicle, multi-modal sensing (H-MVMM) aided online precoding problem. The proposed H-MVMM scheme utilizes a vertical federated learning (VFL) framework to minimize pilot sequence length and optimize the sum rate. This offers a promising solution for reducing latency in frequency division duplexing systems. To achieve this, three preprocessing modules are designed to transform raw sensory data into informative representations relevant to precoding. The approach effectively addresses local data heterogeneity arising from diverse on-board sensor configurations through a well-structured VFL training procedure. Additionally, a label-free online model updating strategy is introduced, enabling the H-MVMM scheme to adapt its weights flexibly. This strategy features a pseudo downlink channel state information label simulator (PCSI-Simulator), which is trained using a semi-supervised learning (SSL) approach alongside an online loss function. Numerical results show that the proposed method can closely approximate the performance of traditional optimization techniques with perfect channel state information, achieving a significant 90.6\% reduction in pilot sequence length.
SIGMA: Refining Large Language Model Reasoning via Sibling-Guided Monte Carlo Augmentation
Jun 06, 2025



Enhancing large language models by simply scaling up datasets has begun to yield diminishing returns, shifting the spotlight to data quality. Monte Carlo Tree Search (MCTS) has emerged as a powerful technique for generating high-quality chain-of-thought data, yet conventional approaches typically retain only the top-scoring trajectory from the search tree, discarding sibling nodes that often contain valuable partial insights, recurrent error patterns, and alternative reasoning strategies. This unconditional rejection of non-optimal reasoning branches may waste vast amounts of informative data in the whole search tree. We propose SIGMA (Sibling Guided Monte Carlo Augmentation), a novel framework that reintegrates these discarded sibling nodes to refine LLM reasoning. SIGMA forges semantic links among sibling nodes along each search path and applies a two-stage refinement: a critique model identifies overlooked strengths and weaknesses across the sibling set, and a revision model conducts text-based backpropagation to refine the top-scoring trajectory in light of this comparative feedback. By recovering and amplifying the underutilized but valuable signals from non-optimal reasoning branches, SIGMA substantially improves reasoning trajectories. On the challenging MATH benchmark, our SIGMA-tuned 7B model achieves 54.92% accuracy using only 30K samples, outperforming state-of-the-art models trained on 590K samples. This result highlights that our sibling-guided optimization not only significantly reduces data usage but also significantly boosts LLM reasoning.
Rendering-Aware Reinforcement Learning for Vector Graphics Generation
May 27, 2025



Scalable Vector Graphics (SVG) offer a powerful format for representing visual designs as interpretable code. Recent advances in vision-language models (VLMs) have enabled high-quality SVG generation by framing the problem as a code generation task and leveraging large-scale pretraining. VLMs are particularly suitable for this task as they capture both global semantics and fine-grained visual patterns, while transferring knowledge across vision, natural language, and code domains. However, existing VLM approaches often struggle to produce faithful and efficient SVGs because they never observe the rendered images during training. Although differentiable rendering for autoregressive SVG code generation remains unavailable, rendered outputs can still be compared to original inputs, enabling evaluative feedback suitable for reinforcement learning (RL). We introduce RLRF(Reinforcement Learning from Rendering Feedback), an RL method that enhances SVG generation in autoregressive VLMs by leveraging feedback from rendered SVG outputs. Given an input image, the model generates SVG roll-outs that are rendered and compared to the original image to compute a reward. This visual fidelity feedback guides the model toward producing more accurate, efficient, and semantically coherent SVGs. RLRF significantly outperforms supervised fine-tuning, addressing common failure modes and enabling precise, high-quality SVG generation with strong structural understanding and generalization.
GENMO: A GENeralist Model for Human MOtion
May 02, 2025



