 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracking the Feature Dynamics in LLM Training: A Mechanistic Study
Dec 23, 2024



Understanding training dynamics and feature evolution is crucial for the mechanistic interpretability of large language models (LLMs). Although sparse autoencoders (SAEs) have been used to identify features within LLMs, a clear picture of how these features evolve during training remains elusive. In this study, we: (1) introduce SAE-Track, a method to efficiently obtain a continual series of SAEs; (2) formulate the process of feature formation and conduct a mechanistic analysis; and (3) analyze and visualize feature drift during training. Our work provides new insights into the dynamics of features in LLMs, enhancing our understanding of training mechanisms and feature evolution.
DiffusionAttacker: Diffusion-Driven Prompt Manipulation for LLM Jailbreak
Dec 23, 2024



Large Language Models (LLMs) are susceptible to generating harmful content when prompted with carefully crafted inputs, a vulnerability known as LLM jailbreaking. As LLMs become more powerful, studying jailbreak methods is critical to enhancing security and aligning models with human values. Traditionally, jailbreak techniques have relied on suffix addition or prompt templates, but these methods suffer from limited attack diversity. This paper introduces DiffusionAttacker, an end-to-end generative approach for jailbreak rewriting inspired by diffusion models. Our method employs a sequence-to-sequence (seq2seq) text diffusion model as a generator, conditioning on the original prompt and guiding the denoising process with a novel attack loss. Unlike previous approaches that use autoregressive LLMs to generate jailbreak prompts, which limit the modification of already generated tokens and restrict the rewriting space, DiffusionAttacker utilizes a seq2seq diffusion model, allowing more flexible token modifications. This approach preserves the semantic content of the original prompt while producing harmful content. Additionally, we leverage the Gumbel-Softmax technique to make the sampling process from the diffusion model's output distribution differentiable, eliminating the need for iterative token search. Extensive experiments on Advbench and Harmbench demonstrate that DiffusionAttacker outperforms previous methods across various evaluation metrics, including attack success rate (ASR), fluency, and diversity.
CRoF: CLIP-based Robust Few-shot Learning on Noisy Labels
Dec 17, 2024



