 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUSTBench: Benchmarking and Dissecting Spatiotemporal Reasoning of LLMs as Urban Agents
May 23, 2025



Large language models (LLMs) have shown emerging potential in spatiotemporal reasoning, making them promising candidates for building urban agents that support diverse urban downstream applications. Despite these benefits, existing studies primarily focus on evaluating urban LLM agent on outcome-level metrics (e.g., prediction accuracy, traffic efficiency), offering limited insight into their underlying reasoning processes. As a result, the strengths and limitations of urban LLM agents in spatiotemporal reasoning remain poorly understood. To this end, we introduce USTBench, the first benchmark to evaluate LLMs' spatiotemporal reasoning abilities as urban agents across four decomposed dimensions: spatiotemporal understanding, forecasting, planning, and reflection with feedback. Specifically, USTBench supports five diverse urban decision-making and four spatiotemporal prediction tasks, all running within our constructed interactive city environment UAgentEnv. The benchmark includes 62,466 structured QA pairs for process-level evaluation and standardized end-to-end task assessments, enabling fine-grained diagnostics and broad task-level comparison across diverse urban scenarios. Through extensive evaluation of thirteen leading LLMs, we reveal that although LLMs show promising potential across various urban downstream tasks, they still struggle in long-horizon planning and reflective adaptation in dynamic urban contexts. Notably, recent advanced reasoning models (e.g., DeepSeek-R1) trained on general logic or mathematical problems do not consistently outperform non-reasoning LLMs. This discrepancy highlights the need for domain-specialized adaptation methods to enhance urban spatiotemporal reasoning. Overall, USTBench provides a foundation to build more adaptive and effective LLM-based urban agents and broad smart city applications.
MM-Agent: LLM as Agents for Real-world Mathematical Modeling Problem
May 20, 2025Mathematical modeling is a cornerstone of scientific discovery and engineering practice, enabling the translation of real-world problems into formal systems across domains such as physics, biology, and economics. Unlike mathematical reasoning, which assumes a predefined formulation, modeling requires open-ended problem analysis, abstraction, and principled formalization. While Large Language Models (LLMs) have shown strong reasoning capabilities, they fall short in rigorous model construction, limiting their utility in real-world problem-solving. To this end, we formalize the task of LLM-powered real-world mathematical modeling, where agents must analyze problems, construct domain-appropriate formulations, and generate complete end-to-end solutions. We introduce MM-Bench, a curated benchmark of 111 problems from the Mathematical Contest in Modeling (MCM/ICM), spanning the years 2000 to 2025 and across ten diverse domains such as physics, biology, and economics. To tackle this task, we propose MM-Agent, an expert-inspired framework that decomposes mathematical modeling into four stages: open-ended problem analysis, structured model formulation, computational problem solving, and report generation. Experiments on MM-Bench show that MM-Agent significantly outperforms baseline agents, achieving an 11.88\% improvement over human expert solutions while requiring only 15 minutes and \$0.88 per task using GPT-4o. Furthermore, under official MCM/ICM protocols, MM-Agent assisted two undergraduate teams in winning the Finalist Award (\textbf{top 2.0\% among 27,456 teams}) in MCM/ICM 2025, demonstrating its practical effectiveness as a modeling copilot. Our code is available at https://github.com/usail-hkust/LLM-MM-Agent
Dolphin: Document Image Parsing via Heterogeneous Anchor Prompting
May 20, 2025Document image parsing is challenging due to its complexly intertwined elements such as text paragraphs, figures, formulas, and tables. Current approaches either assemble specialized expert models or directly generate page-level content autoregressively, facing integration overhead, efficiency bottlenecks, and layout structure degradation despite their decent performance. To address these limitations, we present \textit{Dolphin} (\textit{\textbf{Do}cument Image \textbf{P}arsing via \textbf{H}eterogeneous Anchor Prompt\textbf{in}g}), a novel multimodal document image parsing model following an analyze-then-parse paradigm. In the first stage, Dolphin generates a sequence of layout elements in reading order. These heterogeneous elements, serving as anchors and coupled with task-specific prompts, are fed back to Dolphin for parallel content parsing in the second stage. To train Dolphin, we construct a large-scale dataset of over 30 million samples, covering multi-granularity parsing tasks. Through comprehensive evaluations on both prevalent benchmarks and self-constructed ones, Dolphin achieves state-of-the-art performance across diverse page-level and element-level settings, while ensuring superior efficiency through its lightweight architecture and parallel parsing mechanism. The code and pre-trained models are publicly available at https://github.com/ByteDance/Dolphin
