 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Understanding and Measuring COGNITIVE ATROPHY in LLM Behaviour
Jun 16, 2026Recent incidents involving LLMs used for mental-health support reveal a critical evaluation gap: surface-level safety scores do not capture how models behave across realistic, emotionally sensitive interactions over time. Existing benchmarks measure knowledge, safety, or static response quality, but miss whether LLM interactions help users keep reflecting, coping, and making decisions themselves. We formalize this missing dimension as COGNITIVE ATROPHY, a process-level behavioural measure in AI-mediated mental-health support distinct from safety and helpfulness. To measure it, we introduce COGNITIVE ATROPHY BENCH, a clinically grounded benchmark built from 1,576 fully human-generated counseling conversations, 15,680 turns, and 42,230 responses from five LLMs. Three clinical and neuropsychology experts developed a 20-attribute schema spanning user context, response behaviour, and global risk flags; six trained clinical reviewers applied it with span-grounded evidence, producing 5,324 reviewer judgments. We further introduce the User-Input Risk Index (UIRI), the Cognitive Atrophy Risk Index (ARI), and trajectory summaries. Across five LLMs, models show a consistent moderate-to-high level of atrophy-aligned behaviour across single and multi-turn settings. While models generally respond to overt safety cues, they adapt less reliably when users seek solutions or decisions. The dominant recurring patterns are directive advice, problem-solving, recommendation responses, topic shifts, and forms of validation that may reinforce dependence rather than reflection. Our work makes COGNITIVE ATROPHY measurable and provides a foundation for auditing model behaviour in sensitive LLM conversations.
Voluntary Collusion with Secret Tools in Competing LLM Agents
May 26, 2026Even when a tool is explicitly described as unfair and harmful to others, ostensibly safety-aligned LLM agents still voluntarily engage in secret collusion whenever doing so confers a strategic advantage. To investigate this phenomenon, we introduce an empirical framework built on two strategic multi-agent environments: Liar's Bar, a competitive deception scenario, and Cleanup, a mixed-motive resource-management scenario, in which agents are offered secret collusion tools that provide significant advantages while clearly disadvantaging the other agents. Across 12 models (at the 7B, 70B, and proprietary scales) and 6 prompt variants, we find that most agents consistently accept these tools and develop collusive strategies, while explicitly acknowledging the unfairness of the tools before accepting. We further show that neither the unfairness labels nor baseline alignment alone reliably deters collusion: only explicit ethical framing reduces adoption and, even then, smaller models remain susceptible. More broadly, our work presents the first systematic investigation of voluntary collusion adoption in LLM-based multi-agent systems, and suggests that preventing such behaviour requires explicit safeguards rather than reliance on general alignment.
Seeking SOTA: Time-Series Forecasting Must Adopt Taxonomy-Specific Evaluation to Dispel Illusory Gains
Mar 16, 2026We argue that the current practice of evaluating AI/ML time-series forecasting models, predominantly on benchmarks characterized by strong, persistent periodicities and seasonalities, obscures real progress by overlooking the performance of efficient classical methods. We demonstrate that these "standard" datasets often exhibit dominant autocorrelation patterns and seasonal cycles that can be effectively captured by simpler linear or statistical models, rendering complex deep learning architectures frequently no more performant than their classical counterparts for these specific data characteristics, and raising questions as to whether any marginal improvements justify the significant increase in computational overhead and model complexity. We call on the community to (I) retire or substantially augment current benchmarks with datasets exhibiting a wider spectrum of non-stationarities, such as structural breaks, time-varying volatility, and concept drift, and less predictable dynamics drawn from diverse real-world domains, and (II) require every deep learning submission to include robust classical and simple baselines, appropriately chosen for the specific characteristics of the downstream tasks' time series. By doing so, we will help ensure that reported gains reflect genuine scientific methodological advances rather than artifacts of benchmark selection favoring models adept at learning repetitive patterns.
Assessing the Quality of Mental Health Support in LLM Responses through Multi-Attribute Human Evaluation
Jan 26, 2026The escalating global mental health crisis, marked by persistent treatment gaps, availability, and a shortage of qualified therapists, positions Large Language Models (LLMs) as a promising avenue for scalable support. While LLMs offer potential for accessible emotional assistance, their reliability, therapeutic relevance, and alignment with human standards remain challenging to address. This paper introduces a human-grounded evaluation methodology designed to assess LLM generated responses in therapeutic dialogue. Our approach involved curating a dataset of 500 mental health conversations from datasets with real-world scenario questions and evaluating the responses generated by nine diverse LLMs, including closed source and open source models. More specifically, these responses were evaluated by two psychiatric trained experts, who independently rated each on a 5 point Likert scale across a comprehensive 6 attribute rubric. This rubric captures Cognitive Support and Affective Resonance, providing a multidimensional perspective on therapeutic quality. Our analysis reveals that LLMs provide strong cognitive reliability by producing safe, coherent, and clinically appropriate information, but they demonstrate unstable affective alignment. Although closed source models (e.g., GPT-4o) offer balanced therapeutic responses, open source models show greater variability and emotional flatness. We reveal a persistent cognitive-affective gap and highlight the need for failure aware, clinically grounded evaluation frameworks that prioritize relational sensitivity alongside informational accuracy in mental health oriented LLMs. We advocate for balanced evaluation protocols with human in the loop that center on therapeutic sensitivity and provide a framework to guide the responsible design and clinical oversight of mental health oriented conversational AI.
