 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPHINX-X: Scaling Data and Parameters for a Family of Multi-modal Large Language Models
Feb 08, 2024



We propose SPHINX-X, an extensive Multimodality Large Language Model (MLLM) series developed upon SPHINX. To improve the architecture and training efficiency, we modify the SPHINX framework by removing redundant visual encoders, bypassing fully-padded sub-images with skip tokens, and simplifying multi-stage training into a one-stage all-in-one paradigm. To fully unleash the potential of MLLMs, we assemble a comprehensive multi-domain and multimodal dataset covering publicly available resources in language, vision, and vision-language tasks. We further enrich this collection with our curated OCR intensive and Set-of-Mark datasets, extending the diversity and generality. By training over different base LLMs including TinyLlama1.1B, InternLM2-7B, LLaMA2-13B, and Mixtral8x7B, we obtain a spectrum of MLLMs that vary in parameter size and multilingual capabilities. Comprehensive benchmarking reveals a strong correlation between the multi-modal performance with the data and parameter scales. Code and models are released at https://github.com/Alpha-VLLM/LLaMA2-Accessory
LMDrive: Closed-Loop End-to-End Driving with Large Language Models
Dec 21, 2023Despite significant recent progress in the field of autonomous driving, modern methods still struggle and can incur serious accidents when encountering long-tail unforeseen events and challenging urban scenarios. On the one hand, large language models (LLM) have shown impressive reasoning capabilities that approach "Artificial General Intelligence". On the other hand, previous autonomous driving methods tend to rely on limited-format inputs (e.g. sensor data and navigation waypoints), restricting the vehicle's ability to understand language information and interact with humans. To this end, this paper introduces LMDrive, a novel language-guided, end-to-end, closed-loop autonomous driving framework. LMDrive uniquely processes and integrates multi-modal sensor data with natural language instructions, enabling interaction with humans and navigation software in realistic instructional settings. To facilitate further research in language-based closed-loop autonomous driving, we also publicly release the corresponding dataset which includes approximately 64K instruction-following data clips, and the LangAuto benchmark that tests the system's ability to handle complex instructions and challenging driving scenarios. Extensive closed-loop experiments are conducted to demonstrate LMDrive's effectiveness. To the best of our knowledge, we're the very first work to leverage LLMs for closed-loop end-to-end autonomous driving. Codes, models, and datasets can be found at https://github.com/opendilab/LMDrive
MCANet: Medical Image Segmentation with Multi-Scale Cross-Axis Attention
Dec 20, 2023Efficiently capturing multi-scale information and building long-range dependencies among pixels are essential for medical image segmentation because of the various sizes and shapes of the lesion regions or organs. In this paper, we present Multi-scale Cross-axis Attention (MCA) to solve the above challenging issues based on the efficient axial attention. Instead of simply connecting axial attention along the horizontal and vertical directions sequentially, we propose to calculate dual cross attentions between two parallel axial attentions to capture global information better. To process the significant variations of lesion regions or organs in individual sizes and shapes, we also use multiple convolutions of strip-shape kernels with different kernel sizes in each axial attention path to improve the efficiency of the proposed MCA in encoding spatial information. We build the proposed MCA upon the MSCAN backbone, yielding our network, termed MCANet. Our MCANet with only 4M+ parameters performs even better than most previous works with heavy backbones (e.g., Swin Transformer) on four challenging tasks, including skin lesion segmentation, nuclei segmentation, abdominal multi-organ segmentation, and polyp segmentation. Code is available at https://github.com/haoshao-nku/medical_seg.
Polyper: Boundary Sensitive Polyp Segmentation
Dec 14, 2023



We present a new boundary sensitive framework for polyp segmentation, called Polyper. Our method is motivated by a clinical approach that seasoned medical practitioners often leverage the inherent features of interior polyp regions to tackle blurred boundaries.Inspired by this, we propose explicitly leveraging polyp regions to bolster the model's boundary discrimination capability while minimizing computation. Our approach first extracts boundary and polyp regions from the initial segmentation map through morphological operators. Then, we design the boundary sensitive attention that concentrates on augmenting the features near the boundary regions using the interior polyp regions's characteristics to generate good segmentation results. Our proposed method can be seamlessly integrated with classical encoder networks, like ResNet-50, MiT-B1, and Swin Transformer. To evaluate the effectiveness of Polyper, we conduct experiments on five publicly available challenging datasets, and receive state-of-the-art performance on all of them. Code is available at https://github.com/haoshao-nku/medical_seg.git.
