 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniScale: Synergistic Entire Space Data and Model Scaling for Search Ranking
Mar 25, 2026Recent advances in Large Language Models (LLMs) have inspired a surge of scaling law research in industrial search, advertising, and recommendation systems. However, existing approaches focus mainly on architectural improvements, overlooking the critical synergy between data and architecture design. We observe that scaling model parameters alone exhibits diminishing returns, i.e., the marginal gain in performance steadily declines as model size increases, and that the performance degradation caused by complex heterogeneous data distributions is often irrecoverable through model design alone. In this paper, we propose UniScale to address these limitation, a novel co-design framework that jointly optimizes data and architecture to unlock the full potential of model scaling, which includes two core parts: (1) ES$^3$ (Entire-Space Sample System), a high-quality data scaling system that expands the training signal beyond conventional sampling strategies from both intra-domain request contexts with global supervised signal constructed by hierarchical label attribution and cross-domain samples aligning with the essence of user decision under similar content exposure environment in search domain; and (2) HHSFT (Heterogeneous Hierarchical Sample Fusion Transformer), a novel architecture designed to effectively model the complex heterogeneous distribution of scaled data and to harness the entire space user behavior data with Heterogeneous Hierarchical Feature Interaction and Entire Space User Interest Fusion, thereby surpassing the performance ceiling of structure-only model tuning. Extensive experiments on large-scale real world E-commerce search platform demonstrate that UniScale achieves significant improvements through the synergistic co-design of data and architecture and exhibits clear scaling trends, delivering substantial gains in key business metrics.
KARMA: Knowledge-Action Regularized Multimodal Alignment for Personalized Search at Taobao
Mar 24, 2026Large Language Models (LLMs) are equipped with profound semantic knowledge, making them a natural choice for injecting semantic generalization into personalized search systems. However, in practice we find that directly fine-tuning LLMs on industrial personalized tasks (e.g. next item prediction) often yields suboptimal results. We attribute this bottleneck to a critical Knowledge--Action Gap: the inherent conflict between preserving pre-trained semantic knowledge and aligning with specific personalized actions by discriminative objectives. Empirically, action-only training objectives induce Semantic Collapse, such as attention ``sinks''. This degradation severely cripples the LLM's generalization, failing to bring improvements to personalized search systems. We propose KARMA (Knowledge--Action Regularized Multimodal Alignment), a unified framework that treats semantic reconstruction as a train-only regularizer. KARMA optimizes a next-interest embedding for retrieval (Action) while enforcing semantic decodability (Knowledge) through two complementary objectives: (i) history-conditioned semantic generation, which anchors optimization to the LLM's native next-token distribution, and (ii) embedding-conditioned semantic reconstruction, which constrains the interest embedding to remain semantically recoverable. On Taobao search system, KARMA mitigates semantic collapse (attention-sink analysis) and improves both action metrics and semantic fidelity. In ablations, semantic decodability yields up to +22.5 HR@200. With KARMA, we achieve +0.25 CTR AUC in ranking, +1.86 HR in pre-ranking and +2.51 HR in recalling. Deployed online with low inference overhead at ranking stage, KARMA drives +0.5% increase in Item Click.
AIGQ: An End-to-End Hybrid Generative Architecture for E-commerce Query Recommendation
Mar 20, 2026Pre-search query recommendation, widely known as HintQ on Taobao's homepage, plays a vital role in intent capture and demand discovery, yet traditional methods suffer from shallow semantics, poor cold-start performance and low serendipity due to reliance on ID-based matching and co-click heuristics. To overcome these challenges, we propose AIGQ (AI-Generated Query architecture), the first end-to-end generative framework for HintQ scenario. AIGQ is built upon three core innovations spanning training paradigm, policy optimization and deployment architecture. First, we propose Interest-Aware List Supervised Fine-Tuning (IL-SFT), a list-level supervised learning approach that constructs training samples through session-aware behavior aggregation and interest-guided re-ranking strategy to faithfully model nuanced user intent. Accordingly, we design Interest-aware List Group Relative Policy Optimization (IL-GRPO), a novel policy gradient algorithm with a dual-component reward mechanism that jointly optimizes individual query relevance and global list properties, enhanced by a model-based reward from the online click-through rate (CTR) ranking model. To deploy under strict real-time and low-latency requirements, we further develop a hybrid offline-online architecture comprising AIGQ-Direct for nearline personalized user-to-query generation and AIGQ-Think, a reasoning-enhanced variant that produces trigger-to-query mappings to enrich interest diversity. Extensive offline evaluations and large-scale online A/B experiments on Taobao demonstrate that AIGQ consistently delivers substantial improvements in key business metrics across platform effectiveness and user engagement.
