 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniScale: Synergistic Entire Space Data and Model Scaling for Search Ranking
Mar 25, 2026Recent advances in Large Language Models (LLMs) have inspired a surge of scaling law research in industrial search, advertising, and recommendation systems. However, existing approaches focus mainly on architectural improvements, overlooking the critical synergy between data and architecture design. We observe that scaling model parameters alone exhibits diminishing returns, i.e., the marginal gain in performance steadily declines as model size increases, and that the performance degradation caused by complex heterogeneous data distributions is often irrecoverable through model design alone. In this paper, we propose UniScale to address these limitation, a novel co-design framework that jointly optimizes data and architecture to unlock the full potential of model scaling, which includes two core parts: (1) ES$^3$ (Entire-Space Sample System), a high-quality data scaling system that expands the training signal beyond conventional sampling strategies from both intra-domain request contexts with global supervised signal constructed by hierarchical label attribution and cross-domain samples aligning with the essence of user decision under similar content exposure environment in search domain; and (2) HHSFT (Heterogeneous Hierarchical Sample Fusion Transformer), a novel architecture designed to effectively model the complex heterogeneous distribution of scaled data and to harness the entire space user behavior data with Heterogeneous Hierarchical Feature Interaction and Entire Space User Interest Fusion, thereby surpassing the performance ceiling of structure-only model tuning. Extensive experiments on large-scale real world E-commerce search platform demonstrate that UniScale achieves significant improvements through the synergistic co-design of data and architecture and exhibits clear scaling trends, delivering substantial gains in key business metrics.
KARMA: Knowledge-Action Regularized Multimodal Alignment for Personalized Search at Taobao
Mar 24, 2026Large Language Models (LLMs) are equipped with profound semantic knowledge, making them a natural choice for injecting semantic generalization into personalized search systems. However, in practice we find that directly fine-tuning LLMs on industrial personalized tasks (e.g. next item prediction) often yields suboptimal results. We attribute this bottleneck to a critical Knowledge--Action Gap: the inherent conflict between preserving pre-trained semantic knowledge and aligning with specific personalized actions by discriminative objectives. Empirically, action-only training objectives induce Semantic Collapse, such as attention ``sinks''. This degradation severely cripples the LLM's generalization, failing to bring improvements to personalized search systems. We propose KARMA (Knowledge--Action Regularized Multimodal Alignment), a unified framework that treats semantic reconstruction as a train-only regularizer. KARMA optimizes a next-interest embedding for retrieval (Action) while enforcing semantic decodability (Knowledge) through two complementary objectives: (i) history-conditioned semantic generation, which anchors optimization to the LLM's native next-token distribution, and (ii) embedding-conditioned semantic reconstruction, which constrains the interest embedding to remain semantically recoverable. On Taobao search system, KARMA mitigates semantic collapse (attention-sink analysis) and improves both action metrics and semantic fidelity. In ablations, semantic decodability yields up to +22.5 HR@200. With KARMA, we achieve +0.25 CTR AUC in ranking, +1.86 HR in pre-ranking and +2.51 HR in recalling. Deployed online with low inference overhead at ranking stage, KARMA drives +0.5% increase in Item Click.