ReasonNet: End-to-End Driving with Temporal and Global Reasoning
May 17, 2023



The large-scale deployment of autonomous vehicles is yet to come, and one of the major remaining challenges lies in urban dense traffic scenarios. In such cases, it remains challenging to predict the future evolution of the scene and future behaviors of objects, and to deal with rare adverse events such as the sudden appearance of occluded objects. In this paper, we present ReasonNet, a novel end-to-end driving framework that extensively exploits both temporal and global information of the driving scene. By reasoning on the temporal behavior of objects, our method can effectively process the interactions and relationships among features in different frames. Reasoning about the global information of the scene can also improve overall perception performance and benefit the detection of adverse events, especially the anticipation of potential danger from occluded objects. For comprehensive evaluation on occlusion events, we also release publicly a driving simulation benchmark DriveOcclusionSim consisting of diverse occlusion events. We conduct extensive experiments on multiple CARLA benchmarks, where our model outperforms all prior methods, ranking first on the sensor track of the public CARLA Leaderboard.
Efficient Reinforcement Learning for Autonomous Driving with Parameterized Skills and Priors
May 08, 2023When autonomous vehicles are deployed on public roads, they will encounter countless and diverse driving situations. Many manually designed driving policies are difficult to scale to the real world. Fortunately, reinforcement learning has shown great success in many tasks by automatic trial and error. However, when it comes to autonomous driving in interactive dense traffic, RL agents either fail to learn reasonable performance or necessitate a large amount of data. Our insight is that when humans learn to drive, they will 1) make decisions over the high-level skill space instead of the low-level control space and 2) leverage expert prior knowledge rather than learning from scratch. Inspired by this, we propose ASAP-RL, an efficient reinforcement learning algorithm for autonomous driving that simultaneously leverages motion skills and expert priors. We first parameterized motion skills, which are diverse enough to cover various complex driving scenarios and situations. A skill parameter inverse recovery method is proposed to convert expert demonstrations from control space to skill space. A simple but effective double initialization technique is proposed to leverage expert priors while bypassing the issue of expert suboptimality and early performance degradation. We validate our proposed method on interactive dense-traffic driving tasks given simple and sparse rewards. Experimental results show that our method can lead to higher learning efficiency and better driving performance relative to previous methods that exploit skills and priors differently. Code is open-sourced to facilitate further research.