Synthetic Data Powers Product Retrieval for Long-tail Knowledge-Intensive Queries in E-commerce Search
Feb 27, 2026Product retrieval is the backbone of e-commerce search: for each user query, it identifies a high-recall candidate set from billions of items, laying the foundation for high-quality ranking and user experience. Despite extensive optimization for mainstream queries, existing systems still struggle with long-tail queries, especially knowledge-intensive ones. These queries exhibit diverse linguistic patterns, often lack explicit purchase intent, and require domain-specific knowledge reasoning for accurate interpretation. They also suffer from a shortage of reliable behavioral logs, which makes such queries a persistent challenge for retrieval optimization. To address these issues, we propose an efficient data synthesis framework tailored to retrieval involving long-tail, knowledge-intensive queries. The key idea is to implicitly distill the capabilities of a powerful offline query-rewriting model into an efficient online retrieval system. Leveraging the strong language understanding of LLMs, we train a multi-candidate query rewriting model with multiple reward signals and capture its rewriting capability in well-curated query-product pairs through a powerful offline retrieval pipeline. This design mitigates distributional shift in rewritten queries, which might otherwise limit incremental recall or introduce irrelevant products. Experiments demonstrate that without any additional tricks, simply incorporating this synthetic data into retrieval model training leads to significant improvements. Online Side-By-Side (SBS) human evaluation results indicate a notable enhancement in user search experience.
TaoSearchEmb: A Multi-Objective Reinforcement Learning Framework for Dense Retrieval in Taobao Search
Nov 17, 2025Dense retrieval, as the core component of e-commerce search engines, maps user queries and items into a unified semantic space through pre-trained embedding models to enable large-scale real-time semantic retrieval. Despite the rapid advancement of LLMs gradually replacing traditional BERT architectures for embedding, their training paradigms still adhere to BERT-like supervised fine-tuning and hard negative mining strategies. This approach relies on complex offline hard negative sample construction pipelines, which constrain model iteration efficiency and hinder the evolutionary potential of semantic representation capabilities. Besides, existing multi-task learning frameworks face the seesaw effect when simultaneously optimizing semantic relevance and non-relevance objectives. In this paper, we propose Retrieval-GRPO, a multi-objective reinforcement learning-based dense retrieval framework designed to address these challenges. The method eliminates offline hard negative sample construction by dynamically retrieving Top-K candidate products for each query during training, while introducing a relevance LLM as a reward model to generate real-time feedback. Specifically, the retrieval model dynamically optimizes embedding representations through reinforcement learning, with reward signals combining LLM-generated relevance scores, product quality scores, and multi-way exclusivity metrics to achieve multi-objective user preference alignment and real-time error correction. This mechanism not only removes dependency on hard negatives but also mitigates the seesaw effect through collaborative multi-objective optimization, significantly enhancing the model's semantic generalization capability for complex long-tail queries. Extensive offline and online experiments validate the effectiveness of Retrieval-GRPO, which has been deployed on China's largest e-commerce platform.