Noisy labels threaten the robustness of few-shot learning (FSL) due to the inexact features in a new domain. CLIP, a large-scale vision-language model, performs well in FSL on image-text embedding similarities, but it is susceptible to misclassification caused by noisy labels. How to enhance domain generalization of CLIP on noisy data within FSL tasks is a critical challenge. In this paper, we provide a novel view to mitigate the influence of noisy labels, CLIP-based Robust Few-shot learning (CRoF). CRoF is a general plug-in module for CLIP-based models. To avoid misclassification and confused label embedding, we design the few-shot task-oriented prompt generator to give more discriminative descriptions of each category. The proposed prompt achieves larger distances of inter-class textual embedding. Furthermore, rather than fully trusting zero-shot classification by CLIP, we fine-tune CLIP on noisy few-shot data in a new domain with a weighting strategy like label-smooth. The weights for multiple potentially correct labels consider the relationship between CLIP's prior knowledge and original label information to ensure reliability. Our multiple label loss function further supports robust training under this paradigm. Comprehensive experiments show that CRoF, as a plug-in, outperforms fine-tuned and vanilla CLIP models on different noise types and noise ratios.
Seed-CTS: Unleashing the Power of Tree Search for Superior Performance in Competitive Coding Tasks
Dec 17, 2024Competition-level code generation tasks pose significant challenges for current state-of-the-art large language models (LLMs). For example, on the LiveCodeBench-Hard dataset, models such as O1-Mini and O1-Preview achieve pass@1 rates of only 0.366 and 0.143, respectively. While tree search techniques have proven effective in domains like mathematics and general coding, their potential in competition-level code generation remains under-explored. In this work, we propose a novel token-level tree search method specifically designed for code generation. Leveraging Qwen2.5-Coder-32B-Instruct, our approach achieves a pass rate of 0.305 on LiveCodeBench-Hard, surpassing the pass@100 performance of GPT4o-0513 (0.245). Furthermore, by integrating Chain-of-Thought (CoT) prompting, we improve our method's performance to 0.351, approaching O1-Mini's pass@1 rate. To ensure reproducibility, we report the average number of generations required per problem by our tree search method on the test set. Our findings underscore the potential of tree search to significantly enhance performance on competition-level code generation tasks. This opens up new possibilities for large-scale synthesis of challenging code problems supervised fine-tuning (SFT) data, advancing competition-level code generation tasks.
Unveiling the Secret Recipe: A Guide For Supervised Fine-Tuning Small LLMs
Dec 17, 2024The rise of large language models (LLMs) has created a significant disparity: industrial research labs with their computational resources, expert teams, and advanced infrastructures, can effectively fine-tune LLMs, while individual developers and small organizations face barriers due to limited resources. In this paper, we aim to bridge this gap by presenting a comprehensive study on supervised fine-tuning of LLMs using instruction-tuning datasets spanning diverse knowledge domains and skills. We focus on small-sized LLMs (3B to 7B parameters) for their cost-efficiency and accessibility. We explore various training configurations and strategies across four open-source pre-trained models. We provide detailed documentation of these configurations, revealing findings that challenge several common training practices, including hyperparameter recommendations from TULU and phased training recommended by Orca. Key insights from our work include: (i) larger batch sizes paired with lower learning rates lead to improved model performance on benchmarks such as MMLU, MTBench, and Open LLM Leaderboard; (ii) early-stage training dynamics, such as lower gradient norms and higher loss values, are strong indicators of better final model performance, enabling early termination of sub-optimal runs and significant computational savings; (iii) through a thorough exploration of hyperparameters like warmup steps and learning rate schedules, we provide guidance for practitioners and find that certain simplifications do not compromise performance; and (iv) we observed no significant difference in performance between phased and stacked training strategies, but stacked training is simpler and more sample efficient. With these findings holding robustly across datasets and models, we hope this study serves as a guide for practitioners fine-tuning small LLMs and promotes a more inclusive environment for LLM research.
Improving Automatic Fetal Biometry Measurement with Swoosh Activation Function
Dec 16, 2024The measurement of fetal thalamus diameter (FTD) and fetal head circumference (FHC) are crucial in identifying abnormal fetal thalamus development as it may lead to certain neuropsychiatric disorders in later life. However, manual measurements from 2D-US images are laborious, prone to high inter-observer variability, and complicated by the high signal-to-noise ratio nature of the images. Deep learning-based landmark detection approaches have shown promise in measuring biometrics from US images, but the current state-of-the-art (SOTA) algorithm, BiometryNet, is inadequate for FTD and FHC measurement due to its inability to account for the fuzzy edges of these structures and the complex shape of the FTD structure. To address these inadequacies, we propose a novel Swoosh Activation Function (SAF) designed to enhance the regularization of heatmaps produced by landmark detection algorithms. Our SAF serves as a regularization term to enforce an optimum mean squared error (MSE) level between predicted heatmaps, reducing the dispersiveness of hotspots in predicted heatmaps. Our experimental results demonstrate that SAF significantly improves the measurement performances of FTD and FHC with higher intraclass correlation coefficient scores in FTD and lower mean difference scores in FHC measurement than those of the current SOTA algorithm BiometryNet. Moreover, our proposed SAF is highly generalizable and architecture-agnostic. The SAF's coefficients can be configured for different tasks, making it highly customizable. Our study demonstrates that the SAF activation function is a novel method that can improve measurement accuracy in fetal biometry landmark detection. This improvement has the potential to contribute to better fetal monitoring and improved neonatal outcomes.
5G NR monostatic positioning with array impairments: Data-and-model-driven framework and experiment results
Dec 11, 2024



In this article, we present an intelligent framework for 5G new radio (NR) indoor positioning under a monostatic configuration. The primary objective is to estimate both the angle of arrival and time of arrival simultaneously. This requires capturing the pertinent information from both the antenna and subcarrier dimensions of the receive signals. To tackle the challenges posed by the intricacy of the high-dimensional information matrix, coupled with the impact of irregular array errors, we design a deep learning scheme. Recognizing that the phase difference between any two subcarriers and antennas encodes spatial information of the target, we contend that the transformer network is better suited for this problem compared to the convolutional neural network which excels in local feature extraction. To further enhance the network's fitting capability, we integrate the transformer with a model-based multiple-signal-classification (MUSIC) region decision mechanism. Numerical results and field tests demonstrate the effectiveness of the proposed framework in accurately calibrating the irregular angle-dependent array error and improving positioning accuracy.
StyleStudio: Text-Driven Style Transfer with Selective Control of Style Elements
Dec 11, 2024



