 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSD-Score: Multi-Scale Distributional Scoring for Reference-Free Image Caption Evaluation
May 07, 2026Evaluating image captions without references remains challenging because global embedding similarity often misses fine-grained mismatches such as hallucinated objects, missing attributes, or incorrect relations. We propose MSD-Score, a reference-free metric that models image patch and text token embeddings as von Mises-Fisher mixtures on the unit hypersphere. Instead of treating each modality as a single point, MSD-Score formulates image-text matching as a multi-scale distributional scoring problem. Semantic discrepancies are quantified via a weighted bi-directional KL divergence and combined with global similarity in a multi-scale framework for both single- and multi-candidate evaluations. Extensive experiments show that MSD-Score achieves state-of-the-art correlation with human judgments among reference-free metrics. Beyond accuracy, its probabilistic formulation yields transparent and decomposable diagnostics of local grounding errors, providing a deterministic complementary signal to holistic similarity metrics and judge-based evaluators.
DiffCap-Bench: A Comprehensive, Challenging, Robust Benchmark for Image Difference Captioning
May 06, 2026Image Difference Captioning (IDC) generates natural language descriptions that precisely identify differences between two images, serving as a key benchmark for fine-grained change perception, cross-modal reasoning, and image editing data construction. However, existing benchmarks lack diversity and compositional complexity, and standard lexical-overlap metrics (e.g., BLEU, METEOR) fail to capture semantic consistency or penalize hallucinations, which together prevent a comprehensive and robust evaluation of multimodal large language models (MLLMs) on IDC. To address these gaps, we introduce DiffCap-Bench, a comprehensive IDC benchmark covering ten distinct difference categories to ensure diversity and compositional complexity. Furthermore, we propose an LLM-as-a-Judge evaluation protocol grounded in human-validated Difference Lists, enabling a robust assessment of models' ability to both capture and describe visual changes. Through extensive evaluation of state-of-the-art MLLMs, we reveal significant performance gaps between proprietary and open-source models, highlight the critical importance of reasoning capability, and identify clear limitations in model scaling. Our framework also demonstrates strong alignment with human expert judgments and strong correlation with downstream image editing data construction quality. These findings establish DiffCap-Bench as both a reliable IDC evaluation framework and a practical predictor of downstream utility. The benchmark and code will be made publicly available to support further research.
MuSS: A Large-Scale Dataset and Cinematic Narrative Benchmark for Multi-Shot Subject-to-Video Generation
Apr 26, 2026While video foundation models excel at single-shot generation, real-world cinematic storytelling inherently relies on complex multi-shot sequencing. Further progress is constrained by the absence of datasets that address three core challenges: authentic narrative logic, spatiotemporal text-video alignment conflicts, and the "copy-paste" dilemma prevalent in Subject-to-Video (S2V) generation. To bridge this gap, we introduce MuSS, a large-scale, dual-track dataset tailored for multi-shot video and S2V generation. Sourced from over 3,000 movies, MuSS explicitly supports both complex montage transitions and subject-centric narratives. To construct this dataset, we pioneer a progressive captioning pipeline that eliminates contextual conflicts by ensuring local shot-level accuracy before enforcing global narrative coherence. Crucially, we implement a cross-shot matching mechanism to fundamentally eradicate the S2V copy-paste shortcut. Alongside the dataset, we propose the Cinematic Narrative Benchmark, featuring a visual-logic-driven paradigm and a novel Anti-Copy-Paste Variance (ACP-Var) metric to rigorously assess continuous storytelling and 3D structural consistency. Extensive experiments demonstrate that while current baselines struggle with continuous narrative logic or degenerate into trivial 2D sticker generators, our MuSS-augmented model achieves state-of-the-art narrative effectiveness and cross-shot identity preservation.
UniVTAC: A Unified Simulation Platform for Visuo-Tactile Manipulation Data Generation, Learning, and Benchmarking
Feb 10, 2026Robotic manipulation has seen rapid progress with vision-language-action (VLA) policies. However, visuo-tactile perception is critical for contact-rich manipulation, as tasks such as insertion are difficult to complete robustly using vision alone. At the same time, acquiring large-scale and reliable tactile data in the physical world remains costly and challenging, and the lack of a unified evaluation platform further limits policy learning and systematic analysis. To address these challenges, we propose UniVTAC, a simulation-based visuo-tactile data synthesis platform that supports three commonly used visuo-tactile sensors and enables scalable and controllable generation of informative contact interactions. Based on this platform, we introduce the UniVTAC Encoder, a visuo-tactile encoder trained on large-scale simulation-synthesized data with designed supervisory signals, providing tactile-centric visuo-tactile representations for downstream manipulation tasks. In addition, we present the UniVTAC Benchmark, which consists of eight representative visuo-tactile manipulation tasks for evaluating tactile-driven policies. Experimental results show that integrating the UniVTAC Encoder improves average success rates by 17.1% on the UniVTAC Benchmark, while real-world robotic experiments further demonstrate a 25% improvement in task success. Our webpage is available at https://univtac.github.io/.
Patch-as-Decodable-Token: Towards Unified Multi-Modal Vision Tasks in MLLMs
Oct 02, 2025
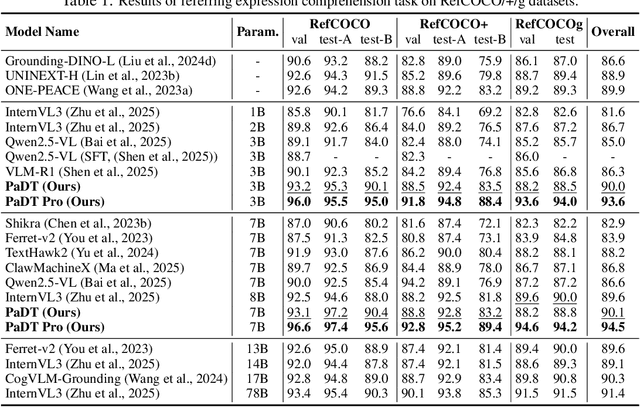