TaoSR-SHE: Stepwise Hybrid Examination Reinforcement Learning Framework for E-commerce Search Relevance
Oct 09, 2025Query-product relevance analysis is a foundational technology in e-commerce search engines and has become increasingly important in AI-driven e-commerce. The recent emergence of large language models (LLMs), particularly their chain-of-thought (CoT) reasoning capabilities, offers promising opportunities for developing relevance systems that are both more interpretable and more robust. However, existing training paradigms have notable limitations: SFT and DPO suffer from poor generalization on long-tail queries and from a lack of fine-grained, stepwise supervision to enforce rule-aligned reasoning. In contrast, reinforcement learning with verification rewards (RLVR) suffers from sparse feedback, which provides insufficient signal to correct erroneous intermediate steps, thereby undermining logical consistency and limiting performance in complex inference scenarios. To address these challenges, we introduce the Stepwise Hybrid Examination Reinforcement Learning framework for Taobao Search Relevance (TaoSR-SHE). At its core is Stepwise Reward Policy Optimization (SRPO), a reinforcement learning algorithm that leverages step-level rewards generated by a hybrid of a high-quality generative stepwise reward model and a human-annotated offline verifier, prioritizing learning from critical correct and incorrect reasoning steps. TaoSR-SHE further incorporates two key techniques: diversified data filtering to encourage exploration across varied reasoning paths and mitigate policy entropy collapse, and multi-stage curriculum learning to foster progressive capability growth. Extensive experiments on real-world search benchmarks show that TaoSR-SHE improves both reasoning quality and relevance-prediction accuracy in large-scale e-commerce settings, outperforming SFT, DPO, GRPO, and other baselines, while also enhancing interpretability and robustness.
TaoSR-AGRL: Adaptive Guided Reinforcement Learning Framework for E-commerce Search Relevance
Oct 09, 2025Query-product relevance prediction is fundamental to e-commerce search and has become even more critical in the era of AI-powered shopping, where semantic understanding and complex reasoning directly shape the user experience and business conversion. Large Language Models (LLMs) enable generative, reasoning-based approaches, typically aligned via supervised fine-tuning (SFT) or preference optimization methods like Direct Preference Optimization (DPO). However, the increasing complexity of business rules and user queries exposes the inability of existing methods to endow models with robust reasoning capacity for long-tail and challenging cases. Efforts to address this via reinforcement learning strategies like Group Relative Policy Optimization (GRPO) often suffer from sparse terminal rewards, offering insufficient guidance for multi-step reasoning and slowing convergence. To address these challenges, we propose TaoSR-AGRL, an Adaptive Guided Reinforcement Learning framework for LLM-based relevance prediction in Taobao Search Relevance. TaoSR-AGRL introduces two key innovations: (1) Rule-aware Reward Shaping, which decomposes the final relevance judgment into dense, structured rewards aligned with domain-specific relevance criteria; and (2) Adaptive Guided Replay, which identifies low-accuracy rollouts during training and injects targeted ground-truth guidance to steer the policy away from stagnant, rule-violating reasoning patterns toward compliant trajectories. TaoSR-AGRL was evaluated on large-scale real-world datasets and through online side-by-side human evaluations on Taobao Search. It consistently outperforms DPO and standard GRPO baselines in offline experiments, improving relevance accuracy, rule adherence, and training stability. The model trained with TaoSR-AGRL has been successfully deployed in the main search scenario on Taobao, serving hundreds of millions of users.
