 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMURF-THP: Score Matching-based UnceRtainty quantiFication for Transformer Hawkes Process
Oct 25, 2023



Transformer Hawkes process models have shown to be successful in modeling event sequence data. However, most of the existing training methods rely on maximizing the likelihood of event sequences, which involves calculating some intractable integral. Moreover, the existing methods fail to provide uncertainty quantification for model predictions, e.g., confidence intervals for the predicted event's arrival time. To address these issues, we propose SMURF-THP, a score-based method for learning Transformer Hawkes process and quantifying prediction uncertainty. Specifically, SMURF-THP learns the score function of events' arrival time based on a score-matching objective that avoids the intractable computation. With such a learned score function, we can sample arrival time of events from the predictive distribution. This naturally allows for the quantification of uncertainty by computing confidence intervals over the generated samples. We conduct extensive experiments in both event type prediction and uncertainty quantification of arrival time. In all the experiments, SMURF-THP outperforms existing likelihood-based methods in confidence calibration while exhibiting comparable prediction accuracy.
Situated Natural Language Explanations
Aug 27, 2023



Natural language is among the most accessible tools for explaining decisions to humans, and large pretrained language models (PLMs) have demonstrated impressive abilities to generate coherent natural language explanations (NLE). The existing NLE research perspectives do not take the audience into account. An NLE can have high textual quality, but it might not accommodate audiences' needs and preference. To address this limitation, we propose an alternative perspective, situated NLE, including a situated generation framework and a situated evaluation framework. On the generation side, we propose simple prompt engineering methods that adapt the NLEs to situations. In human studies, the annotators preferred the situated NLEs. On the evaluation side, we set up automated evaluation scores in lexical, semantic, and pragmatic categories. The scores can be used to select the most suitable prompts to generate NLEs. Situated NLE provides a perspective to conduct further research on automatic NLE generations.
Amazon-M2: A Multilingual Multi-locale Shopping Session Dataset for Recommendation and Text Generation
Jul 19, 2023



Modeling customer shopping intentions is a crucial task for e-commerce, as it directly impacts user experience and engagement. Thus, accurately understanding customer preferences is essential for providing personalized recommendations. Session-based recommendation, which utilizes customer session data to predict their next interaction, has become increasingly popular. However, existing session datasets have limitations in terms of item attributes, user diversity, and dataset scale. As a result, they cannot comprehensively capture the spectrum of user behaviors and preferences. To bridge this gap, we present the Amazon Multilingual Multi-locale Shopping Session Dataset, namely Amazon-M2. It is the first multilingual dataset consisting of millions of user sessions from six different locales, where the major languages of products are English, German, Japanese, French, Italian, and Spanish. Remarkably, the dataset can help us enhance personalization and understanding of user preferences, which can benefit various existing tasks as well as enable new tasks. To test the potential of the dataset, we introduce three tasks in this work: (1) next-product recommendation, (2) next-product recommendation with domain shifts, and (3) next-product title generation. With the above tasks, we benchmark a range of algorithms on our proposed dataset, drawing new insights for further research and practice. In addition, based on the proposed dataset and tasks, we hosted a competition in the KDD CUP 2023 and have attracted thousands of users and submissions. The winning solutions and the associated workshop can be accessed at our website https://kddcup23.github.io/.
Graph Reasoning for Question Answering with Triplet Retrieval
May 30, 2023



Answering complex questions often requires reasoning over knowledge graphs (KGs). State-of-the-art methods often utilize entities in questions to retrieve local subgraphs, which are then fed into KG encoder, e.g. graph neural networks (GNNs), to model their local structures and integrated into language models for question answering. However, this paradigm constrains retrieved knowledge in local subgraphs and discards more diverse triplets buried in KGs that are disconnected but useful for question answering. In this paper, we propose a simple yet effective method to first retrieve the most relevant triplets from KGs and then rerank them, which are then concatenated with questions to be fed into language models. Extensive results on both CommonsenseQA and OpenbookQA datasets show that our method can outperform state-of-the-art up to 4.6% absolute accuracy.
CCGen: Explainable Complementary Concept Generation in E-Commerce
May 19, 2023We propose and study Complementary Concept Generation (CCGen): given a concept of interest, e.g., "Digital Cameras", generating a list of complementary concepts, e.g., 1) Camera Lenses 2) Batteries 3) Camera Cases 4) Memory Cards 5) Battery Chargers. CCGen is beneficial for various applications like query suggestion and item recommendation, especially in the e-commerce domain. To solve CCGen, we propose to train language models to generate ranked lists of concepts with a two-step training strategy. We also teach the models to generate explanations by incorporating explanations distilled from large teacher models. Extensive experiments and analysis demonstrate that our model can generate high-quality concepts complementary to the input concept while producing explanations to justify the predictions.
Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond
Apr 27, 2023This paper presents a comprehensive and practical guide for practitioners and end-users working with Large Language Models (LLMs) in their downstream natural language processing (NLP) tasks. We provide discussions and insights into the usage of LLMs from the perspectives of models, data, and downstream tasks. Firstly, we offer an introduction and brief summary of current GPT- and BERT-style LLMs. Then, we discuss the influence of pre-training data, training data, and test data. Most importantly, we provide a detailed discussion about the use and non-use cases of large language models for various natural language processing tasks, such as knowledge-intensive tasks, traditional natural language understanding tasks, natural language generation tasks, emergent abilities, and considerations for specific tasks.We present various use cases and non-use cases to illustrate the practical applications and limitations of LLMs in real-world scenarios. We also try to understand the importance of data and the specific challenges associated with each NLP task. Furthermore, we explore the impact of spurious biases on LLMs and delve into other essential considerations, such as efficiency, cost, and latency, to ensure a comprehensive understanding of deploying LLMs in practice. This comprehensive guide aims to provide researchers and practitioners with valuable insights and best practices for working with LLMs, thereby enabling the successful implementation of these models in a wide range of NLP tasks. A curated list of practical guide resources of LLMs, regularly updated, can be found at \url{https://github.com/Mooler0410/LLMsPracticalGuide}.
HomoDistil: Homotopic Task-Agnostic Distillation of Pre-trained Transformers
Feb 19, 2023Knowledge distillation has been shown to be a powerful model compression approach to facilitate the deployment of pre-trained language models in practice. This paper focuses on task-agnostic distillation. It produces a compact pre-trained model that can be easily fine-tuned on various tasks with small computational costs and memory footprints. Despite the practical benefits, task-agnostic distillation is challenging. Since the teacher model has a significantly larger capacity and stronger representation power than the student model, it is very difficult for the student to produce predictions that match the teacher's over a massive amount of open-domain training data. Such a large prediction discrepancy often diminishes the benefits of knowledge distillation. To address this challenge, we propose Homotopic Distillation (HomoDistil), a novel task-agnostic distillation approach equipped with iterative pruning. Specifically, we initialize the student model from the teacher model, and iteratively prune the student's neurons until the target width is reached. Such an approach maintains a small discrepancy between the teacher's and student's predictions throughout the distillation process, which ensures the effectiveness of knowledge transfer. Extensive experiments demonstrate that HomoDistil achieves significant improvements on existing baselines.
Short Text Pre-training with Extended Token Classification for E-commerce Query Understanding
Oct 08, 2022
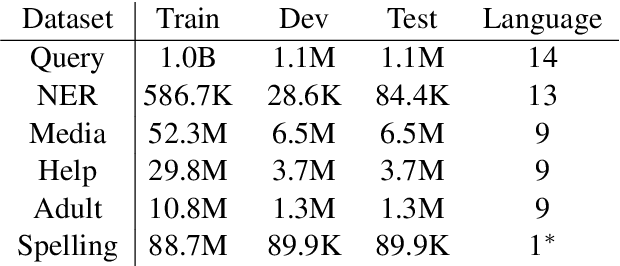
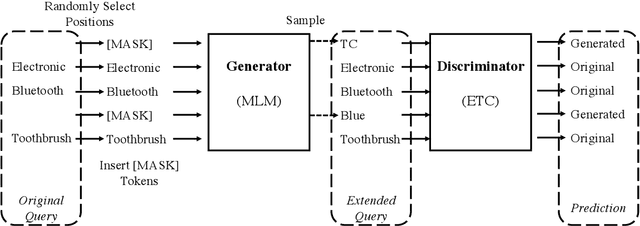
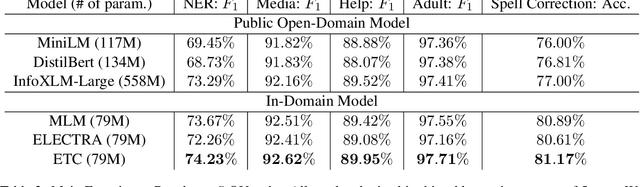
E-commerce query understanding is the process of inferring the shopping intent of customers by extracting semantic meaning from their search queries. The recent progress of pre-trained masked language models (MLM) in natural language processing is extremely attractive for developing effective query understanding models. Specifically, MLM learns contextual text embedding via recovering the masked tokens in the sentences. Such a pre-training process relies on the sufficient contextual information. It is, however, less effective for search queries, which are usually short text. When applying masking to short search queries, most contextual information is lost and the intent of the search queries may be changed. To mitigate the above issues for MLM pre-training on search queries, we propose a novel pre-training task specifically designed for short text, called Extended Token Classification (ETC). Instead of masking the input text, our approach extends the input by inserting tokens via a generator network, and trains a discriminator to identify which tokens are inserted in the extended input. We conduct experiments in an E-commerce store to demonstrate the effectiveness of ETC.
