 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery-Mixed Interest Extraction and Heterogeneous Interaction: A Scalable CTR Model for Industrial Recommender Systems
Feb 12, 2026Learning effective feature interactions is central to modern recommender systems, yet remains challenging in industrial settings due to sparse multi-field inputs and ultra-long user behavior sequences. While recent scaling efforts have improved model capacity, they often fail to construct both context-aware and context-independent user intent from the long-term and real-time behavior sequence. Meanwhile, recent work also suffers from inefficient and homogeneous interaction mechanisms, leading to suboptimal prediction performance. To address these limitations, we propose HeMix, a scalable ranking model that unifies adaptive sequence tokenization and heterogeneous interaction structure. Specifically, HeMix introduces a Query-Mixed Interest Extraction module that jointly models context-aware and context-independent user interests via dynamic and fixed queries over global and real-time behavior sequences. For interaction, we replace self-attention with the HeteroMixer block, enabling efficient, multi-granularity cross-feature interactions that adopt the multi-head token fusion, heterogeneous interaction and group-aligned reconstruction pipelines. HeMix demonstrates favorable scaling behavior, driven by the HeteroMixer block, where increasing model scale via parameter expansion leads to steady improvements in recommendation accuracy. Experiments on industrial-scale datasets show that HeMix scales effectively and consistently outperforms strong baselines. Most importantly, HeMix has been deployed on the AMAP platform, delivering significant online gains over DLRM: +3.61\% GMV, +2.78\% PV\_CTR, and +2.12\% UV\_CVR.
GeoGR: A Generative Retrieval Framework for Spatio-Temporal Aware POI Recommendation
Feb 11, 2026Next Point-of-Interest (POI) prediction is a fundamental task in location-based services, especially critical for large-scale navigation platforms like AMAP that serve billions of users across diverse lifestyle scenarios. While recent POI recommendation approaches based on SIDs have achieved promising, they struggle in complex, sparse real-world environments due to two key limitations: (1) inadequate modeling of high-quality SIDs that capture cross-category spatio-temporal collaborative relationships, and (2) poor alignment between large language models (LLMs) and the POI recommendation task. To this end, we propose GeoGR, a geographic generative recommendation framework tailored for navigation-based LBS like AMAP, which perceives users' contextual state changes and enables intent-aware POI recommendation. GeoGR features a two-stage design: (i) a geo-aware SID tokenization pipeline that explicitly learns spatio-temporal collaborative semantic representations via geographically constrained co-visited POI pairs, contrastive learning, and iterative refinement; and (ii) a multi-stage LLM training strategy that aligns non-native SID tokens through multiple template-based continued pre-training(CPT) and enables autoregressive POI generation via supervised fine-tuning(SFT). Extensive experiments on multiple real-world datasets demonstrate GeoGR's superiority over state-of-the-art baselines. Moreover, deployment on the AMAP platform, serving millions of users with multiple online metrics boosting, confirms its practical effectiveness and scalability in production.
TaoSR-SHE: Stepwise Hybrid Examination Reinforcement Learning Framework for E-commerce Search Relevance
Oct 09, 2025Query-product relevance analysis is a foundational technology in e-commerce search engines and has become increasingly important in AI-driven e-commerce. The recent emergence of large language models (LLMs), particularly their chain-of-thought (CoT) reasoning capabilities, offers promising opportunities for developing relevance systems that are both more interpretable and more robust. However, existing training paradigms have notable limitations: SFT and DPO suffer from poor generalization on long-tail queries and from a lack of fine-grained, stepwise supervision to enforce rule-aligned reasoning. In contrast, reinforcement learning with verification rewards (RLVR) suffers from sparse feedback, which provides insufficient signal to correct erroneous intermediate steps, thereby undermining logical consistency and limiting performance in complex inference scenarios. To address these challenges, we introduce the Stepwise Hybrid Examination Reinforcement Learning framework for Taobao Search Relevance (TaoSR-SHE). At its core is Stepwise Reward Policy Optimization (SRPO), a reinforcement learning algorithm that leverages step-level rewards generated by a hybrid of a high-quality generative stepwise reward model and a human-annotated offline verifier, prioritizing learning from critical correct and incorrect reasoning steps. TaoSR-SHE further incorporates two key techniques: diversified data filtering to encourage exploration across varied reasoning paths and mitigate policy entropy collapse, and multi-stage curriculum learning to foster progressive capability growth. Extensive experiments on real-world search benchmarks show that TaoSR-SHE improves both reasoning quality and relevance-prediction accuracy in large-scale e-commerce settings, outperforming SFT, DPO, GRPO, and other baselines, while also enhancing interpretability and robustness.
