 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatch-as-Decodable-Token: Towards Unified Multi-Modal Vision Tasks in MLLMs
Oct 02, 2025
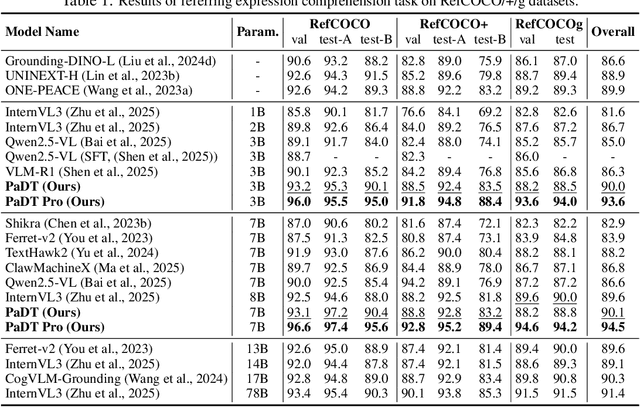

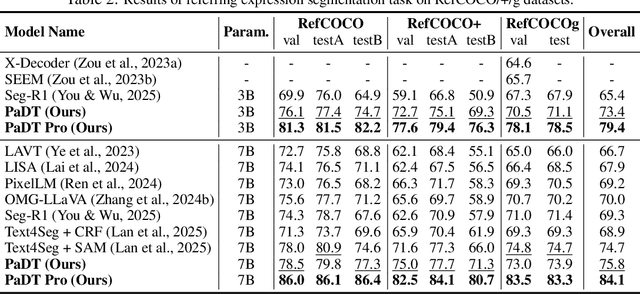
Multimodal large language models (MLLMs) have advanced rapidly in recent years. However, existing approaches for vision tasks often rely on indirect representations, such as generating coordinates as text for detection, which limits performance and prevents dense prediction tasks like segmentation. To overcome these challenges, we introduce Patch-as-Decodable Token (PaDT), a unified paradigm that enables MLLMs to directly generate both textual and diverse visual outputs. Central to PaDT are Visual Reference Tokens (VRTs), derived from visual patch embeddings of query images and interleaved seamlessly with LLM's output textual tokens. A lightweight decoder then transforms LLM's outputs into detection, segmentation, and grounding predictions. Unlike prior methods, PaDT processes VRTs independently at each forward pass and dynamically expands the embedding table, thus improving localization and differentiation among similar objects. We further tailor a training strategy for PaDT by randomly selecting VRTs for supervised fine-tuning and introducing a robust per-token cross-entropy loss. Our empirical studies across four visual perception and understanding tasks suggest PaDT consistently achieving state-of-the-art performance, even compared with significantly larger MLLM models. The code is available at https://github.com/Gorilla-Lab-SCUT/PaDT.
Deep Mesh Reconstruction from Single RGB Images via Topology Modification Networks
Sep 01, 2019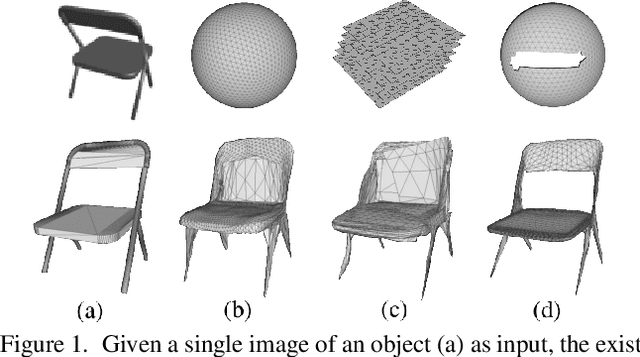
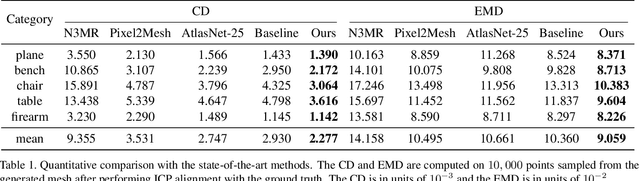
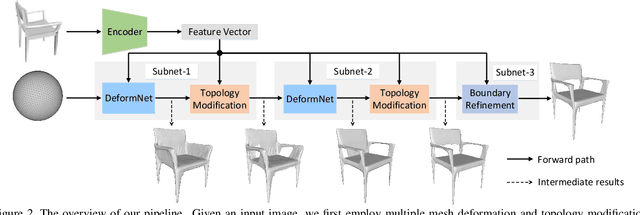

Reconstructing the 3D mesh of a general object from a single image is now possible thanks to the latest advances of deep learning technologies. However, due to the nontrivial difficulty of generating a feasible mesh structure, the state-of-the-art approaches often simplify the problem by learning the displacements of a template mesh that deforms it to the target surface. Though reconstructing a 3D shape with complex topology can be achieved by deforming multiple mesh patches, it remains difficult to stitch the results to ensure a high meshing quality. In this paper, we present an end-to-end single-view mesh reconstruction framework that is able to generate high-quality meshes with complex