SeedGNN: Graph Neural Networks for Supervised Seeded Graph Matching
May 26, 2022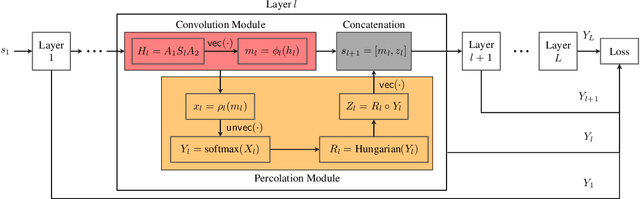
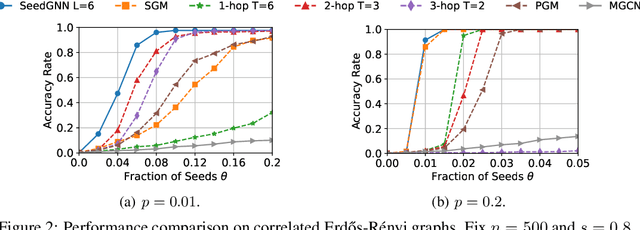
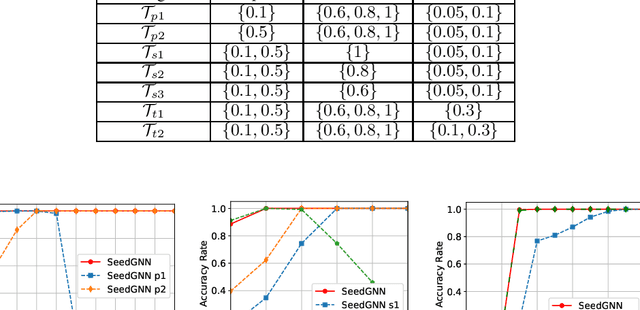
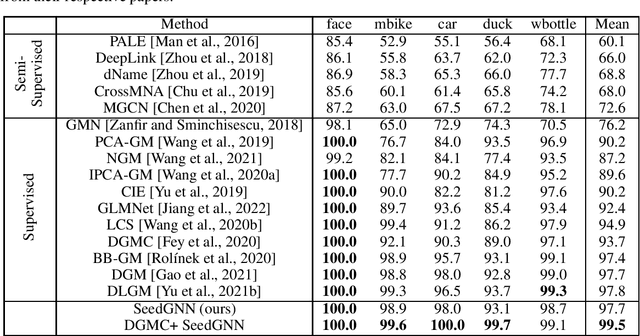
Recently, there have been significant interests in designing Graph Neural Networks (GNNs) for seeded graph matching, which aims to match two (unlabeled) graphs using only topological information and a small set of seeds. However, most previous GNN architectures for seeded graph matching employ a semi-supervised approach, which learns from only the seed set in a single pair of graphs, and therefore does not attempt to learn from many training examples/graphs to best match future unseen graphs. In contrast, this paper is the first to propose a supervised approach for seeded graph matching, which had so far only been used for seedless graph matching. Our proposed SeedGNN architecture employs a number of novel design choices that are inspired by theoretical studies of seeded graph matching. First, SeedGNN can easily learn the capability of counting and using witnesses of different hops, in a way that can be generalized to graphs with different sizes. Second, SeedGNN can use easily-matched pairs as new seeds to percolate and match other nodes. We evaluate SeedGNN on both synthetic and real graphs, and demonstrate significant performance improvement over both non-learning and learning algorithms in the existing literature. Further, our experiments confirm that the knowledge learned by SeedGNN from training graphs can be generalized to test graphs with different sizes and categories.
The Power of $D$-hops in Matching Power-Law Graphs
Feb 23, 2021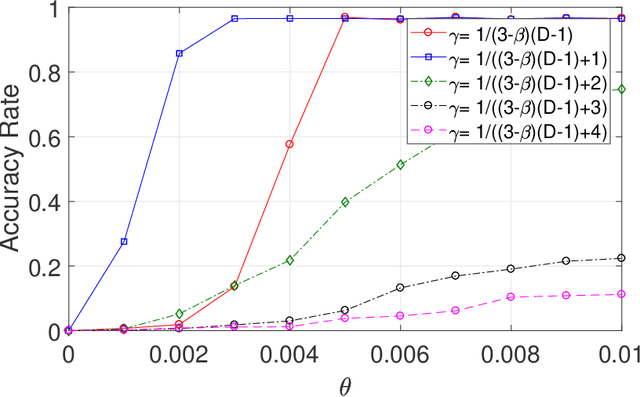
