 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFarmMind: Reasoning-Query-Driven Dynamic Segmentation for Farmland Remote Sensing Images
Jan 30, 2026Existing methods for farmland remote sensing image (FRSI) segmentation generally follow a static segmentation paradigm, where analysis relies solely on the limited information contained within a single input patch. Consequently, their reasoning capability is limited when dealing with complex scenes characterized by ambiguity and visual uncertainty. In contrast, human experts, when interpreting remote sensing images in such ambiguous cases, tend to actively query auxiliary images (such as higher-resolution, larger-scale, or temporally adjacent data) to conduct cross-verification and achieve more comprehensive reasoning. Inspired by this, we propose a reasoning-query-driven dynamic segmentation framework for FRSIs, named FarmMind. This framework breaks through the limitations of the static segmentation paradigm by introducing a reasoning-query mechanism, which dynamically and on-demand queries external auxiliary images to compensate for the insufficient information in a single input image. Unlike direct queries, this mechanism simulates the thinking process of human experts when faced with segmentation ambiguity: it first analyzes the root causes of segmentation ambiguities through reasoning, and then determines what type of auxiliary image needs to be queried based on this analysis. Extensive experiments demonstrate that FarmMind achieves superior segmentation performance and stronger generalization ability compared with existing methods. The source code and dataset used in this work are publicly available at: https://github.com/WithoutOcean/FarmMind.
LocationAgent: A Hierarchical Agent for Image Geolocation via Decoupling Strategy and Evidence from Parametric Knowledge
Jan 27, 2026Image geolocation aims to infer capture locations based on visual content. Fundamentally, this constitutes a reasoning process composed of \textit{hypothesis-verification cycles}, requiring models to possess both geospatial reasoning capabilities and the ability to verify evidence against geographic facts. Existing methods typically internalize location knowledge and reasoning patterns into static memory via supervised training or trajectory-based reinforcement fine-tuning. Consequently, these methods are prone to factual hallucinations and generalization bottlenecks in open-world settings or scenarios requiring dynamic knowledge. To address these challenges, we propose a Hierarchical Localization Agent, called LocationAgent. Our core philosophy is to retain hierarchical reasoning logic within the model while offloading the verification of geographic evidence to external tools. To implement hierarchical reasoning, we design the RER architecture (Reasoner-Executor-Recorder), which employs role separation and context compression to prevent the drifting problem in multi-step reasoning. For evidence verification, we construct a suite of clue exploration tools that provide diverse evidence to support location reasoning. Furthermore, to address data leakage and the scarcity of Chinese data in existing datasets, we introduce CCL-Bench (China City Location Bench), an image geolocation benchmark encompassing various scene granularities and difficulty levels. Extensive experiments demonstrate that LocationAgent significantly outperforms existing methods by at least 30\% in zero-shot settings.
Towards Accurate UAV Image Perception: Guiding Vision-Language Models with Stronger Task Prompts
Dec 08, 2025



Existing image perception methods based on VLMs generally follow a paradigm wherein models extract and analyze image content based on user-provided textual task prompts. However, such methods face limitations when applied to UAV imagery, which presents challenges like target confusion, scale variations, and complex backgrounds. These challenges arise because VLMs' understanding of image content depends on the semantic alignment between visual and textual tokens. When the task prompt is simplistic and the image content is complex, achieving effective alignment becomes difficult, limiting the model's ability to focus on task-relevant information. To address this issue, we introduce AerialVP, the first agent framework for task prompt enhancement in UAV image perception. AerialVP proactively extracts multi-dimensional auxiliary information from UAV images to enhance task prompts, overcoming the limitations of traditional VLM-based approaches. Specifically, the enhancement process includes three stages: (1) analyzing the task prompt to identify the task type and enhancement needs, (2) selecting appropriate tools from the tool repository, and (3) generating enhanced task prompts based on the analysis and selected tools. To evaluate AerialVP, we introduce AerialSense, a comprehensive benchmark for UAV image perception that includes Aerial Visual Reasoning, Aerial Visual Question Answering, and Aerial Visual Grounding tasks. AerialSense provides a standardized basis for evaluating model generalization and performance across diverse resolutions, lighting conditions, and both urban and natural scenes. Experimental results demonstrate that AerialVP significantly enhances task prompt guidance, leading to stable and substantial performance improvements in both open-source and proprietary VLMs. Our work will be available at https://github.com/lostwolves/AerialVP.