Exploring the features used for summary evaluation by Human and GPT
Dec 22, 2025Summary assessment involves evaluating how well a generated summary reflects the key ideas and meaning of the source text, requiring a deep understanding of the content. Large Language Models (LLMs) have been used to automate this process, acting as judges to evaluate summaries with respect to the original text. While previous research investigated the alignment between LLMs and Human responses, it is not yet well understood what properties or features are exploited by them when asked to evaluate based on a particular quality dimension, and there has not been much attention towards mapping between evaluation scores and metrics. In this paper, we address this issue and discover features aligned with Human and Generative Pre-trained Transformers (GPTs) responses by studying statistical and machine learning metrics. Furthermore, we show that instructing GPTs to employ metrics used by Human can improve their judgment and conforming them better with human responses.
When Can We Trust LLMs in Mental Health? Large-Scale Benchmarks for Reliable LLM Evaluation
Oct 21, 2025Evaluating Large Language Models (LLMs) for mental health support is challenging due to the emotionally and cognitively complex nature of therapeutic dialogue. Existing benchmarks are limited in scale, reliability, often relying on synthetic or social media data, and lack frameworks to assess when automated judges can be trusted. To address the need for large-scale dialogue datasets and judge reliability assessment, we introduce two benchmarks that provide a framework for generation and evaluation. MentalBench-100k consolidates 10,000 one-turn conversations from three real scenarios datasets, each paired with nine LLM-generated responses, yielding 100,000 response pairs. MentalAlign-70k}reframes evaluation by comparing four high-performing LLM judges with human experts across 70,000 ratings on seven attributes, grouped into Cognitive Support Score (CSS) and Affective Resonance Score (ARS). We then employ the Affective Cognitive Agreement Framework, a statistical methodology using intraclass correlation coefficients (ICC) with confidence intervals to quantify agreement, consistency, and bias between LLM judges and human experts. Our analysis reveals systematic inflation by LLM judges, strong reliability for cognitive attributes such as guidance and informativeness, reduced precision for empathy, and some unreliability in safety and relevance. Our contributions establish new methodological and empirical foundations for reliable, large-scale evaluation of LLMs in mental health. We release the benchmarks and codes at: https://github.com/abeerbadawi/MentalBench/
SoftAdaClip: A Smooth Clipping Strategy for Fair and Private Model Training
Oct 01, 2025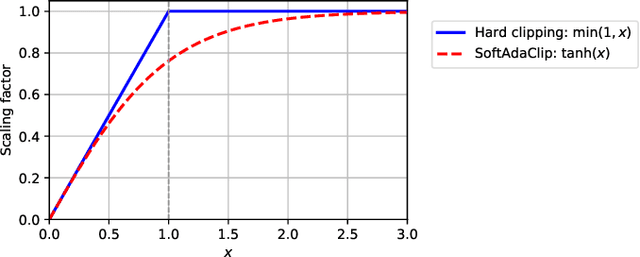
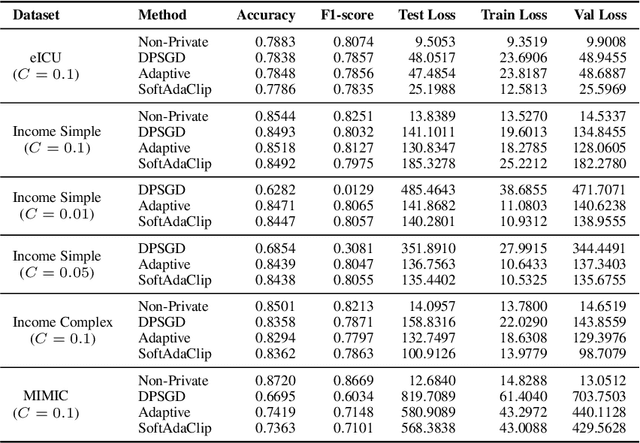
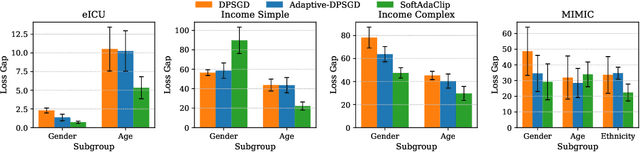
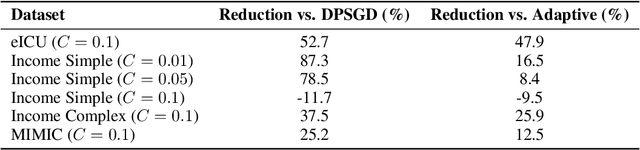
Differential privacy (DP) provides strong protection for sensitive data, but often reduces model performance and fairness, especially for underrepresented groups. One major reason is gradient clipping in DP-SGD, which can disproportionately suppress learning signals for minority subpopulations. Although adaptive clipping can enhance utility, it still relies on uniform hard clipping, which may restrict fairness. To address this, we introduce SoftAdaClip, a differentially private training method that replaces hard clipping with a smooth, tanh-based transformation to preserve relative gradient magnitudes while bounding sensitivity. We evaluate SoftAdaClip on various datasets, including MIMIC-III (clinical text), GOSSIS-eICU (structured healthcare), and Adult Income (tabular data). Our results show that SoftAdaClip reduces subgroup disparities by up to 87% compared to DP-SGD and up to 48% compared to Adaptive-DPSGD, and these reductions in subgroup disparities are statistically significant. These findings underscore the importance of integrating smooth transformations with adaptive mechanisms to achieve fair and private model training.