Human motion modeling traditionally separates motion generation and estimation into distinct tasks with specialized models. Motion generation models focus on creating diverse, realistic motions from inputs like text, audio, or keyframes, while motion estimation models aim to reconstruct accurate motion trajectories from observations like videos. Despite sharing underlying representations of temporal dynamics and kinematics, this separation limits knowledge transfer between tasks and requires maintaining separate models. We present GENMO, a unified Generalist Model for Human Motion that bridges motion estimation and generation in a single framework. Our key insight is to reformulate motion estimation as constrained motion generation, where the output motion must precisely satisfy observed conditioning signals. Leveraging the synergy between regression and diffusion, GENMO achieves accurate global motion estimation while enabling diverse motion generation. We also introduce an estimation-guided training objective that exploits in-the-wild videos with 2D annotations and text descriptions to enhance generative diversity. Furthermore, our novel architecture handles variable-length motions and mixed multimodal conditions (text, audio, video) at different time intervals, offering flexible control. This unified approach creates synergistic benefits: generative priors improve estimated motions under challenging conditions like occlusions, while diverse video data enhances generation capabilities. Extensive experiments demonstrate GENMO's effectiveness as a generalist framework that successfully handles multiple human motion tasks within a single model.
The Fourth Monocular Depth Estimation Challenge
Apr 24, 2025
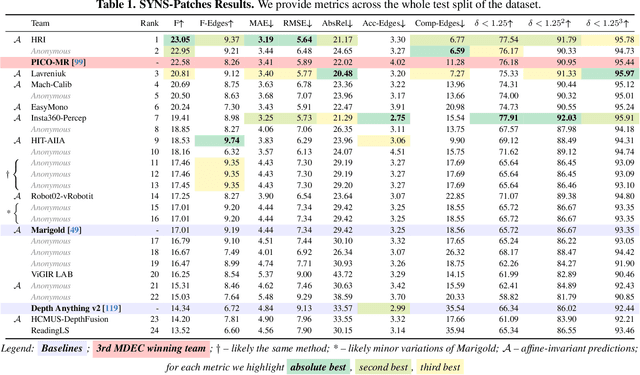
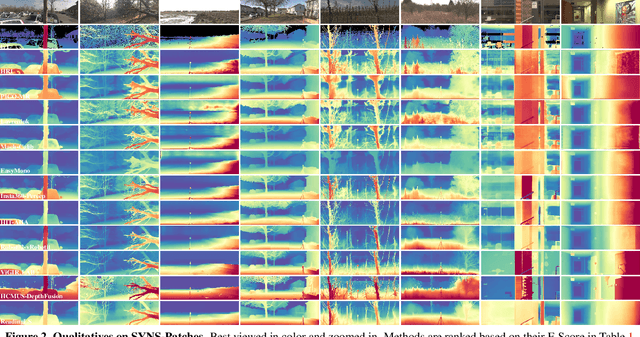
This paper presents the results of the fourth edition of the Monocular Depth Estimation Challenge (MDEC), which focuses on zero-shot generalization to the SYNS-Patches benchmark, a dataset featuring challenging environments in both natural and indoor settings. In this edition, we revised the evaluation protocol to use least-squares alignment with two degrees of freedom to support disparity and affine-invariant predictions. We also revised the baselines and included popular off-the-shelf methods: Depth Anything v2 and Marigold. The challenge received a total of 24 submissions that outperformed the baselines on the test set; 10 of these included a report describing their approach, with most leading methods relying on affine-invariant predictions. The challenge winners improved the 3D F-Score over the previous edition's best result, raising it from 22.58% to 23.05%.
SRPO: A Cross-Domain Implementation of Large-Scale Reinforcement Learning on LLM
Apr 22, 2025



Recent advances of reasoning models, exemplified by OpenAI's o1 and DeepSeek's R1, highlight the significant potential of Reinforcement Learning (RL) to enhance the reasoning capabilities of Large Language Models (LLMs). However, replicating these advancements across diverse domains remains challenging due to limited methodological transparency. In this work, we present two-Staged history-Resampling Policy Optimization (SRPO), which surpasses the performance of DeepSeek-R1-Zero-32B on the AIME24 and LiveCodeBench benchmarks. SRPO achieves this using the same base model as DeepSeek (i.e. Qwen2.5-32B), using only about 1/10 of the training steps required by DeepSeek-R1-Zero-32B, demonstrating superior efficiency. Building upon Group Relative Policy Optimization (GRPO), we introduce two key methodological innovations: (1) a two-stage cross-domain training paradigm designed to balance the development of mathematical reasoning and coding proficiency, and (2) History Resampling (HR), a technique to address ineffective samples. Our comprehensive experiments validate the effectiveness of our approach, offering valuable insights into scaling LLM reasoning capabilities across diverse tasks.
OASIS: Order-Augmented Strategy for Improved Code Search
Mar 11, 2025



Code embeddings capture the semantic representations of code and are crucial for various code-related large language model (LLM) applications, such as code search. Previous training primarily relies on optimizing the InfoNCE loss by comparing positive natural language (NL)-code pairs with in-batch negatives. However, due to the sparse nature of code contexts, training solely by comparing the major differences between positive and negative pairs may fail to capture deeper semantic nuances. To address this issue, we propose a novel order-augmented strategy for improved code search (OASIS). It leverages order-based similarity labels to train models to capture subtle differences in similarity among negative pairs. Extensive benchmark evaluations demonstrate that our OASIS model significantly outperforms previous state-of-the-art models focusing solely on major positive-negative differences. It underscores the value of exploiting subtle differences among negative pairs with order labels for effective code embedding training.
Grammar-Based Code Representation: Is It a Worthy Pursuit for LLMs?
Mar 07, 2025



Grammar serves as a cornerstone in programming languages and software engineering, providing frameworks to define the syntactic space and program structure. Existing research demonstrates the effectiveness of grammar-based code representations in small-scale models, showing their ability to reduce syntax errors and enhance performance. However, as language models scale to the billion level or beyond, syntax-level errors become rare, making it unclear whether grammar information still provides performance benefits. To explore this, we develop a series of billion-scale GrammarCoder models, incorporating grammar rules in the code generation process. Experiments on HumanEval (+) and MBPP (+) demonstrate a notable improvement in code generation accuracy. Further analysis shows that grammar-based representations enhance LLMs' ability to discern subtle code differences, reducing semantic errors caused by minor variations. These findings suggest that grammar-based code representations remain valuable even in billion-scale models, not only by maintaining syntax correctness but also by improving semantic differentiation.
MathMistake Checker: A Comprehensive Demonstration for Step-by-Step Math Problem Mistake Finding by Prompt-Guided LLMs
Mar 06, 2025We propose a novel system, MathMistake Checker, designed to automate step-by-step mistake finding in mathematical problems with lengthy answers through a two-stage process. The system aims to simplify grading, increase efficiency, and enhance learning experiences from a pedagogical perspective. It integrates advanced technologies, including computer vision and the chain-of-thought capabilities of the latest large language models (LLMs). Our system supports open-ended grading without reference answers and promotes personalized learning by providing targeted feedback. We demonstrate its effectiveness across various types of math problems, such as calculation and word problems.