Learning on the Job: An Experience-Driven Self-Evolving Agent for Long-Horizon Tasks
Oct 09, 2025Large Language Models have demonstrated remarkable capabilities across diverse domains, yet significant challenges persist when deploying them as AI agents for real-world long-horizon tasks. Existing LLM agents suffer from a critical limitation: they are test-time static and cannot learn from experience, lacking the ability to accumulate knowledge and continuously improve on the job. To address this challenge, we propose MUSE, a novel agent framework that introduces an experience-driven, self-evolving system centered around a hierarchical Memory Module. MUSE organizes diverse levels of experience and leverages them to plan and execute long-horizon tasks across multiple applications. After each sub-task execution, the agent autonomously reflects on its trajectory, converting the raw trajectory into structured experience and integrating it back into the Memory Module. This mechanism enables the agent to evolve beyond its static pretrained parameters, fostering continuous learning and self-evolution. We evaluate MUSE on the long-horizon productivity benchmark TAC. It achieves new SOTA performance by a significant margin using only a lightweight Gemini-2.5 Flash model. Sufficient Experiments demonstrate that as the agent autonomously accumulates experience, it exhibits increasingly superior task completion capabilities, as well as robust continuous learning and self-evolution capabilities. Moreover, the accumulated experience from MUSE exhibits strong generalization properties, enabling zero-shot improvement on new tasks. MUSE establishes a new paradigm for AI agents capable of real-world productivity task automation.
Select to Know: An Internal-External Knowledge Self-Selection Framework for Domain-Specific Question Answering
Aug 21, 2025



Large Language Models (LLMs) perform well in general QA but often struggle in domain-specific scenarios. Retrieval-Augmented Generation (RAG) introduces external knowledge but suffers from hallucinations and latency due to noisy retrievals. Continued pretraining internalizes domain knowledge but is costly and lacks cross-domain flexibility. We attribute this challenge to the long-tail distribution of domain knowledge, which leaves partial yet useful internal knowledge underutilized. We further argue that knowledge acquisition should be progressive, mirroring human learning: first understanding concepts, then applying them to complex reasoning. To address this, we propose Selct2Know (S2K), a cost-effective framework that internalizes domain knowledge through an internal-external knowledge self-selection strategy and selective supervised fine-tuning. We also introduce a structured reasoning data generation pipeline and integrate GRPO to enhance reasoning ability. Experiments on medical, legal, and financial QA benchmarks show that S2K consistently outperforms existing methods and matches domain-pretrained LLMs with significantly lower cost.
Remote Sensing Image Intelligent Interpretation with the Language-Centered Perspective: Principles, Methods and Challenges
Aug 09, 2025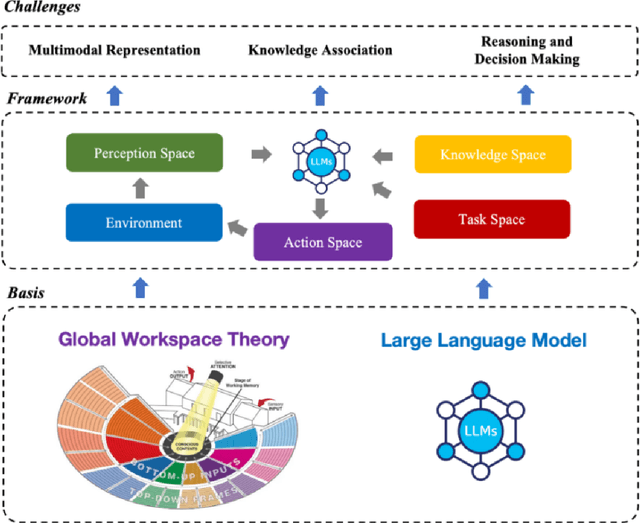
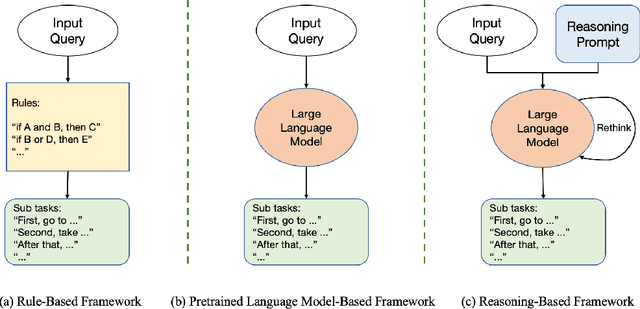
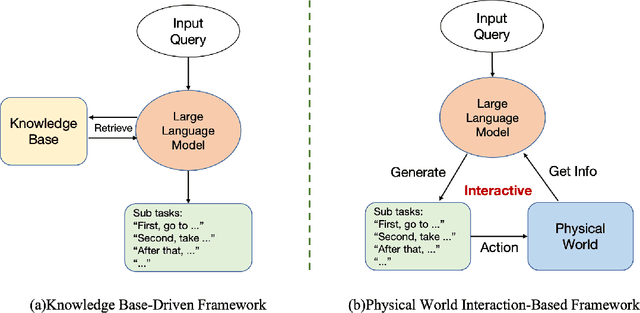
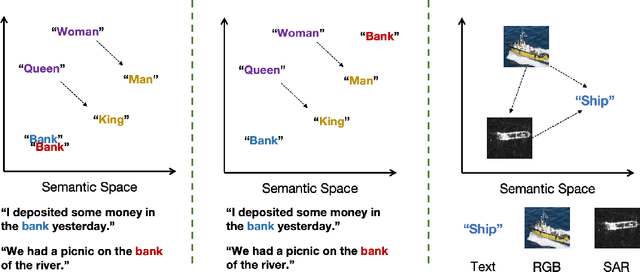