Safety-Enhanced Autonomous Driving Using Interpretable Sensor Fusion Transformer
Jul 29, 2022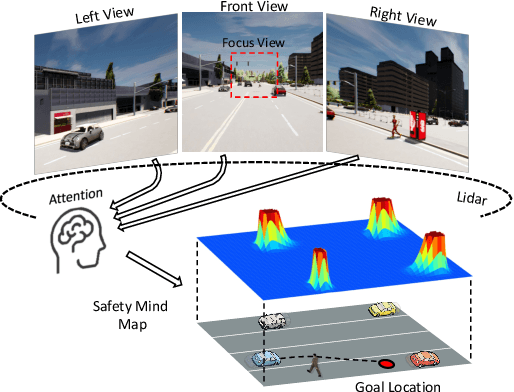
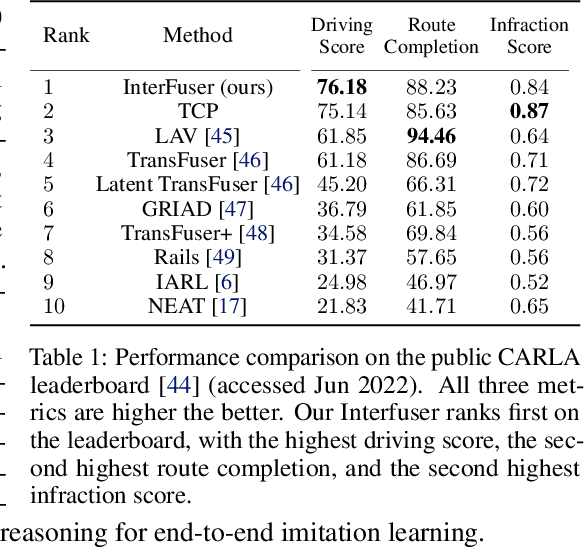
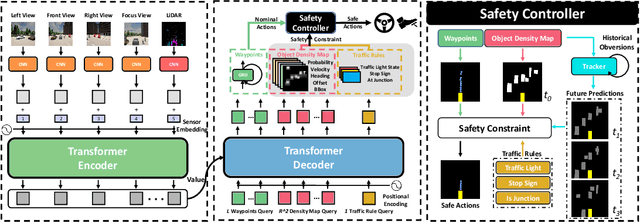
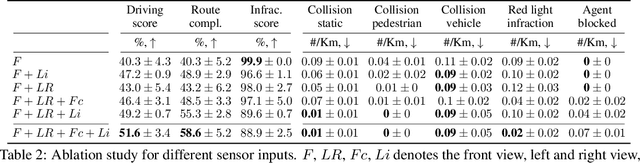
Large-scale deployment of autonomous vehicles has been continually delayed due to safety concerns. On the one hand, comprehensive scene understanding is indispensable, a lack of which would result in vulnerability to rare but complex traffic situations, such as the sudden emergence of unknown objects. However, reasoning from a global context requires access to sensors of multiple types and adequate fusion of multi-modal sensor signals, which is difficult to achieve. On the other hand, the lack of interpretability in learning models also hampers the safety with unverifiable failure causes. In this paper, we propose a safety-enhanced autonomous driving framework, named Interpretable Sensor Fusion Transformer(InterFuser), to fully process and fuse information from multi-modal multi-view sensors for achieving comprehensive scene understanding and adversarial event detection. Besides, intermediate interpretable features are generated from our framework, which provide more semantics and are exploited to better constrain actions to be within the safe sets. We conducted extensive experiments on CARLA benchmarks, where our model outperforms prior methods, ranking the first on the public CARLA Leaderboard. Our code will be made available at https://github.com/opendilab/InterFuser
Blending Anti-Aliasing into Vision Transformer
Oct 28, 2021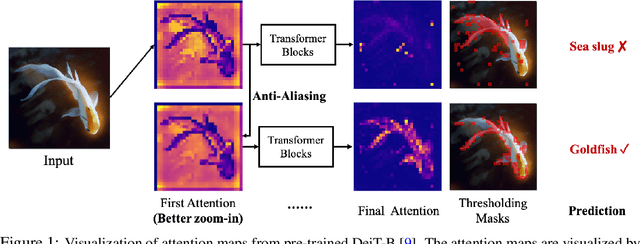
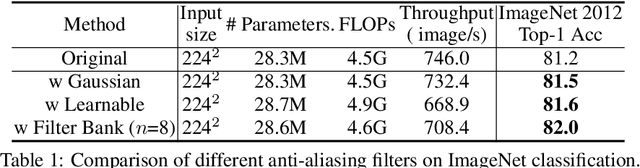

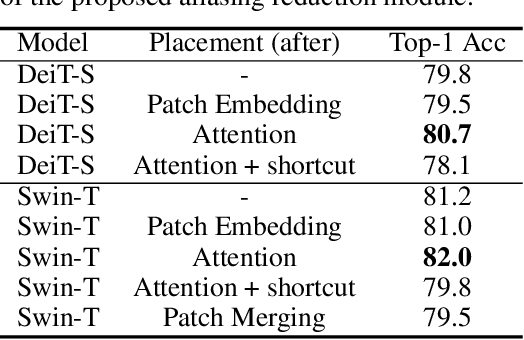
The transformer architectures, based on self-attention mechanism and convolution-free design, recently found superior performance and booming applications in computer vision. However, the discontinuous patch-wise tokenization process implicitly introduces jagged artifacts into attention maps, arising the traditional problem of aliasing for vision transformers. Aliasing effect occurs when discrete patterns are used to produce high frequency or continuous information, resulting in the indistinguishable distortions. Recent researches have found that modern convolution networks still suffer from this phenomenon. In this work, we analyze the uncharted problem of aliasing in vision transformer and explore to incorporate anti-aliasing properties. Specifically, we propose a plug-and-play Aliasing-Reduction Module(ARM) to alleviate the aforementioned issue. We investigate the effectiveness and generalization of the proposed method across multiple tasks and various vision transformer families. This lightweight design consistently attains a clear boost over several famous structures. Furthermore, our module also improves data efficiency and robustness of vision transformers.