Context-Aware Query Rewriting for Improving Users' Search Experience on E-commerce Websites
Sep 24, 2022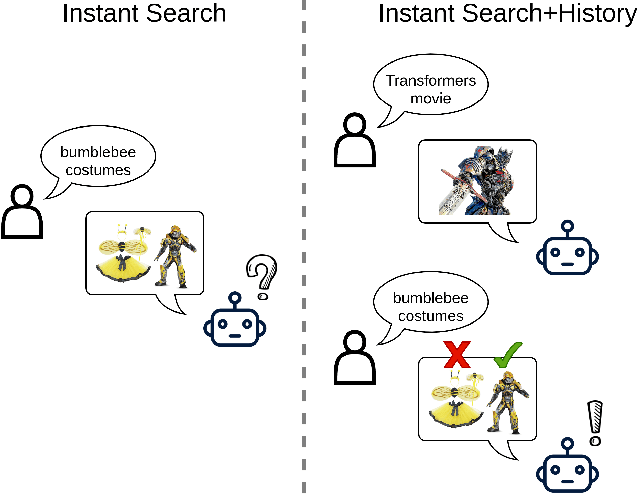
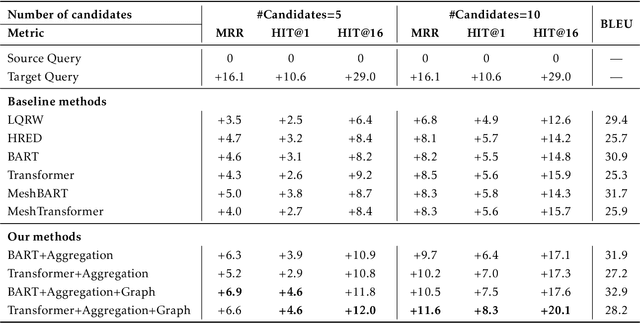
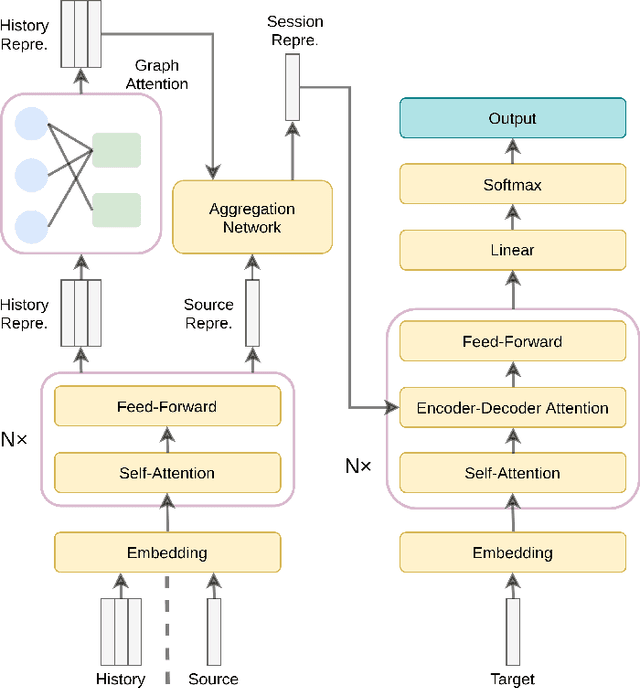
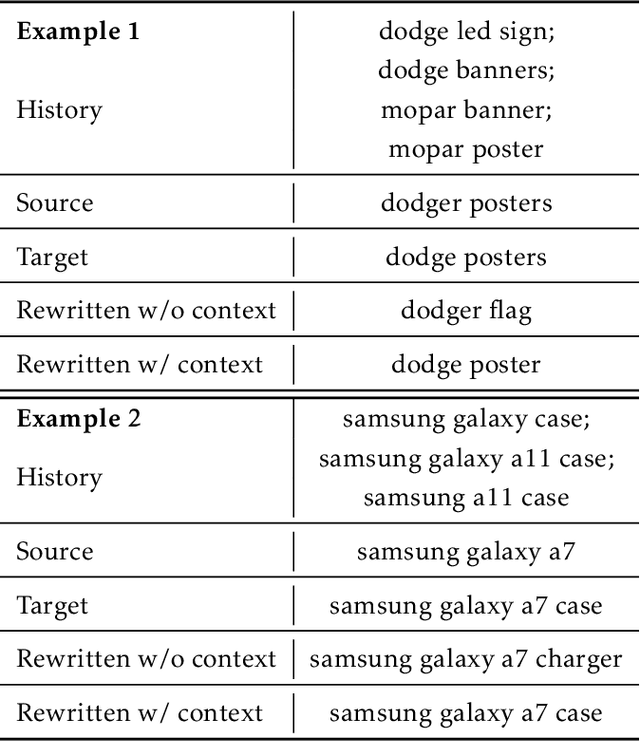
E-commerce queries are often short and ambiguous. Consequently, query understanding often uses query rewriting to disambiguate user-input queries. While using e-commerce search tools, users tend to enter multiple searches, which we call context, before purchasing. These history searches contain contextual insights about users' true shopping intents. Therefore, modeling such contextual information is critical to a better query rewriting model. However, existing query rewriting models ignore users' history behaviors and consider only the instant search query, which is often a short string offering limited information about the true shopping intent. We propose an end-to-end context-aware query rewriting model to bridge this gap, which takes the search context into account. Specifically, our model builds a session graph using the history search queries and their contained words. We then employ a graph attention mechanism that models cross-query relations and computes contextual information of the session. The model subsequently calculates session representations by combining the contextual information with the instant search query using an aggregation network. The session representations are then decoded to generate rewritten queries. Empirically, we demonstrate the superiority of our method to state-of-the-art approaches