 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatiotemporal Sycophancy: Negation-Based Gaslighting in Video Large Language Models
Apr 20, 2026Video Large Language Models (Vid-LLMs) have demonstrated remarkable performance in video understanding tasks, yet their robustness under conversational interaction remains largely underexplored. In this paper, we identify spatiotemporal sycophancy, a failure mode in which Vid-LLMs retract initially correct, visually grounded judgments and conform to misleading user feedback under negation-based gaslighting. Rather than merely changing their answers, the models often fabricate unsupported temporal or spatial explanations to justify incorrect revisions. To systematically investigate this phenomenon, we propose a negation-based gaslighting evaluation framework and introduce GasVideo-1000, a curated benchmark designed to probe spatiotemporal sycophancy with clear visual grounding and temporal reasoning requirements. We evaluate a broad range of state-of-the-art open-source and proprietary Vid-LLMs across diverse video understanding tasks. Extensive experiments reveal that vulnerability to negation-based gaslighting is pervasive and severe, even among models with strong baseline performance. While prompt-level grounding constraints can partially mitigate this behavior, they do not reliably prevent hallucinated justifications or belief reversal. Our results indicate that current Vid-LLMs lack robust mechanisms for maintaining grounded spatiotemporal beliefs under adversarial conversational feedback.
Predicting Future Utility: Global Combinatorial Optimization for Task-Agnostic KV Cache Eviction
Feb 09, 2026Given the quadratic complexity of attention, KV cache eviction is vital to accelerate model inference. Current KV cache eviction methods typically rely on instantaneous heuristic metrics, implicitly assuming that score magnitudes are consistent proxies for importance across all heads. However, this overlooks the heterogeneity in predictive fidelity across attention heads. While certain heads prioritize the instantaneous contribution of tokens, others are dedicated to capturing long-horizon utility. In this paper, we propose that optimal budget allocation should be governed by the marginal utility in preserving long-term semantic information. Based on this insight, we propose LU-KV, a novel framework that optimizes head-level budget allocation through a convex-hull relaxation and a marginal-utility-based greedy solver to achieve near-optimal precision. Furthermore, we implement a data-driven offline profiling protocol to facilitate the practical deployment of LU-KV. Extensive evaluations on LongBench and RULER benchmarks demonstrate that LU-KV achieves an 80% reduction in KV cache size with minimal performance degradation, while simultaneously reducing inference latency and GPU memory footprint.
Dual-LoRA and Quality-Enhanced Pseudo Replay for Multimodal Continual Food Learning
Nov 17, 2025Food analysis has become increasingly critical for health-related tasks such as personalized nutrition and chronic disease prevention. However, existing large multimodal models (LMMs) in food analysis suffer from catastrophic forgetting when learning new tasks, requiring costly retraining from scratch. To address this, we propose a novel continual learning framework for multimodal food learning, integrating a Dual-LoRA architecture with Quality-Enhanced Pseudo Replay. We introduce two complementary low-rank adapters for each task: a specialized LoRA that learns task-specific knowledge with orthogonal constraints to previous tasks' subspaces, and a cooperative LoRA that consolidates shared knowledge across tasks via pseudo replay. To improve the reliability of replay data, our Quality-Enhanced Pseudo Replay strategy leverages self-consistency and semantic similarity to reduce hallucinations in generated samples. Experiments on the comprehensive Uni-Food dataset show superior performance in mitigating forgetting, representing the first effective continual learning approach for complex food tasks.
TaoSR-AGRL: Adaptive Guided Reinforcement Learning Framework for E-commerce Search Relevance
Oct 09, 2025Query-product relevance prediction is fundamental to e-commerce search and has become even more critical in the era of AI-powered shopping, where semantic understanding and complex reasoning directly shape the user experience and business conversion. Large Language Models (LLMs) enable generative, reasoning-based approaches, typically aligned via supervised fine-tuning (SFT) or preference optimization methods like Direct Preference Optimization (DPO). However, the increasing complexity of business rules and user queries exposes the inability of existing methods to endow models with robust reasoning capacity for long-tail and challenging cases. Efforts to address this via reinforcement learning strategies like Group Relative Policy Optimization (GRPO) often suffer from sparse terminal rewards, offering insufficient guidance for multi-step reasoning and slowing convergence. To address these challenges, we propose TaoSR-AGRL, an Adaptive Guided Reinforcement Learning framework for LLM-based relevance prediction in Taobao Search Relevance. TaoSR-AGRL introduces two key innovations: (1) Rule-aware Reward Shaping, which decomposes the final relevance judgment into dense, structured rewards aligned with domain-specific relevance criteria; and (2) Adaptive Guided Replay, which identifies low-accuracy rollouts during training and injects targeted ground-truth guidance to steer the policy away from stagnant, rule-violating reasoning patterns toward compliant trajectories. TaoSR-AGRL was evaluated on large-scale real-world datasets and through online side-by-side human evaluations on Taobao Search. It consistently outperforms DPO and standard GRPO baselines in offline experiments, improving relevance accuracy, rule adherence, and training stability. The model trained with TaoSR-AGRL has been successfully deployed in the main search scenario on Taobao, serving hundreds of millions of users.