Leaning Compact and Representative Features for Cross-Modality Person Re-Identification
Mar 26, 2021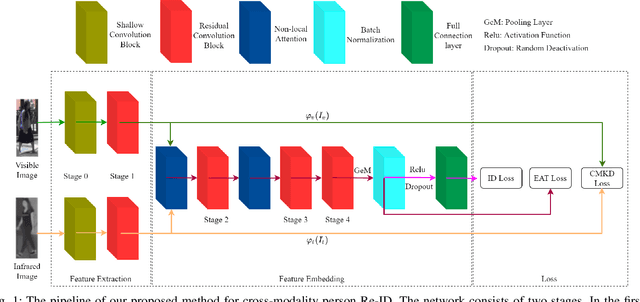
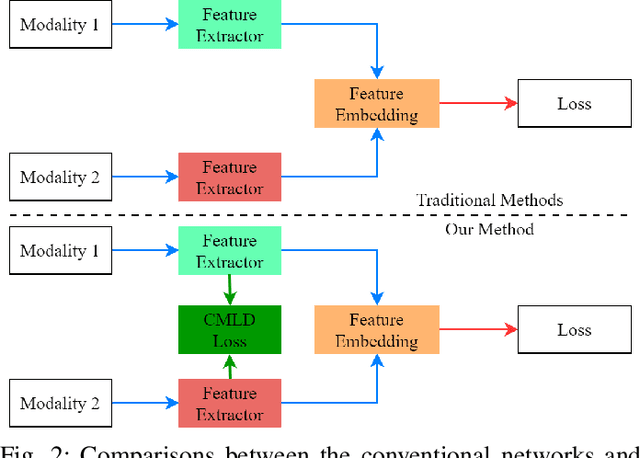


This paper pays close attention to the cross-modality visible-infrared person re-identification (VI Re-ID) task, which aims to match human samples between visible and infrared modes. In order to reduce the discrepancy between features of different modalities, most existing works usually use constraints based on Euclidean metric. Since the Euclidean based distance metric cannot effectively measure the internal angles between the embedded vectors, the above methods cannot learn the angularly discriminative feature embedding. Because the most important factor affecting the classification task based on embedding vector is whether there is an angularly discriminativ feature space, in this paper, we propose a new loss function called Enumerate Angular Triplet (EAT) loss. Also, motivated by the knowledge distillation, to narrow down the features between different modalities before feature embedding, we further present a new Cross-Modality Knowledge Distillation (CMKD) loss. The experimental results on RegDB and SYSU-MM01 datasets have shown that the proposed method is superior to the other most advanced methods in terms of impressive performance.
