 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Rewiring for Editable Graph Neural Network Training
Oct 21, 2024



Deep neural networks are ubiquitously adopted in many applications, such as computer vision, natural language processing, and graph analytics. However, well-trained neural networks can make prediction errors after deployment as the world changes. \textit{Model editing} involves updating the base model to correct prediction errors with less accessible training data and computational resources. Despite recent advances in model editors in computer vision and natural language processing, editable training in graph neural networks (GNNs) is rarely explored. The challenge with editable GNN training lies in the inherent information aggregation across neighbors, which can lead model editors to affect the predictions of other nodes unintentionally. In this paper, we first observe the gradient of cross-entropy loss for the target node and training nodes with significant inconsistency, which indicates that directly fine-tuning the base model using the loss on the target node deteriorates the performance on training nodes. Motivated by the gradient inconsistency observation, we propose a simple yet effective \underline{G}radient \underline{R}ewiring method for \underline{E}ditable graph neural network training, named \textbf{GRE}. Specifically, we first store the anchor gradient of the loss on training nodes to preserve the locality. Subsequently, we rewire the gradient of the loss on the target node to preserve performance on the training node using anchor gradient. Experiments demonstrate the effectiveness of GRE on various model architectures and graph datasets in terms of multiple editing situations. The source code is available at \url{https://github.com/zhimengj0326/Gradient_rewiring_editing}
Exposing Privacy Gaps: Membership Inference Attack on Preference Data for LLM Alignment
Jul 08, 2024



Large Language Models (LLMs) have seen widespread adoption due to their remarkable natural language capabilities. However, when deploying them in real-world settings, it is important to align LLMs to generate texts according to acceptable human standards. Methods such as Proximal Policy Optimization (PPO) and Direct Preference Optimization (DPO) have made significant progress in refining LLMs using human preference data. However, the privacy concerns inherent in utilizing such preference data have yet to be adequately studied. In this paper, we investigate the vulnerability of LLMs aligned using human preference datasets to membership inference attacks (MIAs), highlighting the shortcomings of previous MIA approaches with respect to preference data. Our study has two main contributions: first, we introduce a novel reference-based attack framework specifically for analyzing preference data called PREMIA (\uline{Pre}ference data \uline{MIA}); second, we provide empirical evidence that DPO models are more vulnerable to MIA compared to PPO models. Our findings highlight gaps in current privacy-preserving practices for LLM alignment.
Can Attention Be Used to Explain EHR-Based Mortality Prediction Tasks: A Case Study on Hemorrhagic Stroke
Aug 04, 2023



Stroke is a significant cause of mortality and morbidity, necessitating early predictive strategies to minimize risks. Traditional methods for evaluating patients, such as Acute Physiology and Chronic Health Evaluation (APACHE II, IV) and Simplified Acute Physiology Score III (SAPS III), have limited accuracy and interpretability. This paper proposes a novel approach: an interpretable, attention-based transformer model for early stroke mortality prediction. This model seeks to address the limitations of previous predictive models, providing both interpretability (providing clear, understandable explanations of the model) and fidelity (giving a truthful explanation of the model's dynamics from input to output). Furthermore, the study explores and compares fidelity and interpretability scores using Shapley values and attention-based scores to improve model explainability. The research objectives include designing an interpretable attention-based transformer model, evaluating its performance compared to existing models, and providing feature importance derived from the model.
Efficient GNN Explanation via Learning Removal-based Attribution
Jun 09, 2023



As Graph Neural Networks (GNNs) have been widely used in real-world applications, model explanations are required not only by users but also by legal regulations. However, simultaneously achieving high fidelity and low computational costs in generating explanations has been a challenge for current methods. In this work, we propose a framework of GNN explanation named LeArn Removal-based Attribution (LARA) to address this problem. Specifically, we introduce removal-based attribution and demonstrate its substantiated link to interpretability fidelity theoretically and experimentally. The explainer in LARA learns to generate removal-based attribution which enables providing explanations with high fidelity. A strategy of subgraph sampling is designed in LARA to improve the scalability of the training process. In the deployment, LARA can efficiently generate the explanation through a feed-forward pass. We benchmark our approach with other state-of-the-art GNN explanation methods on six datasets. Results highlight the effectiveness of our framework regarding both efficiency and fidelity. In particular, LARA is 3.5 times faster and achieves higher fidelity than the state-of-the-art method on the large dataset ogbn-arxiv (more than 160K nodes and 1M edges), showing its great potential in real-world applications. Our source code is available at https://anonymous.4open.science/r/LARA-10D8/README.md.
DEGREE: Decomposition Based Explanation For Graph Neural Networks
May 22, 2023