TaoSR-SHE: Stepwise Hybrid Examination Reinforcement Learning Framework for E-commerce Search Relevance
Oct 09, 2025Query-product relevance analysis is a foundational technology in e-commerce search engines and has become increasingly important in AI-driven e-commerce. The recent emergence of large language models (LLMs), particularly their chain-of-thought (CoT) reasoning capabilities, offers promising opportunities for developing relevance systems that are both more interpretable and more robust. However, existing training paradigms have notable limitations: SFT and DPO suffer from poor generalization on long-tail queries and from a lack of fine-grained, stepwise supervision to enforce rule-aligned reasoning. In contrast, reinforcement learning with verification rewards (RLVR) suffers from sparse feedback, which provides insufficient signal to correct erroneous intermediate steps, thereby undermining logical consistency and limiting performance in complex inference scenarios. To address these challenges, we introduce the Stepwise Hybrid Examination Reinforcement Learning framework for Taobao Search Relevance (TaoSR-SHE). At its core is Stepwise Reward Policy Optimization (SRPO), a reinforcement learning algorithm that leverages step-level rewards generated by a hybrid of a high-quality generative stepwise reward model and a human-annotated offline verifier, prioritizing learning from critical correct and incorrect reasoning steps. TaoSR-SHE further incorporates two key techniques: diversified data filtering to encourage exploration across varied reasoning paths and mitigate policy entropy collapse, and multi-stage curriculum learning to foster progressive capability growth. Extensive experiments on real-world search benchmarks show that TaoSR-SHE improves both reasoning quality and relevance-prediction accuracy in large-scale e-commerce settings, outperforming SFT, DPO, GRPO, and other baselines, while also enhancing interpretability and robustness.
TaoSR1: The Thinking Model for E-commerce Relevance Search
Aug 17, 2025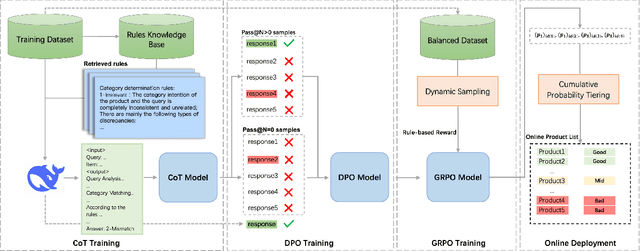
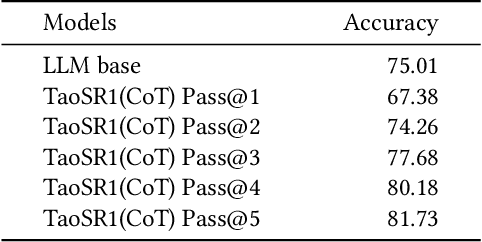
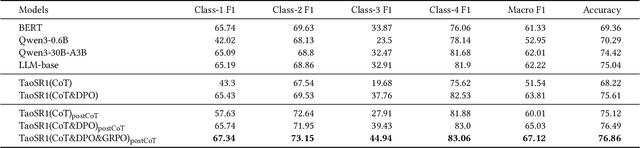
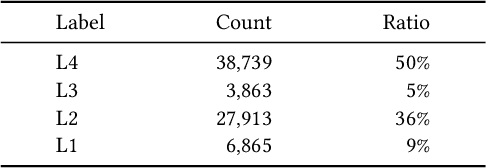
Query-product relevance prediction is a core task in e-commerce search. BERT-based models excel at semantic matching but lack complex reasoning capabilities. While Large Language Models (LLMs) are explored, most still use discriminative fine-tuning or distill to smaller models for deployment. We propose a framework to directly deploy LLMs for this task, addressing key challenges: Chain-of-Thought (CoT) error accumulation, discriminative hallucination, and deployment feasibility. Our framework, TaoSR1, involves three stages: (1) Supervised Fine-Tuning (SFT) with CoT to instill reasoning; (2) Offline sampling with a pass@N strategy and Direct Preference Optimization (DPO) to improve generation quality; and (3) Difficulty-based dynamic sampling with Group Relative Policy Optimization (GRPO) to mitigate discriminative hallucination. Additionally, post-CoT processing and a cumulative probability-based partitioning method enable efficient online deployment. TaoSR1 significantly outperforms baselines on offline datasets and achieves substantial gains in online side-by-side human evaluations, introducing a novel paradigm for applying CoT reasoning to relevance classification.