Text-driven style transfer aims to merge the style of a reference image with content described by a text prompt. Recent advancements in text-to-image models have improved the nuance of style transformations, yet significant challenges remain, particularly with overfitting to reference styles, limiting stylistic control, and misaligning with textual content. In this paper, we propose three complementary strategies to address these issues. First, we introduce a cross-modal Adaptive Instance Normalization (AdaIN) mechanism for better integration of style and text features, enhancing alignment. Second, we develop a Style-based Classifier-Free Guidance (SCFG) approach that enables selective control over stylistic elements, reducing irrelevant influences. Finally, we incorporate a teacher model during early generation stages to stabilize spatial layouts and mitigate artifacts. Our extensive evaluations demonstrate significant improvements in style transfer quality and alignment with textual prompts. Furthermore, our approach can be integrated into existing style transfer frameworks without fine-tuning.
An Entailment Tree Generation Approach for Multimodal Multi-Hop Question Answering with Mixture-of-Experts and Iterative Feedback Mechanism
Dec 10, 2024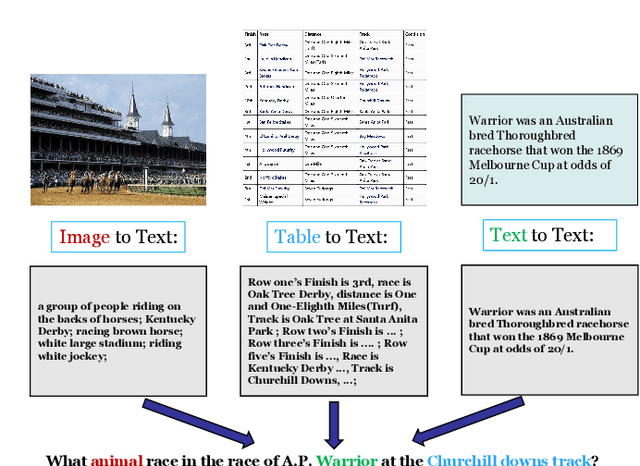



With the rise of large-scale language models (LLMs), it is currently popular and effective to convert multimodal information into text descriptions for multimodal multi-hop question answering. However, we argue that the current methods of multi-modal multi-hop question answering still mainly face two challenges: 1) The retrieved evidence containing a large amount of redundant information, inevitably leads to a significant drop in performance due to irrelevant information misleading the prediction. 2) The reasoning process without interpretable reasoning steps makes the model difficult to discover the logical errors for handling complex questions. To solve these problems, we propose a unified LLMs-based approach but without heavily relying on them due to the LLM's potential errors, and innovatively treat multimodal multi-hop question answering as a joint entailment tree generation and question answering problem. Specifically, we design a multi-task learning framework with a focus on facilitating common knowledge sharing across interpretability and prediction tasks while preventing task-specific errors from interfering with each other via mixture of experts. Afterward, we design an iterative feedback mechanism to further enhance both tasks by feeding back the results of the joint training to the LLM for regenerating entailment trees, aiming to iteratively refine the potential answer. Notably, our method has won the first place in the official leaderboard of WebQA (since April 10, 2024), and achieves competitive results on MultimodalQA.
* Erratum: We identified an error in the calculation of the F1 score in table 4 reported in a previous version of this work. The performance of the new result is better than the previous one. The corrected values are included in this updated version of the paper. These changes do not alter the primary conclusions of our research
Training-Free Bayesianization for Low-Rank Adapters of Large Language Models
Dec 07, 2024



Estimating the uncertainty of responses of Large Language Models~(LLMs) remains a critical challenge. While recent Bayesian methods have demonstrated effectiveness in quantifying uncertainty through low-rank weight updates, they typically require complex fine-tuning or post-training procedures. In this paper, we propose Training-Free Bayesianization~(TFB), a novel framework that transforms existing off-the-shelf trained LoRA adapters into Bayesian ones without additional training. TFB systematically searches for the maximally acceptable level of variance in the weight posterior, constrained within a family of low-rank isotropic Gaussian distributions. We theoretically demonstrate that under mild conditions, this search process is equivalent to variational inference for the weights. Through comprehensive experiments, we show that TFB achieves superior uncertainty estimation and generalization compared to existing methods while eliminating the need for complex training procedures. Code will be available at https://github.com/Wang-ML-Lab/bayesian-peft.