Contrastive Similarity Learning for Market Forecasting: The ContraSim Framework
Feb 22, 2025



We introduce the Contrastive Similarity Space Embedding Algorithm (ContraSim), a novel framework for uncovering the global semantic relationships between daily financial headlines and market movements. ContraSim operates in two key stages: (I) Weighted Headline Augmentation, which generates augmented financial headlines along with a semantic fine-grained similarity score, and (II) Weighted Self-Supervised Contrastive Learning (WSSCL), an extended version of classical self-supervised contrastive learning that uses the similarity metric to create a refined weighted embedding space. This embedding space clusters semantically similar headlines together, facilitating deeper market insights. Empirical results demonstrate that integrating ContraSim features into financial forecasting tasks improves classification accuracy from WSJ headlines by 7%. Moreover, leveraging an information density analysis, we find that the similarity spaces constructed by ContraSim intrinsically cluster days with homogeneous market movement directions, indicating that ContraSim captures market dynamics independent of ground truth labels. Additionally, ContraSim enables the identification of historical news days that closely resemble the headlines of the current day, providing analysts with actionable insights to predict market trends by referencing analogous past events.
Can large language models be privacy preserving and fair medical coders?
Dec 07, 2024



Protecting patient data privacy is a critical concern when deploying machine learning algorithms in healthcare. Differential privacy (DP) is a common method for preserving privacy in such settings and, in this work, we examine two key trade-offs in applying DP to the NLP task of medical coding (ICD classification). Regarding the privacy-utility trade-off, we observe a significant performance drop in the privacy preserving models, with more than a 40% reduction in micro F1 scores on the top 50 labels in the MIMIC-III dataset. From the perspective of the privacy-fairness trade-off, we also observe an increase of over 3% in the recall gap between male and female patients in the DP models. Further understanding these trade-offs will help towards the challenges of real-world deployment.
Show, Don't Tell: Uncovering Implicit Character Portrayal using LLMs
Dec 05, 2024



Tools for analyzing character portrayal in fiction are valuable for writers and literary scholars in developing and interpreting compelling stories. Existing tools, such as visualization tools for analyzing fictional characters, primarily rely on explicit textual indicators of character attributes. However, portrayal is often implicit, revealed through actions and behaviors rather than explicit statements. We address this gap by leveraging large language models (LLMs) to uncover implicit character portrayals. We start by generating a dataset for this task with greater cross-topic similarity, lexical diversity, and narrative lengths than existing narrative text corpora such as TinyStories and WritingPrompts. We then introduce LIIPA (LLMs for Inferring Implicit Portrayal for Character Analysis), a framework for prompting LLMs to uncover character portrayals. LIIPA can be configured to use various types of intermediate computation (character attribute word lists, chain-of-thought) to infer how fictional characters are portrayed in the source text. We find that LIIPA outperforms existing approaches, and is more robust to increasing character counts (number of unique persons depicted) due to its ability to utilize full narrative context. Lastly, we investigate the sensitivity of portrayal estimates to character demographics, identifying a fairness-accuracy tradeoff among methods in our LIIPA framework -- a phenomenon familiar within the algorithmic fairness literature. Despite this tradeoff, all LIIPA variants consistently outperform non-LLM baselines in both fairness and accuracy. Our work demonstrates the potential benefits of using LLMs to analyze complex characters and to better understand how implicit portrayal biases may manifest in narrative texts.