Graph Neural Networks (GNNs) are gaining extensive attention for their application in graph data. However, the black-box nature of GNNs prevents users from understanding and trusting the models, thus hampering their applicability. Whereas explaining GNNs remains a challenge, most existing methods fall into approximation based and perturbation based approaches with suffer from faithfulness problems and unnatural artifacts, respectively. To tackle these problems, we propose DEGREE \degree to provide a faithful explanation for GNN predictions. By decomposing the information generation and aggregation mechanism of GNNs, DEGREE allows tracking the contributions of specific components of the input graph to the final prediction. Based on this, we further design a subgraph level interpretation algorithm to reveal complex interactions between graph nodes that are overlooked by previous methods. The efficiency of our algorithm can be further improved by utilizing GNN characteristics. Finally, we conduct quantitative and qualitative experiments on synthetic and real-world datasets to demonstrate the effectiveness of DEGREE on node classification and graph classification tasks.
Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond
Apr 27, 2023This paper presents a comprehensive and practical guide for practitioners and end-users working with Large Language Models (LLMs) in their downstream natural language processing (NLP) tasks. We provide discussions and insights into the usage of LLMs from the perspectives of models, data, and downstream tasks. Firstly, we offer an introduction and brief summary of current GPT- and BERT-style LLMs. Then, we discuss the influence of pre-training data, training data, and test data. Most importantly, we provide a detailed discussion about the use and non-use cases of large language models for various natural language processing tasks, such as knowledge-intensive tasks, traditional natural language understanding tasks, natural language generation tasks, emergent abilities, and considerations for specific tasks.We present various use cases and non-use cases to illustrate the practical applications and limitations of LLMs in real-world scenarios. We also try to understand the importance of data and the specific challenges associated with each NLP task. Furthermore, we explore the impact of spurious biases on LLMs and delve into other essential considerations, such as efficiency, cost, and latency, to ensure a comprehensive understanding of deploying LLMs in practice. This comprehensive guide aims to provide researchers and practitioners with valuable insights and best practices for working with LLMs, thereby enabling the successful implementation of these models in a wide range of NLP tasks. A curated list of practical guide resources of LLMs, regularly updated, can be found at \url{https://github.com/Mooler0410/LLMsPracticalGuide}.
Did You Train on My Dataset? Towards Public Dataset Protection with Clean-Label Backdoor Watermarking
Mar 20, 2023



