 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCUA-Suite: Massive Human-annotated Video Demonstrations for Computer-Use Agents
Mar 25, 2026Computer-use agents (CUAs) hold great promise for automating complex desktop workflows, yet progress toward general-purpose agents is bottlenecked by the scarcity of continuous, high-quality human demonstration videos. Recent work emphasizes that continuous video, not sparse screenshots, is the critical missing ingredient for scaling these agents. However, the largest existing open dataset, ScaleCUA, contains only 2 million screenshots, equating to less than 20 hours of video. To address this bottleneck, we introduce CUA-Suite, a large-scale ecosystem of expert video demonstrations and dense annotations for professional desktop computer-use agents. At its core is VideoCUA, which provides approximately 10,000 human-demonstrated tasks across 87 diverse applications with continuous 30 fps screen recordings, kinematic cursor traces, and multi-layerfed reasoning annotations, totaling approximately 55 hours and 6 million frames of expert video. Unlike sparse datasets that capture only final click coordinates, these continuous video streams preserve the full temporal dynamics of human interaction, forming a superset of information that can be losslessly transformed into the formats required by existing agent frameworks. CUA-Suite further provides two complementary resources: UI-Vision, a rigorous benchmark for evaluating grounding and planning capabilities in CUAs, and GroundCUA, a large-scale grounding dataset with 56K annotated screenshots and over 3.6 million UI element annotations. Preliminary evaluation reveals that current foundation action models struggle substantially with professional desktop applications (~60% task failure rate). Beyond evaluation, CUA-Suite's rich multimodal corpus supports emerging research directions including generalist screen parsing, continuous spatial control, video-based reward modeling, and visual world models. All data and models are publicly released.
Grounding Computer Use Agents on Human Demonstrations
Nov 10, 2025



Building reliable computer-use agents requires grounding: accurately connecting natural language instructions to the correct on-screen elements. While large datasets exist for web and mobile interactions, high-quality resources for desktop environments are limited. To address this gap, we introduce GroundCUA, a large-scale desktop grounding dataset built from expert human demonstrations. It covers 87 applications across 12 categories and includes 56K screenshots, with every on-screen element carefully annotated for a total of over 3.56M human-verified annotations. From these demonstrations, we generate diverse instructions that capture a wide range of real-world tasks, providing high-quality data for model training. Using GroundCUA, we develop the GroundNext family of models that map instructions to their target UI elements. At both 3B and 7B scales, GroundNext achieves state-of-the-art results across five benchmarks using supervised fine-tuning, while requiring less than one-tenth the training data of prior work. Reinforcement learning post-training further improves performance, and when evaluated in an agentic setting on the OSWorld benchmark using o3 as planner, GroundNext attains comparable or superior results to models trained with substantially more data,. These results demonstrate the critical role of high-quality, expert-driven datasets in advancing general-purpose computer-use agents.
Rendering-Aware Reinforcement Learning for Vector Graphics Generation
May 27, 2025



Scalable Vector Graphics (SVG) offer a powerful format for representing visual designs as interpretable code. Recent advances in vision-language models (VLMs) have enabled high-quality SVG generation by framing the problem as a code generation task and leveraging large-scale pretraining. VLMs are particularly suitable for this task as they capture both global semantics and fine-grained visual patterns, while transferring knowledge across vision, natural language, and code domains. However, existing VLM approaches often struggle to produce faithful and efficient SVGs because they never observe the rendered images during training. Although differentiable rendering for autoregressive SVG code generation remains unavailable, rendered outputs can still be compared to original inputs, enabling evaluative feedback suitable for reinforcement learning (RL). We introduce RLRF(Reinforcement Learning from Rendering Feedback), an RL method that enhances SVG generation in autoregressive VLMs by leveraging feedback from rendered SVG outputs. Given an input image, the model generates SVG roll-outs that are rendered and compared to the original image to compute a reward. This visual fidelity feedback guides the model toward producing more accurate, efficient, and semantically coherent SVGs. RLRF significantly outperforms supervised fine-tuning, addressing common failure modes and enabling precise, high-quality SVG generation with strong structural understanding and generalization.
PairBench: A Systematic Framework for Selecting Reliable Judge VLMs
Feb 21, 2025As large vision language models (VLMs) are increasingly used as automated evaluators, understanding their ability to effectively compare data pairs as instructed in the prompt becomes essential. To address this, we present PairBench, a low-cost framework that systematically evaluates VLMs as customizable similarity tools across various modalities and scenarios. Through PairBench, we introduce four metrics that represent key desiderata of similarity scores: alignment with human annotations, consistency for data pairs irrespective of their order, smoothness of similarity distributions, and controllability through prompting. Our analysis demonstrates that no model, whether closed- or open-source, is superior on all metrics; the optimal choice depends on an auto evaluator's desired behavior (e.g., a smooth vs. a sharp judge), highlighting risks of widespread adoption of VLMs as evaluators without thorough assessment. For instance, the majority of VLMs struggle with maintaining symmetric similarity scores regardless of order. Additionally, our results show that the performance of VLMs on the metrics in PairBench closely correlates with popular benchmarks, showcasing its predictive power in ranking models.
AlignVLM: Bridging Vision and Language Latent Spaces for Multimodal Understanding
Feb 03, 2025