topologies from a single genus-0 template mesh. The key to our approach is a novel progressive shaping framework that alternates between mesh deformation and topology modification. While a deformation network predicts the per-vertex translations that reduce the gap between the reconstructed mesh and the ground truth, a novel topology modification network is employed to prune the error-prone faces, enabling the evolution of topology. By iterating over the two procedures, one can progressively modify the mesh topology while achieving higher reconstruction accuracy. Moreover, a boundary refinement network is designed to refine the boundary conditions to further improve the visual quality of the reconstructed mesh. Extensive experiments demonstrate that our approach outperforms the current state-of-the-art methods both qualitatively and quantitatively, especially for the shapes with complex topologies.
A Skeleton-bridged Deep Learning Approach for Generating Meshes of Complex Topologies from Single RGB Images
Apr 10, 2019
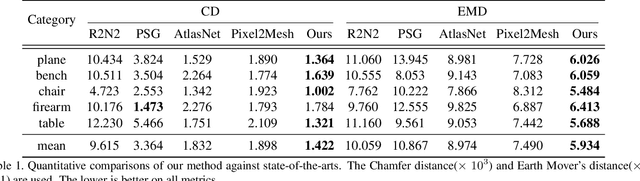
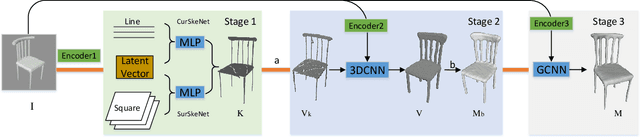
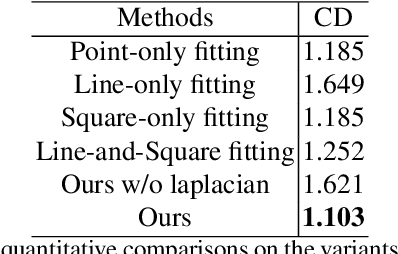
This paper focuses on the challenging task of learning 3D object surface reconstructions from single RGB images. Existing methods achieve varying degrees of success by using different geometric representations. However, they all have their own drawbacks, and cannot well reconstruct those surfaces of complex topologies. To this end, we propose in this paper a skeleton-bridged, stage-wise learning approach to address the challenge. Our use of skeleton is due to its nice property of topology preservation, while being of lower complexity to learn. To learn skeleton from an input image, we design a deep architecture whose decoder is based on a novel design of parallel streams respectively for synthesis of curve- and surface-like skeleton points. We use different shape representations of point cloud, volume, and mesh in our stage-wise learning, in order to take their respective advantages. We also propose multi-stage use of the input image to correct prediction errors that are possibly accumulated in each stage. We conduct intensive experiments to investigate the efficacy of our proposed approach. Qualitative and quantitative results on representative object categories of both simple and complex topologies demonstrate the superiority of our approach over existing ones. We will make our ShapeNet-Skeleton dataset publicly available.