The huge supporting training data on the Internet has been a key factor in the success of deep learning models. However, this abundance of public-available data also raises concerns about the unauthorized exploitation of datasets for commercial purposes, which is forbidden by dataset licenses. In this paper, we propose a backdoor-based watermarking approach that serves as a general framework for safeguarding public-available data. By inserting a small number of watermarking samples into the dataset, our approach enables the learning model to implicitly learn a secret function set by defenders. This hidden function can then be used as a watermark to track down third-party models that use the dataset illegally. Unfortunately, existing backdoor insertion methods often entail adding arbitrary and mislabeled data to the training set, leading to a significant drop in performance and easy detection by anomaly detection algorithms. To overcome this challenge, we introduce a clean-label backdoor watermarking framework that uses imperceptible perturbations to replace mislabeled samples. As a result, the watermarking samples remain consistent with the original labels, making them difficult to detect. Our experiments on text, image, and audio datasets demonstrate that the proposed framework effectively safeguards datasets with minimal impact on original task performance. We also show that adding just 1% of watermarking samples can inject a traceable watermarking function and that our watermarking samples are stealthy and look benign upon visual inspection.
Differentially Private Counterfactuals via Functional Mechanism
Aug 04, 2022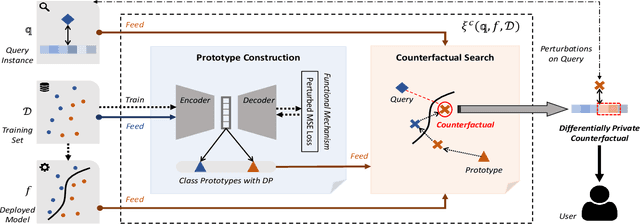
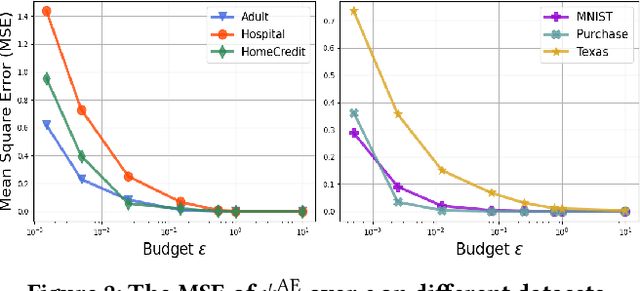
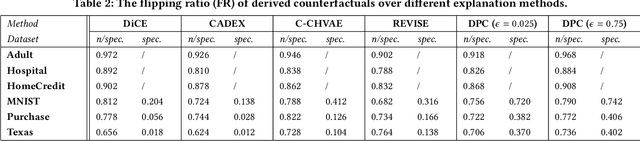
Counterfactual, serving as one emerging type of model explanation, has attracted tons of attentions recently from both industry and academia. Different from the conventional feature-based explanations (e.g., attributions), counterfactuals are a series of hypothetical samples which can flip model decisions with minimal perturbations on queries. Given valid counterfactuals, humans are capable of reasoning under ``what-if'' circumstances, so as to better understand the model decision boundaries. However, releasing counterfactuals could be detrimental, since it may unintentionally leak sensitive information to adversaries, which brings about higher risks on both model security and data privacy. To bridge the gap, in this paper, we propose a novel framework to generate differentially private counterfactual (DPC) without touching the deployed model or explanation set, where noises are injected for protection while maintaining the explanation roles of counterfactual. In particular, we train an autoencoder with the functional mechanism to construct noisy class prototypes, and then derive the DPC from the latent prototypes based on the post-processing immunity of differential privacy. Further evaluations demonstrate the effectiveness of the proposed framework, showing that DPC can successfully relieve the risks on both extraction and inference attacks.
Fair Machine Learning in Healthcare: A Review
Jun 29, 2022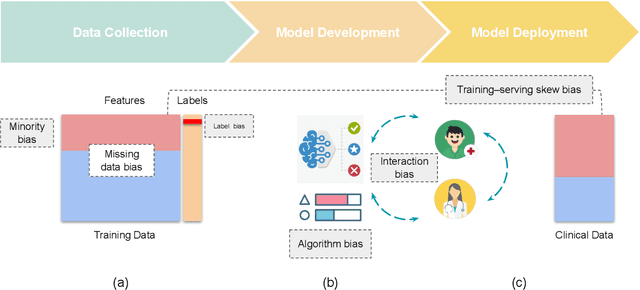

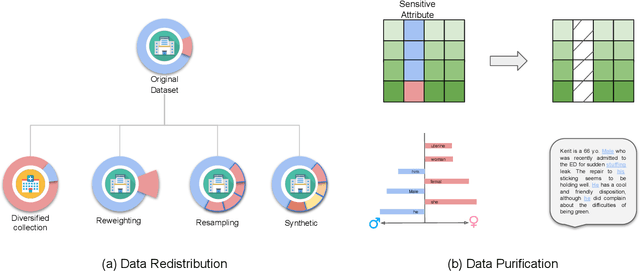
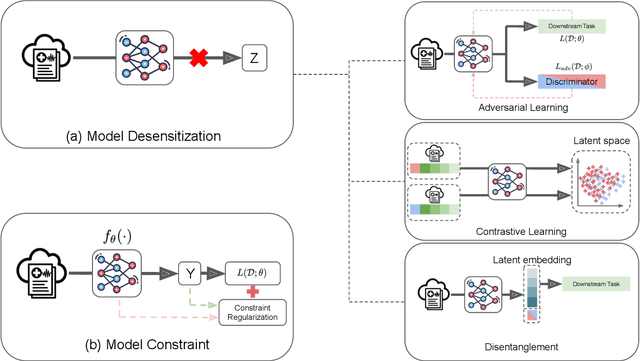
Benefiting from the digitization of healthcare data and the development of computing power, machine learning methods are increasingly used in the healthcare domain. Fairness problems have been identified in machine learning for healthcare, resulting in an unfair allocation of limited healthcare resources or excessive health risks for certain groups. Therefore, addressing the fairness problems has recently attracted increasing attention from the healthcare community. However, the intersection of machine learning for healthcare and fairness in machine learning remains understudied. In this review, we build the bridge by exposing fairness problems, summarizing possible biases, sorting out mitigation methods and pointing out challenges along with opportunities for the future.