Complementary Boundary Generator with Scale-Invariant Relation Modeling for Temporal Action Localization: Submission to ActivityNet Challenge 2020
Aug 26, 2020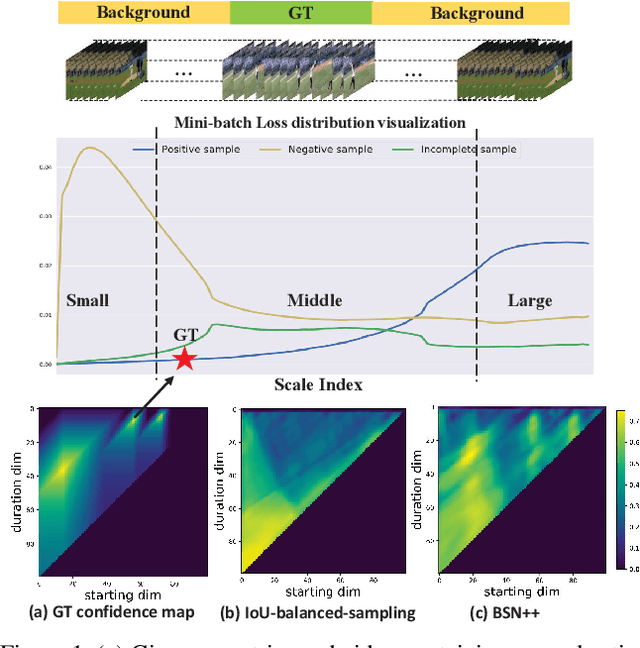
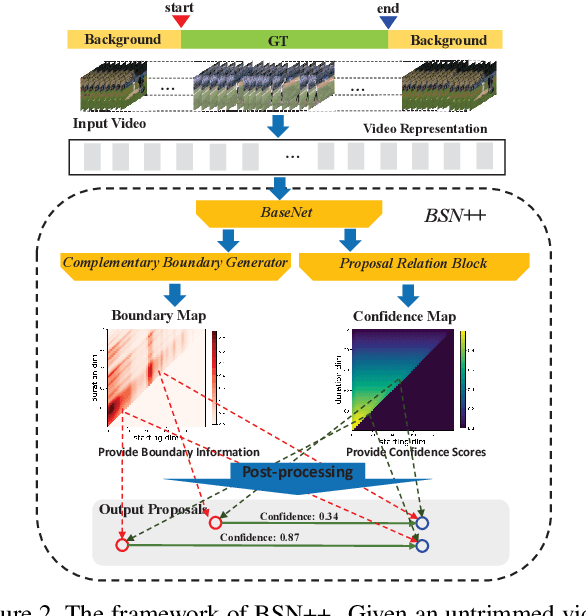
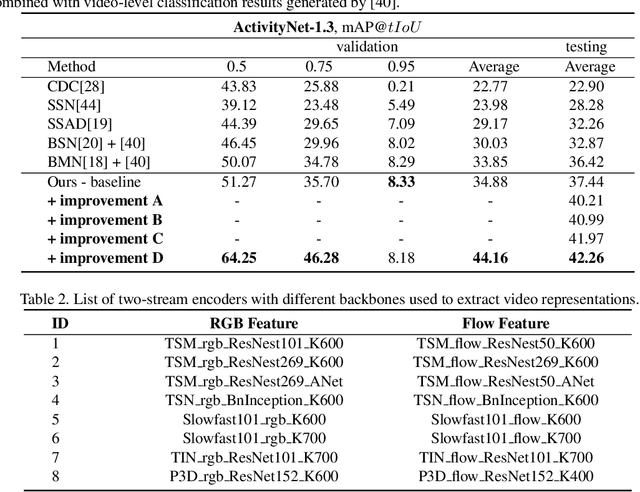
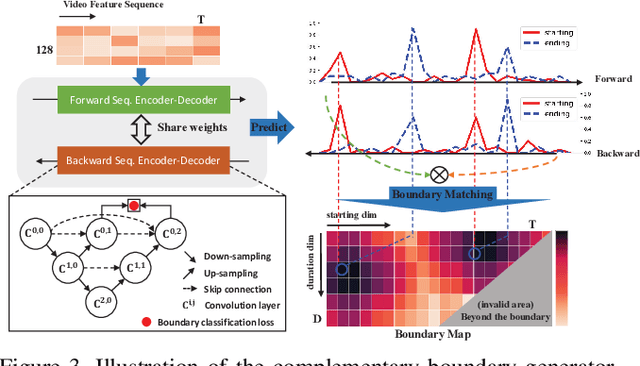
This technical report presents an overview of our solution used in the submission to ActivityNet Challenge 2020 Task 1 (\textbf{temporal action localization/detection}). Temporal action localization requires to not only precisely locate the temporal boundaries of action instances, but also accurately classify the untrimmed videos into specific categories. In this paper, we decouple the temporal action localization task into two stages (i.e. proposal generation and classification) and enrich the proposal diversity through exhaustively exploring the influences of multiple components from different but complementary perspectives. Specifically, in order to generate high-quality proposals, we consider several factors including the video feature encoder, the proposal generator, the proposal-proposal relations, the scale imbalance, and ensemble strategy. Finally, in order to obtain accurate detections, we need to further train an optimal video classifier to recognize the generated proposals. Our proposed scheme achieves the state-of-the-art performance on the temporal action localization task with \textbf{42.26} average mAP on the challenge testing set.