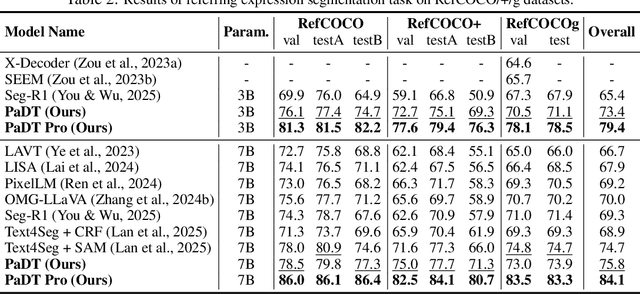
Multimodal large language models (MLLMs) have advanced rapidly in recent years. However, existing approaches for vision tasks often rely on indirect representations, such as generating coordinates as text for detection, which limits performance and prevents dense prediction tasks like segmentation. To overcome these challenges, we introduce Patch-as-Decodable Token (PaDT), a unified paradigm that enables MLLMs to directly generate both textual and diverse visual outputs. Central to PaDT are Visual Reference Tokens (VRTs), derived from visual patch embeddings of query images and interleaved seamlessly with LLM's output textual tokens. A lightweight decoder then transforms LLM's outputs into detection, segmentation, and grounding predictions. Unlike prior methods, PaDT processes VRTs independently at each forward pass and dynamically expands the embedding table, thus improving localization and differentiation among similar objects. We further tailor a training strategy for PaDT by randomly selecting VRTs for supervised fine-tuning and introducing a robust per-token cross-entropy loss. Our empirical studies across four visual perception and understanding tasks suggest PaDT consistently achieving state-of-the-art performance, even compared with significantly larger MLLM models. The code is available at https://github.com/Gorilla-Lab-SCUT/PaDT.
DropLoRA: Sparse Low-Rank Adaptation for Parameter-Efficient Fine-Tuning
Aug 24, 2025LoRA-based large model parameter-efficient fine-tuning (PEFT) methods use low-rank de- composition to approximate updates to model parameters. However, compared to full- parameter fine-tuning, low-rank updates often lead to a performance gap in downstream tasks. To address this, we introduce DropLoRA, a novel pruning-based approach that focuses on pruning the rank dimension. Unlike conven- tional methods that attempt to overcome the low-rank bottleneck, DropLoRA innovatively integrates a pruning module between the two low-rank matrices in LoRA to simulate dy- namic subspace learning. This dynamic low- rank subspace learning allows DropLoRA to overcome the limitations of traditional LoRA, which operates within a static subspace. By continuously adapting the learning subspace, DropLoRA significantly boosts performance without incurring additional training or infer- ence costs. Our experimental results demon- strate that DropLoRA consistently outperforms LoRA in fine-tuning the LLaMA series across a wide range of large language model gener- ation tasks, including commonsense reason- ing, mathematical reasoning, code generation, and instruction-following. Our code is avail- able at https://github.com/TayeeChang/DropLoRA.
MAD-UV: The 1st INTERSPEECH Mice Autism Detection via Ultrasound Vocalization Challenge
Jan 08, 2025