TaoSR-AGRL: Adaptive Guided Reinforcement Learning Framework for E-commerce Search Relevance
Oct 09, 2025Query-product relevance prediction is fundamental to e-commerce search and has become even more critical in the era of AI-powered shopping, where semantic understanding and complex reasoning directly shape the user experience and business conversion. Large Language Models (LLMs) enable generative, reasoning-based approaches, typically aligned via supervised fine-tuning (SFT) or preference optimization methods like Direct Preference Optimization (DPO). However, the increasing complexity of business rules and user queries exposes the inability of existing methods to endow models with robust reasoning capacity for long-tail and challenging cases. Efforts to address this via reinforcement learning strategies like Group Relative Policy Optimization (GRPO) often suffer from sparse terminal rewards, offering insufficient guidance for multi-step reasoning and slowing convergence. To address these challenges, we propose TaoSR-AGRL, an Adaptive Guided Reinforcement Learning framework for LLM-based relevance prediction in Taobao Search Relevance. TaoSR-AGRL introduces two key innovations: (1) Rule-aware Reward Shaping, which decomposes the final relevance judgment into dense, structured rewards aligned with domain-specific relevance criteria; and (2) Adaptive Guided Replay, which identifies low-accuracy rollouts during training and injects targeted ground-truth guidance to steer the policy away from stagnant, rule-violating reasoning patterns toward compliant trajectories. TaoSR-AGRL was evaluated on large-scale real-world datasets and through online side-by-side human evaluations on Taobao Search. It consistently outperforms DPO and standard GRPO baselines in offline experiments, improving relevance accuracy, rule adherence, and training stability. The model trained with TaoSR-AGRL has been successfully deployed in the main search scenario on Taobao, serving hundreds of millions of users.
TaoSR1: The Thinking Model for E-commerce Relevance Search
Aug 17, 2025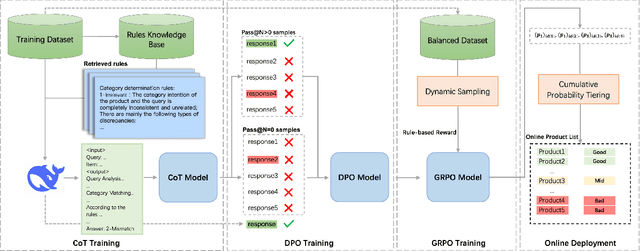
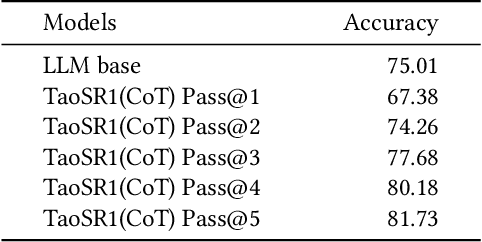
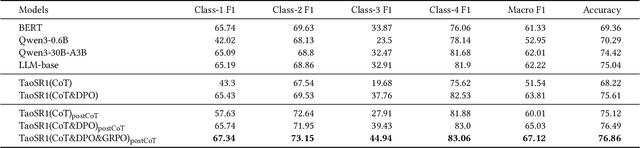
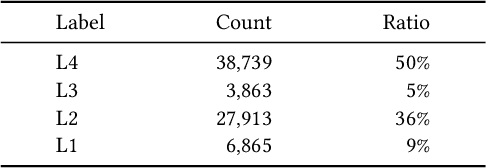
Query-product relevance prediction is a core task in e-commerce search. BERT-based models excel at semantic matching but lack complex reasoning capabilities. While Large Language Models (LLMs) are explored, most still use discriminative fine-tuning or distill to smaller models for deployment. We propose a framework to directly deploy LLMs for this task, addressing key challenges: Chain-of-Thought (CoT) error accumulation, discriminative hallucination, and deployment feasibility. Our framework, TaoSR1, involves three stages: (1) Supervised Fine-Tuning (SFT) with CoT to instill reasoning; (2) Offline sampling with a pass@N strategy and Direct Preference Optimization (DPO) to improve generation quality; and (3) Difficulty-based dynamic sampling with Group Relative Policy Optimization (GRPO) to mitigate discriminative hallucination. Additionally, post-CoT processing and a cumulative probability-based partitioning method enable efficient online deployment. TaoSR1 significantly outperforms baselines on offline datasets and achieves substantial gains in online side-by-side human evaluations, introducing a novel paradigm for applying CoT reasoning to relevance classification.