A Token is Worth over 1,000 Tokens: Efficient Knowledge Distillation through Low-Rank Clone
May 19, 2025
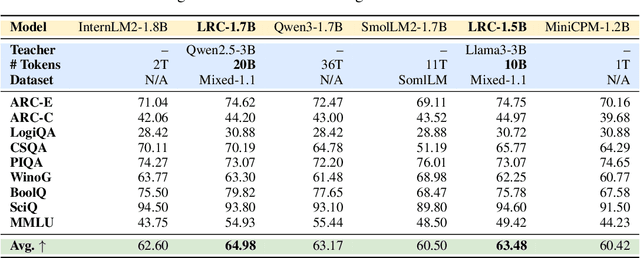
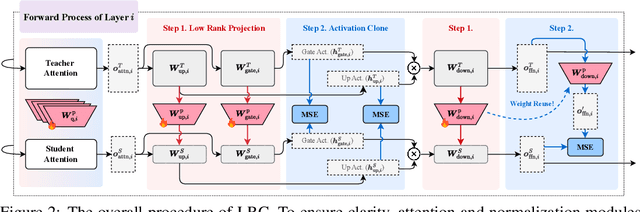
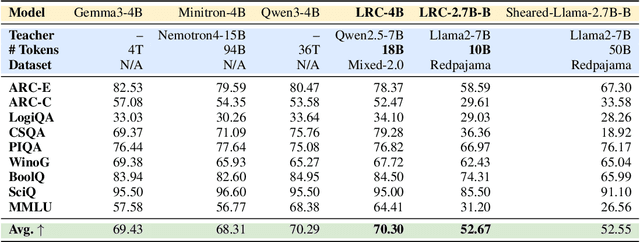
Training high-performing Small Language Models (SLMs) remains costly, even with knowledge distillation and pruning from larger teacher models. Existing work often faces three key challenges: (1) information loss from hard pruning, (2) inefficient alignment of representations, and (3) underutilization of informative activations, particularly from Feed-Forward Networks (FFNs). To address these challenges, we introduce Low-Rank Clone (LRC), an efficient pre-training method that constructs SLMs aspiring to behavioral equivalence with strong teacher models. LRC trains a set of low-rank projection matrices that jointly enable soft pruning by compressing teacher weights, and activation clone by aligning student activations, including FFN signals, with those of the teacher. This unified design maximizes knowledge transfer while removing the need for explicit alignment modules. Extensive experiments with open-source teachers (e.g., Llama-3.2-3B-Instruct, Qwen2.5-3B/7B-Instruct) show that LRC matches or surpasses state-of-the-art models trained on trillions of tokens--while using only 20B tokens, achieving over 1,000x training efficiency. Our codes and model checkpoints are available at https://github.com/CURRENTF/LowRankClone and https://huggingface.co/collections/JitaiHao/low-rank-clone-lrc-6828389e96a93f1d4219dfaf.
PhyDA: Physics-Guided Diffusion Models for Data Assimilation in Atmospheric Systems
May 19, 2025Data Assimilation (DA) plays a critical role in atmospheric science by reconstructing spatially continous estimates of the system state, which serves as initial conditions for scientific analysis. While recent advances in diffusion models have shown great potential for DA tasks, most existing approaches remain purely data-driven and often overlook the physical laws that govern complex atmospheric dynamics. As a result, they may yield physically inconsistent reconstructions that impair downstream applications. To overcome this limitation, we propose PhyDA, a physics-guided diffusion framework designed to ensure physical coherence in atmospheric data assimilation. PhyDA introduces two key components: (1) a Physically Regularized Diffusion Objective that integrates physical constraints into the training process by penalizing deviations from known physical laws expressed as partial differential equations, and (2) a Virtual Reconstruction Encoder that bridges observational sparsity for structured latent representations, further enhancing the model's ability to infer complete and physically coherent states. Experiments on the ERA5 reanalysis dataset demonstrate that PhyDA achieves superior accuracy and better physical plausibility compared to state-of-the-art baselines. Our results emphasize the importance of combining generative modeling with domain-specific physical knowledge and show that PhyDA offers a promising direction for improving real-world data assimilation systems.
Not All Thoughts are Generated Equal: Efficient LLM Reasoning via Multi-Turn Reinforcement Learning
May 17, 2025



Compressing long chain-of-thought (CoT) from large language models (LLMs) is an emerging strategy to improve the reasoning efficiency of LLMs. Despite its promising benefits, existing studies equally compress all thoughts within a long CoT, hindering more concise and effective reasoning. To this end, we first investigate the importance of different thoughts by examining their effectiveness and efficiency in contributing to reasoning through automatic long CoT chunking and Monte Carlo rollouts. Building upon the insights, we propose a theoretically bounded metric to jointly measure the effectiveness and efficiency of different thoughts. We then propose Long$\otimes$Short, an efficient reasoning framework that enables two LLMs to collaboratively solve the problem: a long-thought LLM for more effectively generating important thoughts, while a short-thought LLM for efficiently generating remaining thoughts. Specifically, we begin by synthesizing a small amount of cold-start data to fine-tune LLMs for long-thought and short-thought reasoning styles, respectively. Furthermore, we propose a synergizing-oriented multi-turn reinforcement learning, focusing on the model self-evolution and collaboration between long-thought and short-thought LLMs. Experimental results show that our method enables Qwen2.5-7B and Llama3.1-8B to achieve comparable performance compared to DeepSeek-R1-Distill-Qwen-7B and DeepSeek-R1-Distill-Llama-8B, while reducing token length by over 80% across the MATH500, AIME24/25, AMC23, and GPQA Diamond benchmarks. Our data and code are available at https://github.com/yasNing/Long-otimes-Short/.