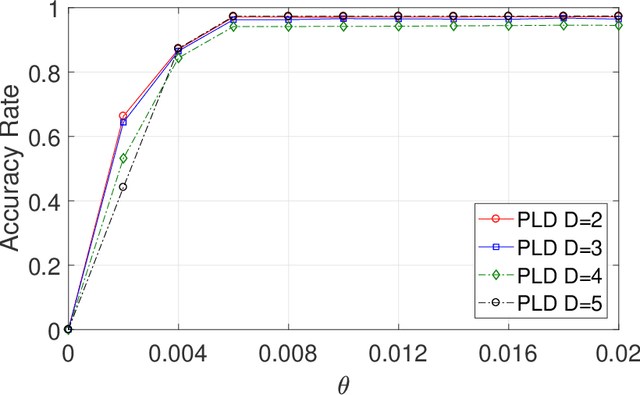
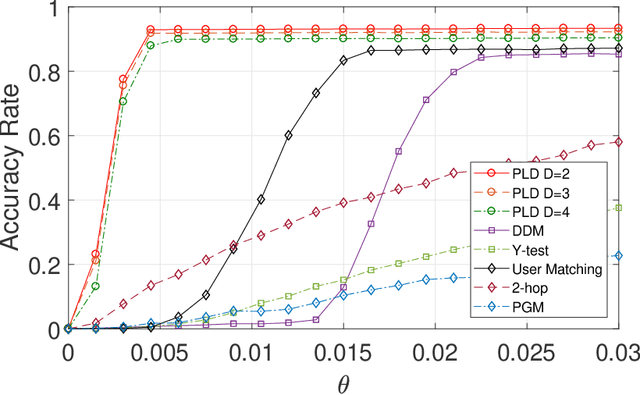
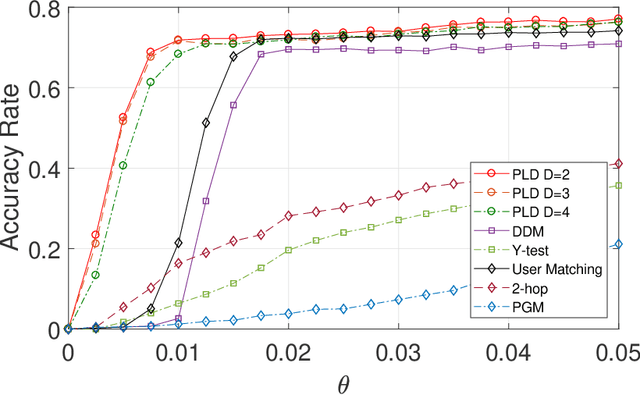
This paper studies seeded graph matching for power-law graphs. Assume that two edge-correlated graphs are independently edge-sampled from a common parent graph with a power-law degree distribution. A set of correctly matched vertex-pairs is chosen at random and revealed as initial seeds. Our goal is to use the seeds to recover the remaining latent vertex correspondence between the two graphs. Departing from the existing approaches that focus on the use of high-degree seeds in $1$-hop neighborhoods, we develop an efficient algorithm that exploits the low-degree seeds in suitably-defined $D$-hop neighborhoods. Specifically, we first match a set of vertex-pairs with appropriate degrees (which we refer to as the first slice) based on the number of low-degree seeds in their $D$-hop neighborhoods. This significantly reduces the number of initial seeds needed to trigger a cascading process to match the rest of the graphs. Under the Chung-Lu random graph model with $n$ vertices, max degree $\Theta(\sqrt{n})$, and the power-law exponent $2<\beta<3$, we show that as soon as $D> \frac{4-\beta}{3-\beta}$, by optimally choosing the first slice, with high probability our algorithm can correctly match a constant fraction of the true pairs without any error, provided with only $\Omega((\log n)^{4-\beta})$ initial seeds. Our result achieves an exponential reduction in the seed size requirement, as the best previously known result requires $n^{1/2+\epsilon}$ seeds (for any small constant $\epsilon>0$). Performance evaluation with synthetic and real data further corroborates the improved performance of our algorithm.