The Mice Autism Detection via Ultrasound Vocalization (MAD-UV) Challenge introduces the first INTERSPEECH challenge focused on detecting autism spectrum disorder (ASD) in mice through their vocalizations. Participants are tasked with developing models to automatically classify mice as either wild-type or ASD models based on recordings with a high sampling rate. Our baseline system employs a simple CNN-based classification using three different spectrogram features. Results demonstrate the feasibility of automated ASD detection, with the considered audible-range features achieving the best performance (UAR of 0.600 for segment-level and 0.625 for subject-level classification). This challenge bridges speech technology and biomedical research, offering opportunities to advance our understanding of ASD models through machine learning approaches. The findings suggest promising directions for vocalization analysis and highlight the potential value of audible and ultrasound vocalizations in ASD detection.
LetsTalk: Latent Diffusion Transformer for Talking Video Synthesis
Nov 24, 2024



Portrait image animation using audio has rapidly advanced, enabling the creation of increasingly realistic and expressive animated faces. The challenges of this multimodality-guided video generation task involve fusing various modalities while ensuring consistency in timing and portrait. We further seek to produce vivid talking heads. To address these challenges, we present LetsTalk (LatEnt Diffusion TranSformer for Talking Video Synthesis), a diffusion transformer that incorporates modular temporal and spatial attention mechanisms to merge multimodality and enhance spatial-temporal consistency. To handle multimodal conditions, we first summarize three fusion schemes, ranging from shallow to deep fusion compactness, and thoroughly explore their impact and applicability. Then we propose a suitable solution according to the modality differences of image, audio, and video generation. For portrait, we utilize a deep fusion scheme (Symbiotic Fusion) to ensure portrait consistency. For audio, we implement a shallow fusion scheme (Direct Fusion) to achieve audio-animation alignment while preserving diversity. Our extensive experiments demonstrate that our approach generates temporally coherent and realistic videos with enhanced diversity and liveliness.
GenCRF: Generative Clustering and Reformulation Framework for Enhanced Intent-Driven Information Retrieval
Sep 17, 2024



Query reformulation is a well-known problem in Information Retrieval (IR) aimed at enhancing single search successful completion rate by automatically modifying user's input query. Recent methods leverage Large Language Models (LLMs) to improve query reformulation, but often generate limited and redundant expansions, potentially constraining their effectiveness in capturing diverse intents. In this paper, we propose GenCRF: a Generative Clustering and Reformulation Framework to capture diverse intentions adaptively based on multiple differentiated, well-generated queries in the retrieval phase for the first time. GenCRF leverages LLMs to generate variable queries from the initial query using customized prompts, then clusters them into groups to distinctly represent diverse intents. Furthermore, the framework explores to combine diverse intents query with innovative weighted aggregation strategies to optimize retrieval performance and crucially integrates a novel Query Evaluation Rewarding Model (QERM) to refine the process through feedback loops. Empirical experiments on the BEIR benchmark demonstrate that GenCRF achieves state-of-the-art performance, surpassing previous query reformulation SOTAs by up to 12% on nDCG@10. These techniques can be adapted to various LLMs, significantly boosting retriever performance and advancing the field of Information Retrieval.
A Unified Label-Aware Contrastive Learning Framework for Few-Shot Named Entity Recognition
Apr 26, 2024



Few-shot Named Entity Recognition (NER) aims to extract named entities using only a limited number of labeled examples. Existing contrastive learning methods often suffer from insufficient distinguishability in context vector representation because they either solely rely on label semantics or completely disregard them. To tackle this issue, we propose a unified label-aware token-level contrastive learning framework. Our approach enriches the context by utilizing label semantics as suffix prompts. Additionally, it simultaneously optimizes context-context and context-label contrastive learning objectives to enhance generalized discriminative contextual representations.Extensive experiments on various traditional test domains (OntoNotes, CoNLL'03, WNUT'17, GUM, I2B2) and the large-scale few-shot NER dataset (FEWNERD) demonstrate the effectiveness of our approach. It outperforms prior state-of-the-art models by a significant margin, achieving an average absolute gain of 7% in micro F1 scores across most scenarios. Further analysis reveals that our model benefits from its powerful transfer capability and improved contextual representations.