 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuSS: A Large-Scale Dataset and Cinematic Narrative Benchmark for Multi-Shot Subject-to-Video Generation
Apr 26, 2026While video foundation models excel at single-shot generation, real-world cinematic storytelling inherently relies on complex multi-shot sequencing. Further progress is constrained by the absence of datasets that address three core challenges: authentic narrative logic, spatiotemporal text-video alignment conflicts, and the "copy-paste" dilemma prevalent in Subject-to-Video (S2V) generation. To bridge this gap, we introduce MuSS, a large-scale, dual-track dataset tailored for multi-shot video and S2V generation. Sourced from over 3,000 movies, MuSS explicitly supports both complex montage transitions and subject-centric narratives. To construct this dataset, we pioneer a progressive captioning pipeline that eliminates contextual conflicts by ensuring local shot-level accuracy before enforcing global narrative coherence. Crucially, we implement a cross-shot matching mechanism to fundamentally eradicate the S2V copy-paste shortcut. Alongside the dataset, we propose the Cinematic Narrative Benchmark, featuring a visual-logic-driven paradigm and a novel Anti-Copy-Paste Variance (ACP-Var) metric to rigorously assess continuous storytelling and 3D structural consistency. Extensive experiments demonstrate that while current baselines struggle with continuous narrative logic or degenerate into trivial 2D sticker generators, our MuSS-augmented model achieves state-of-the-art narrative effectiveness and cross-shot identity preservation.
LetsTalk: Latent Diffusion Transformer for Talking Video Synthesis
Nov 24, 2024



Portrait image animation using audio has rapidly advanced, enabling the creation of increasingly realistic and expressive animated faces. The challenges of this multimodality-guided video generation task involve fusing various modalities while ensuring consistency in timing and portrait. We further seek to produce vivid talking heads. To address these challenges, we present LetsTalk (LatEnt Diffusion TranSformer for Talking Video Synthesis), a diffusion transformer that incorporates modular temporal and spatial attention mechanisms to merge multimodality and enhance spatial-temporal consistency. To handle multimodal conditions, we first summarize three fusion schemes, ranging from shallow to deep fusion compactness, and thoroughly explore their impact and applicability. Then we propose a suitable solution according to the modality differences of image, audio, and video generation. For portrait, we utilize a deep fusion scheme (Symbiotic Fusion) to ensure portrait consistency. For audio, we implement a shallow fusion scheme (Direct Fusion) to achieve audio-animation alignment while preserving diversity. Our extensive experiments demonstrate that our approach generates temporally coherent and realistic videos with enhanced diversity and liveliness.
Attention based Broadly Self-guided Network for Low light Image Enhancement
Dec 15, 2021
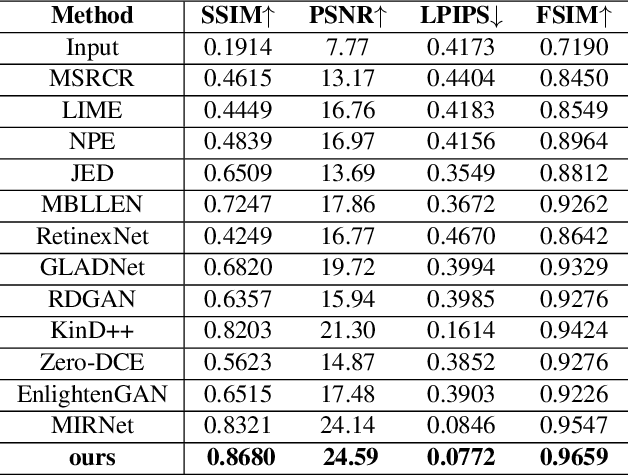
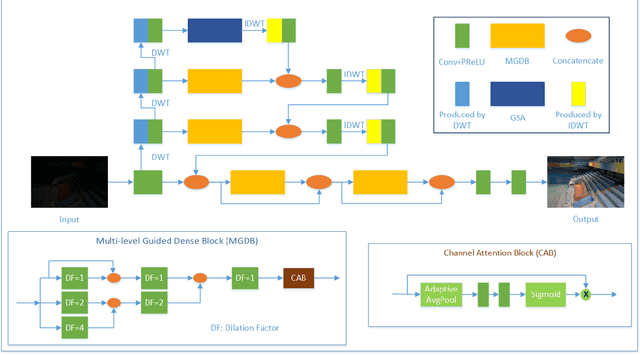
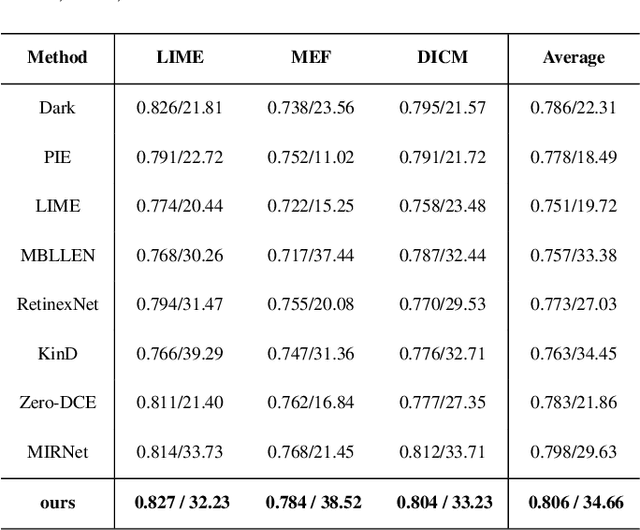
During the past years,deep convolutional neural networks have achieved impressive success in low-light Image Enhancement.Existing deep learning methods mostly enhance the ability of feature extraction by stacking network structures and deepening the depth of the network.which causes more runtime cost on single image.In order to reduce inference time while fully extracting local features and global features.Inspired by SGN,we propose a Attention based Broadly self-guided network (ABSGN) for real world low-light image Enhancement.such a broadly strategy is able to handle the noise at different exposures.The proposed network is validated by many mainstream benchmark.Additional experimental results show that the proposed network outperforms most of state-of-the-art low-light image Enhancement solutions.