Don't Deceive Me: Mitigating Gaslighting through Attention Reallocation in LMMs
Apr 13, 2025



Large Multimodal Models (LMMs) have demonstrated remarkable capabilities across a wide range of tasks. However, their vulnerability to user gaslighting-the deliberate use of misleading or contradictory inputs-raises critical concerns about their reliability in real-world applications. In this paper, we address the novel and challenging issue of mitigating the negative impact of negation-based gaslighting on LMMs, where deceptive user statements lead to significant drops in model accuracy. Specifically, we introduce GasEraser, a training-free approach that reallocates attention weights from misleading textual tokens to semantically salient visual regions. By suppressing the influence of "attention sink" tokens and enhancing focus on visually grounded cues, GasEraser significantly improves LMM robustness without requiring retraining or additional supervision. Extensive experimental results demonstrate that GasEraser is effective across several leading open-source LMMs on the GaslightingBench. Notably, for LLaVA-v1.5-7B, GasEraser reduces the misguidance rate by 48.2%, demonstrating its potential for more trustworthy LMMs.
Visual Cue Enhancement and Dual Low-Rank Adaptation for Efficient Visual Instruction Fine-Tuning
Nov 19, 2024Fine-tuning multimodal large language models (MLLMs) presents significant challenges, including a reliance on high-level visual features that limits fine-grained detail comprehension, and data conflicts that arise from task complexity. To address these issues, we propose an efficient fine-tuning framework with two novel approaches: Vision Cue Enhancement (VCE) and Dual Low-Rank Adaptation (Dual-LoRA). VCE enhances the vision projector by integrating multi-level visual cues, improving the model's ability to capture fine-grained visual features. Dual-LoRA introduces a dual low-rank structure for instruction tuning, decoupling learning into skill and task spaces to enable precise control and efficient adaptation across diverse tasks. Our method simplifies implementation, enhances visual comprehension, and improves adaptability. Experiments on both downstream tasks and general benchmarks demonstrate the effectiveness of our proposed approach.
Domain Expansion and Boundary Growth for Open-Set Single-Source Domain Generalization
Nov 05, 2024



Open-set single-source domain generalization aims to use a single-source domain to learn a robust model that can be generalized to unknown target domains with both domain shifts and label shifts. The scarcity of the source domain and the unknown data distribution of the target domain pose a great challenge for domain-invariant feature learning and unknown class recognition. In this paper, we propose a novel learning approach based on domain expansion and boundary growth to expand the scarce source samples and enlarge the boundaries across the known classes that indirectly broaden the boundary between the known and unknown classes. Specifically, we achieve domain expansion by employing both background suppression and style augmentation on the source data to synthesize new samples. Then we force the model to distill consistent knowledge from the synthesized samples so that the model can learn domain-invariant information. Furthermore, we realize boundary growth across classes by using edge maps as an additional modality of samples when training multi-binary classifiers. In this way, it enlarges the boundary between the inliers and outliers, and consequently improves the unknown class recognition during open-set generalization. Extensive experiments show that our approach can achieve significant improvements and reach state-of-the-art performance on several cross-domain image classification datasets.
RoDE: Linear Rectified Mixture of Diverse Experts for Food Large Multi-Modal Models
Jul 17, 2024



Large Multi-modal Models (LMMs) have significantly advanced a variety of vision-language tasks. The scalability and availability of high-quality training data play a pivotal role in the success of LMMs. In the realm of food, while comprehensive food datasets such as Recipe1M offer an abundance of ingredient and recipe information, they often fall short of providing ample data for nutritional analysis. The Recipe1M+ dataset, despite offering a subset for nutritional evaluation, is limited in the scale and accuracy of nutrition information. To bridge this gap, we introduce Uni-Food, a unified food dataset that comprises over 100,000 images with various food labels, including categories, ingredients, recipes, and ingredient-level nutritional information. Uni-Food is designed to provide a more holistic approach to food data analysis, thereby enhancing the performance and capabilities of LMMs in this domain. To mitigate the conflicts arising from multi-task supervision during fine-tuning of LMMs, we introduce a novel Linear Rectification Mixture of Diverse Experts (RoDE) approach. RoDE utilizes a diverse array of experts to address tasks of varying complexity, thereby facilitating the coordination of trainable parameters, i.e., it allocates more parameters for more complex tasks and, conversely, fewer parameters for simpler tasks. RoDE implements linear rectification union to refine the router's functionality, thereby enhancing the efficiency of sparse task allocation. These design choices endow RoDE with features that ensure GPU memory efficiency and ease of optimization. Our experimental results validate the effectiveness of our proposed approach in addressing the inherent challenges of food-related multitasking.