AutoFAS: Automatic Feature and Architecture Selection for Pre-Ranking System
May 19, 2022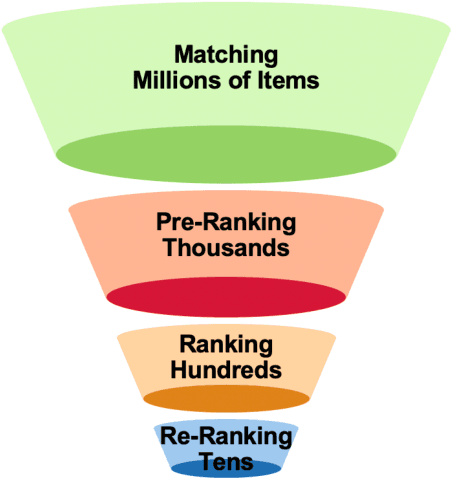
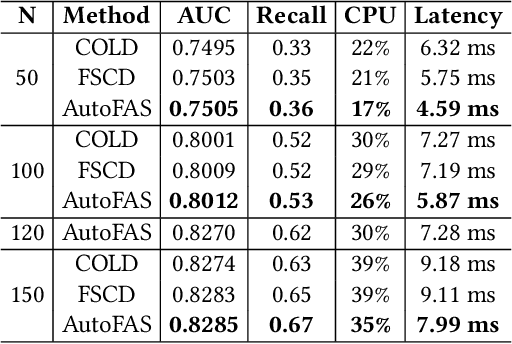
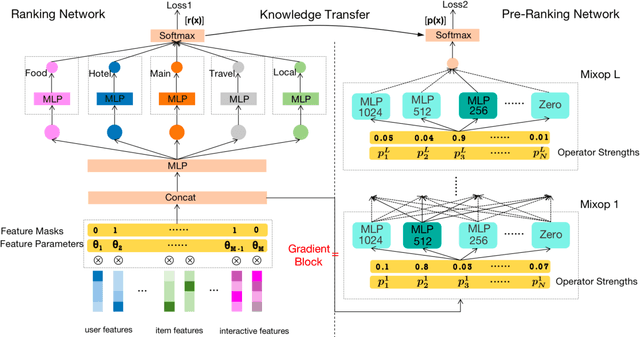

Industrial search and recommendation systems mostly follow the classic multi-stage information retrieval paradigm: matching, pre-ranking, ranking, and re-ranking stages. To account for system efficiency, simple vector-product based models are commonly deployed in the pre-ranking stage. Recent works consider distilling the high knowledge of large ranking models to small pre-ranking models for better effectiveness. However, two major challenges in pre-ranking system still exist: (i) without explicitly modeling the performance gain versus computation cost, the predefined latency constraint in the pre-ranking stage inevitably leads to suboptimal solutions; (ii) transferring the ranking teacher's knowledge to a pre-ranking student with a predetermined handcrafted architecture still suffers from the loss of model performance. In this work, a novel framework AutoFAS is proposed which jointly optimizes the efficiency and effectiveness of the pre-ranking model: (i) AutoFAS for the first time simultaneously selects the most valuable features and network architectures using Neural Architecture Search (NAS) technique; (ii) equipped with ranking model guided reward during NAS procedure, AutoFAS can select the best pre-ranking architecture for a given ranking teacher without any computation overhead. Experimental results in our real world search system show AutoFAS consistently outperforms the previous state-of-the-art (SOTA) approaches at a lower computing cost. Notably, our model has been adopted in the pre-ranking module in the search system of Meituan, bringing significant improvements.