Aligning visual features with language embeddings is a key challenge in vision-language models (VLMs). The performance of such models hinges on having a good connector that maps visual features generated by a vision encoder to a shared embedding space with the LLM while preserving semantic similarity. Existing connectors, such as multilayer perceptrons (MLPs), often produce out-of-distribution or noisy inputs, leading to misalignment between the modalities. In this work, we propose a novel vision-text alignment method, AlignVLM, that maps visual features to a weighted average of LLM text embeddings. Our approach leverages the linguistic priors encoded by the LLM to ensure that visual features are mapped to regions of the space that the LLM can effectively interpret. AlignVLM is particularly effective for document understanding tasks, where scanned document images must be accurately mapped to their textual content. Our extensive experiments show that AlignVLM achieves state-of-the-art performance compared to prior alignment methods. We provide further analysis demonstrating improved vision-text feature alignment and robustness to noise.
BigDocs: An Open and Permissively-Licensed Dataset for Training Multimodal Models on Document and Code Tasks
Dec 05, 2024



Multimodal AI has the potential to significantly enhance document-understanding tasks, such as processing receipts, understanding workflows, extracting data from documents, and summarizing reports. Code generation tasks that require long-structured outputs can also be enhanced by multimodality. Despite this, their use in commercial applications is often limited due to limited access to training data and restrictive licensing, which hinders open access. To address these limitations, we introduce BigDocs-7.5M, a high-quality, open-access dataset comprising 7.5 million multimodal documents across 30 tasks. We use an efficient data curation process to ensure our data is high-quality and license-permissive. Our process emphasizes accountability, responsibility, and transparency through filtering rules, traceable metadata, and careful content analysis. Additionally, we introduce BigDocs-Bench, a benchmark suite with 10 novel tasks where we create datasets that reflect real-world use cases involving reasoning over Graphical User Interfaces (GUI) and code generation from images. Our experiments show that training with BigDocs-Bench improves average performance up to 25.8% over closed-source GPT-4o in document reasoning and structured output tasks such as Screenshot2HTML or Image2Latex generation. Finally, human evaluations showed a preference for outputs from models trained on BigDocs over GPT-4o. This suggests that BigDocs can help both academics and the open-source community utilize and improve AI tools to enhance multimodal capabilities and document reasoning. The project is hosted at https://bigdocs.github.io .
FairLoRA: Unpacking Bias Mitigation in Vision Models with Fairness-Driven Low-Rank Adaptation
Oct 22, 2024



Recent advances in parameter-efficient fine-tuning methods, such as Low Rank Adaptation (LoRA), have gained significant attention for their ability to efficiently adapt large foundational models to various downstream tasks. These methods are appreciated for achieving performance comparable to full fine-tuning on aggregate-level metrics, while significantly reducing computational costs. To systematically address fairness in LLMs previous studies fine-tune on fairness specific data using a larger LoRA rank than typically used. In this paper, we introduce FairLoRA, a novel fairness-specific regularizer for LoRA aimed at reducing performance disparities across data subgroups by minimizing per-class variance in loss. To the best of our knowledge, we are the first to introduce a fairness based finetuning through LoRA. Our results demonstrate that the need for higher ranks to mitigate bias is not universal; it depends on factors such as the pre-trained model, dataset, and task. More importantly, we systematically evaluate FairLoRA across various vision models, including ViT, DiNO, and CLIP, in scenarios involving distribution shifts. We further emphasize the necessity of using multiple fairness metrics to obtain a holistic assessment of fairness, rather than relying solely on the metric optimized during training.
GPS-SSL: Guided Positive Sampling to Inject Prior Into Self-Supervised Learning
Jan 09, 2024We propose Guided Positive Sampling Self-Supervised Learning (GPS-SSL), a general method to inject a priori knowledge into Self-Supervised Learning (SSL) positive samples selection. Current SSL methods leverage Data-Augmentations (DA) for generating positive samples and incorporate prior knowledge - an incorrect, or too weak DA will drastically reduce the quality of the learned representation. GPS-SSL proposes instead to design a metric space where Euclidean distances become a meaningful proxy for semantic relationship. In that space, it is now possible to generate positive samples from nearest neighbor sampling. Any prior knowledge can now be embedded into that metric space independently from the employed DA. From its simplicity, GPS-SSL is applicable to any SSL method, e.g. SimCLR or BYOL. A key benefit of GPS-SSL is in reducing the pressure in tailoring strong DAs. For example GPS-SSL reaches 85.58% on Cifar10 with weak DA while the baseline only reaches 37.51%. We therefore move a step forward towards the goal of making SSL less reliant on DA. We also show that even when using strong DAs, GPS-SSL outperforms the baselines on under-studied domains. We evaluate GPS-SSL along with multiple baseline SSL methods on numerous downstream datasets from different domains when the models use strong or minimal data augmentations. We hope that GPS-SSL will open new avenues in studying how to inject a priori knowledge into SSL in a principled manner.
Party Prediction for Twitter
Aug 25, 2023