Graph Matching with Partially-Correct Seeds
Apr 08, 2020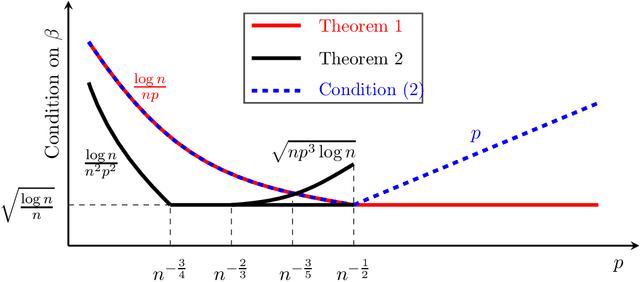
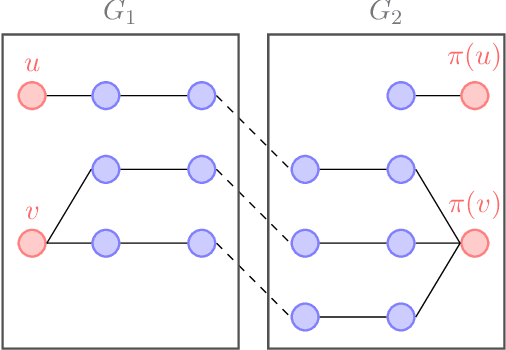
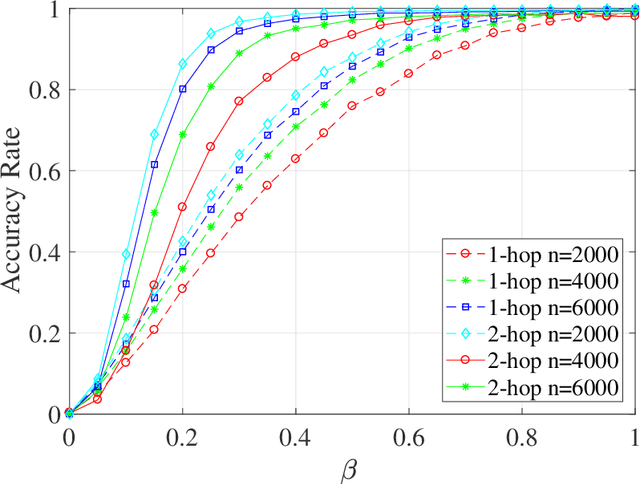
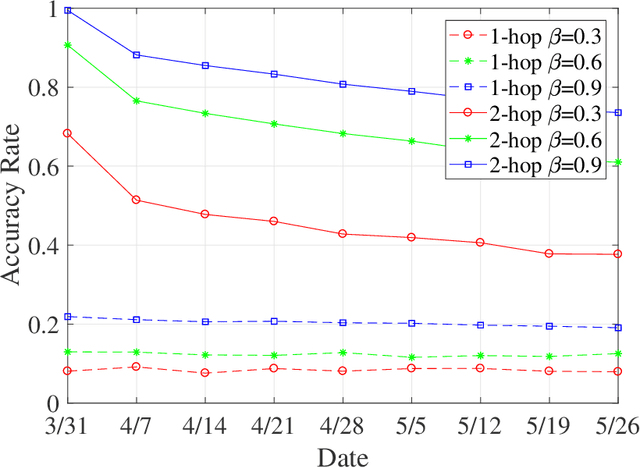
The graph matching problem aims to find the latent vertex correspondence between two edge-correlated graphs and has many practical applications. In this work, we study a version of the seeded graph matching problem, which assumes that a set of seeds, i.e., pre-mapped vertex-pairs, is given in advance. Specifically, consider two correlated graphs whose edges are sampled independently with probability $s$ from a parent \ER graph $\mathcal{G}(n,p)$. Furthermore, a mapping between the vertices of the two graphs is provided as seeds, of which an unknown $\beta$ fraction is correct. This problem was first studied in \cite{lubars2018correcting} where an algorithm is proposed and shown to perfectly recover the correct vertex mapping with high probability if $\beta\geq\max\left\{\frac{8}{3}p,\frac{16\log{n}}{nps^2}\right\}$. We improve their condition to $\beta\geq\max\left\{30\sqrt{\frac{\log n}{n(1-p)^2s^2}},\frac{45\log{n}}{np(1-p)^2s^2}\right)$. However, when $p=O\left( \sqrt{{\log n}/{ns^2}}\right)$, our improved condition still requires that $\beta$ must increase inversely proportional to $np$. In order to improve the matching performance for sparse graphs, we propose a new algorithm that uses "witnesses" in the 2-hop neighborhood, instead of only 1-hop neighborhood as in \cite{lubars2018correcting}. We show that when $np^2\leq\frac{1}{135\log n}$, our new algorithm can achieve perfect recovery with high probability if $\beta\geq\max\left\{900\sqrt{\frac{np^3(1-s)\log n}{s}},600\sqrt{\frac{\log n}{ns^4}}, \frac{1200\log n}{n^2p^2s^4}\right\}$ and $nps^2\geq 128\log n$. Numerical experiments on both synthetic and real graphs corroborate our theoretical findings and show that our 2-hop algorithm significantly outperforms the 1-hop algorithm when the graphs are relatively sparse.