under various metrics. On in-house data from an online shopping platform, by introducing contextual information, our model achieves 11.6% improvement under the MRR (Mean Reciprocal Rank) metric and 20.1% improvement under the HIT@16 metric (a hit rate metric), in comparison with the best baseline method (Transformer-based model).
DiP-GNN: Discriminative Pre-Training of Graph Neural Networks
Sep 15, 2022
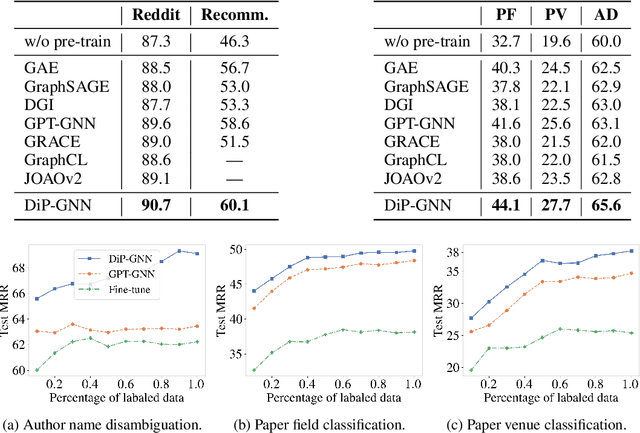
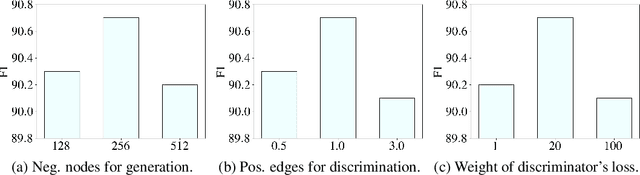
Graph neural network (GNN) pre-training methods have been proposed to enhance the power of GNNs. Specifically, a GNN is first pre-trained on a large-scale unlabeled graph and then fine-tuned on a separate small labeled graph for downstream applications, such as node classification. One popular pre-training method is to mask out a proportion of the edges, and a GNN is trained to recover them. However, such a generative method suffers from graph mismatch. That is, the masked graph inputted to the GNN deviates from the original graph. To alleviate this issue, we propose DiP-GNN (Discriminative Pre-training of Graph Neural Networks). Specifically, we train a generator to recover identities of the masked edges, and simultaneously, we train a discriminator to distinguish the generated edges from the original graph's edges. In our framework, the graph seen by the discriminator better matches the original graph because the generator can recover a proportion of the masked edges. Extensive experiments on large-scale homogeneous and heterogeneous graphs demonstrate the effectiveness of the proposed framework.