A large number of studies on social media compare the behaviour of users from different political parties. As a basic step, they employ a predictive model for inferring their political affiliation. The accuracy of this model can change the conclusions of a downstream analysis significantly, yet the choice between different models seems to be made arbitrarily. In this paper, we provide a comprehensive survey and an empirical comparison of the current party prediction practices and propose several new approaches which are competitive with or outperform state-of-the-art methods, yet require less computational resources. Party prediction models rely on the content generated by the users (e.g., tweet texts), the relations they have (e.g., who they follow), or their activities and interactions (e.g., which tweets they like). We examine all of these and compare their signal strength for the party prediction task. This paper lets the practitioner select from a wide range of data types that all give strong performance. Finally, we conduct extensive experiments on different aspects of these methods, such as data collection speed and transfer capabilities, which can provide further insights for both applied and methodological research.
Revisiting Hotels-50K and Hotel-ID
Jul 20, 2022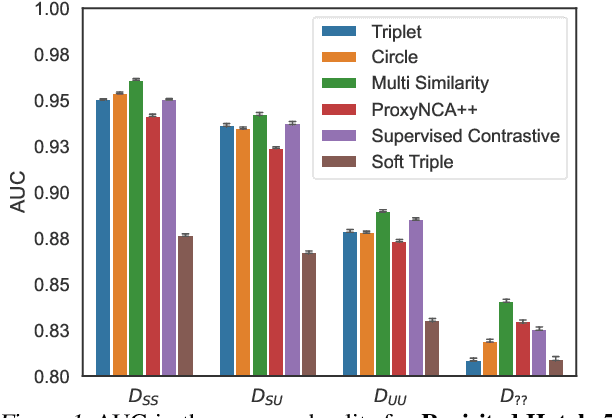
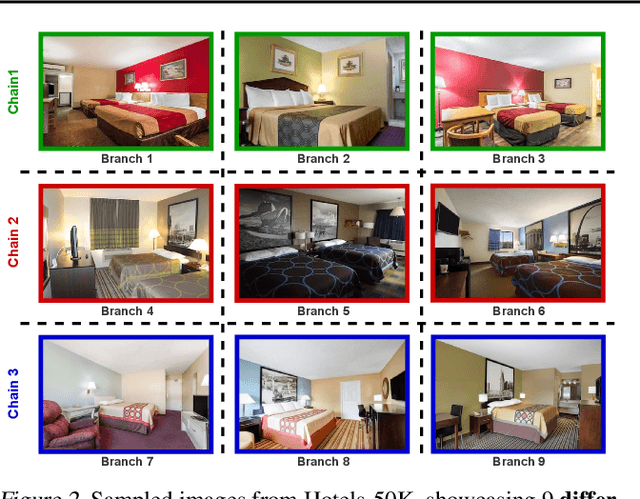
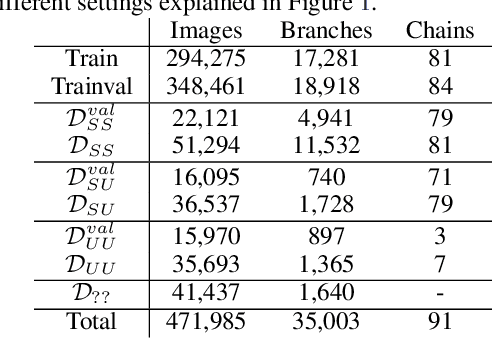
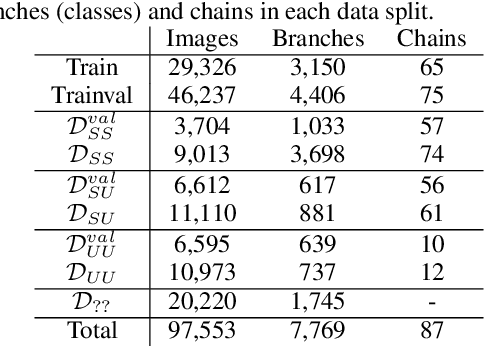
In this paper, we propose revisited versions for two recent hotel recognition datasets: Hotels50K and Hotel-ID. The revisited versions provide evaluation setups with different levels of difficulty to better align with the intended real-world application, i.e. countering human trafficking. Real-world scenarios involve hotels and locations that are not captured in the current data sets, therefore it is important to consider evaluation settings where classes are truly unseen. We test this setup using multiple state-of-the-art image retrieval models and show that as expected, the models' performances decrease as the evaluation gets closer to the real-world unseen settings. The rankings of the best performing models also change across the different evaluation settings, which further motivates using the proposed revisited datasets.