SongEval: A Benchmark Dataset for Song Aesthetics Evaluation
May 16, 2025Aesthetics serve as an implicit and important criterion in song generation tasks that reflect human perception beyond objective metrics. However, evaluating the aesthetics of generated songs remains a fundamental challenge, as the appreciation of music is highly subjective. Existing evaluation metrics, such as embedding-based distances, are limited in reflecting the subjective and perceptual aspects that define musical appeal. To address this issue, we introduce SongEval, the first open-source, large-scale benchmark dataset for evaluating the aesthetics of full-length songs. SongEval includes over 2,399 songs in full length, summing up to more than 140 hours, with aesthetic ratings from 16 professional annotators with musical backgrounds. Each song is evaluated across five key dimensions: overall coherence, memorability, naturalness of vocal breathing and phrasing, clarity of song structure, and overall musicality. The dataset covers both English and Chinese songs, spanning nine mainstream genres. Moreover, to assess the effectiveness of song aesthetic evaluation, we conduct experiments using SongEval to predict aesthetic scores and demonstrate better performance than existing objective evaluation metrics in predicting human-perceived musical quality.
WildDoc: How Far Are We from Achieving Comprehensive and Robust Document Understanding in the Wild?
May 16, 2025The rapid advancements in Multimodal Large Language Models (MLLMs) have significantly enhanced capabilities in Document Understanding. However, prevailing benchmarks like DocVQA and ChartQA predominantly comprise \textit{scanned or digital} documents, inadequately reflecting the intricate challenges posed by diverse real-world scenarios, such as variable illumination and physical distortions. This paper introduces WildDoc, the inaugural benchmark designed specifically for assessing document understanding in natural environments. WildDoc incorporates a diverse set of manually captured document images reflecting real-world conditions and leverages document sources from established benchmarks to facilitate comprehensive comparisons with digital or scanned documents. Further, to rigorously evaluate model robustness, each document is captured four times under different conditions. Evaluations of state-of-the-art MLLMs on WildDoc expose substantial performance declines and underscore the models' inadequate robustness compared to traditional benchmarks, highlighting the unique challenges posed by real-world document understanding. Our project homepage is available at https://bytedance.github.io/WildDoc.
Automated Parking Trajectory Generation Using Deep Reinforcement Learning
Apr 29, 2025



Autonomous parking is a key technology in modern autonomous driving systems, requiring high precision, strong adaptability, and efficiency in complex environments. This paper proposes a Deep Reinforcement Learning (DRL) framework based on the Soft Actor-Critic (SAC) algorithm to optimize autonomous parking tasks. SAC, an off-policy method with entropy regularization, is particularly well-suited for continuous action spaces, enabling fine-grained vehicle control. We model the parking task as a Markov Decision Process (MDP) and train an agent to maximize cumulative rewards while balancing exploration and exploitation through entropy maximization. The proposed system integrates multiple sensor inputs into a high-dimensional state space and leverages SAC's dual critic networks and policy network to achieve stable learning. Simulation results show that the SAC-based approach delivers high parking success rates, reduced maneuver times, and robust handling of dynamic obstacles, outperforming traditional rule-based methods and other DRL algorithms. This study demonstrates SAC's potential in autonomous parking and lays the foundation for real-world applications.
Robust Transmission Design for Reconfigurable Intelligent Surface and Movable Antenna Enabled Symbiotic Radio Communications
Apr 23, 2025



This paper explores the application of movable antenna (MA), a cutting-edge technology with the capability of altering antenna positions, in a symbiotic radio (SR) system enabled by reconfigurable intelligent surface (RIS). The goal is to fully exploit the capabilities of both MA and RIS, constructing a better transmission environment for the co-existing primary and secondary transmission systems. For both parasitic SR (PSR) and commensal SR (CSR) scenarios with the channel uncertainties experienced by all transmission links, we design a robust transmission scheme with the goal of maximizing the primary rate while ensuring the secondary transmission quality. To address the maximization problem with thorny non-convex characteristics, we propose an alternating optimization framework that utilizes the General S-Procedure, General Sign-Definiteness Principle, successive convex approximation (SCA), and simulated annealing (SA) improved particle swarm optimization (SA-PSO) algorithms. Numerical results validate that the CSR scenario significantly outperforms the PSR scenario in terms of primary rate, and also show that compared to the fixed-position antenna scheme, the proposed MA scheme can increase the primary rate by 1.62 bps/Hz and 2.37 bps/Hz for the PSR and CSR scenarios, respectively.