TaoSR1: The Thinking Model for E-commerce Relevance Search
Aug 17, 2025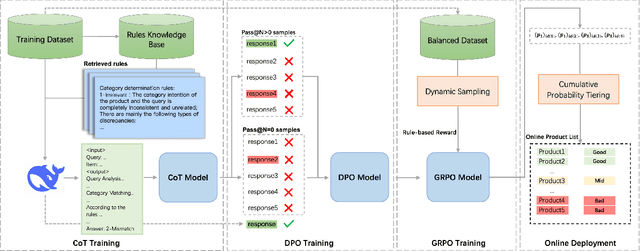
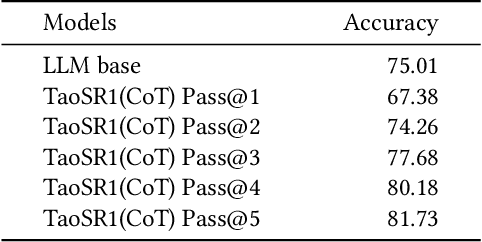
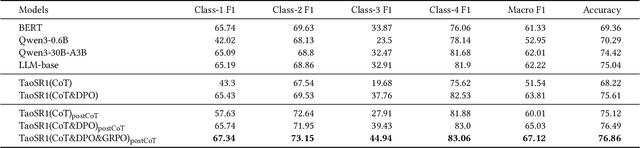
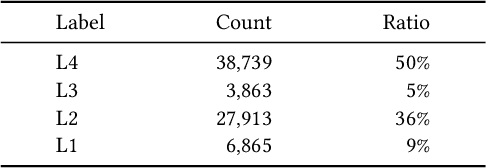
Query-product relevance prediction is a core task in e-commerce search. BERT-based models excel at semantic matching but lack complex reasoning capabilities. While Large Language Models (LLMs) are explored, most still use discriminative fine-tuning or distill to smaller models for deployment. We propose a framework to directly deploy LLMs for this task, addressing key challenges: Chain-of-Thought (CoT) error accumulation, discriminative hallucination, and deployment feasibility. Our framework, TaoSR1, involves three stages: (1) Supervised Fine-Tuning (SFT) with CoT to instill reasoning; (2) Offline sampling with a pass@N strategy and Direct Preference Optimization (DPO) to improve generation quality; and (3) Difficulty-based dynamic sampling with Group Relative Policy Optimization (GRPO) to mitigate discriminative hallucination. Additionally, post-CoT processing and a cumulative probability-based partitioning method enable efficient online deployment. TaoSR1 significantly outperforms baselines on offline datasets and achieves substantial gains in online side-by-side human evaluations, introducing a novel paradigm for applying CoT reasoning to relevance classification.
PUMGPT: A Large Vision-Language Model for Product Understanding
Aug 18, 2023Recent developments of multi-modal large language models have demonstrated its strong ability in solving vision-language tasks. In this paper, we focus on the product understanding task, which plays an essential role in enhancing online shopping experience. Product understanding task includes a variety of sub-tasks, which require models to respond diverse queries based on multi-modal product information. Traditional methods design distinct model architectures for each sub-task. On the contrary, we present PUMGPT, a large vision-language model aims at unifying all product understanding tasks under a singular model structure. To bridge the gap between vision and text representations, we propose Layer-wise Adapters (LA), an approach that provides enhanced alignment with fewer visual tokens and enables parameter-efficient fine-tuning. Moreover, the inherent parameter-efficient fine-tuning ability allows PUMGPT to be readily adapted to new product understanding tasks and emerging products. We design instruction templates to generate diverse product instruction datasets. Simultaneously, we utilize open-domain datasets during training to improve the performance of PUMGPT and its generalization ability. Through extensive evaluations, PUMGPT demonstrates its superior performance across multiple product understanding tasks, including product captioning, category question-answering, attribute extraction, attribute question-answering, and even free-form question-answering about products.
Improving Text Matching in E-Commerce Search with A Rationalizable, Intervenable and Fast Entity-Based Relevance Model
Jul 01, 2023



Discovering the intended items of user queries from a massive repository of items is one of the main goals of an e-commerce search system. Relevance prediction is essential to the search system since it helps improve performance. When online serving a relevance model, the model is required to perform fast and accurate inference. Currently, the widely used models such as Bi-encoder and Cross-encoder have their limitations in accuracy or inference speed respectively. In this work, we propose a novel model called the Entity-Based Relevance Model (EBRM). We identify the entities contained in an item and decompose the QI (query-item) relevance problem into multiple QE (query-entity) relevance problems; we then aggregate their results to form the QI prediction using a soft logic formulation. The decomposition allows us to use a Cross-encoder QE relevance module for high accuracy as well as cache QE predictions for fast online inference. Utilizing soft logic makes the prediction procedure interpretable and intervenable. We also show that pretraining the QE module with auto-generated QE data from user logs can further improve the overall performance. The proposed method is evaluated on labeled data from e-commerce websites. Empirical results show that it achieves promising improvements with computation efficiency.