The mainstream paradigm of remote sensing image interpretation has long been dominated by vision-centered models, which rely on visual features for semantic understanding. However, these models face inherent limitations in handling multi-modal reasoning, semantic abstraction, and interactive decision-making. While recent advances have introduced Large Language Models (LLMs) into remote sensing workflows, existing studies primarily focus on downstream applications, lacking a unified theoretical framework that explains the cognitive role of language. This review advocates a paradigm shift from vision-centered to language-centered remote sensing interpretation. Drawing inspiration from the Global Workspace Theory (GWT) of human cognition, We propose a language-centered framework for remote sensing interpretation that treats LLMs as the cognitive central hub integrating perceptual, task, knowledge and action spaces to enable unified understanding, reasoning, and decision-making. We first explore the potential of LLMs as the central cognitive component in remote sensing interpretation, and then summarize core technical challenges, including unified multimodal representation, knowledge association, and reasoning and decision-making. Furthermore, we construct a global workspace-driven interpretation mechanism and review how language-centered solutions address each challenge. Finally, we outline future research directions from four perspectives: adaptive alignment of multimodal data, task understanding under dynamic knowledge constraints, trustworthy reasoning, and autonomous interaction. This work aims to provide a conceptual foundation for the next generation of remote sensing interpretation systems and establish a roadmap toward cognition-driven intelligent geospatial analysis.
A Gift from the Integration of Discriminative and Diffusion-based Generative Learning: Boundary Refinement Remote Sensing Semantic Segmentation
Jul 02, 2025Remote sensing semantic segmentation must address both what the ground objects are within an image and where they are located. Consequently, segmentation models must ensure not only the semantic correctness of large-scale patches (low-frequency information) but also the precise localization of boundaries between patches (high-frequency information). However, most existing approaches rely heavily on discriminative learning, which excels at capturing low-frequency features, while overlooking its inherent limitations in learning high-frequency features for semantic segmentation. Recent studies have revealed that diffusion generative models excel at generating high-frequency details. Our theoretical analysis confirms that the diffusion denoising process significantly enhances the model's ability to learn high-frequency features; however, we also observe that these models exhibit insufficient semantic inference for low-frequency features when guided solely by the original image. Therefore, we integrate the strengths of both discriminative and generative learning, proposing the Integration of Discriminative and diffusion-based Generative learning for Boundary Refinement (IDGBR) framework. The framework first generates a coarse segmentation map using a discriminative backbone model. This map and the original image are fed into a conditioning guidance network to jointly learn a guidance representation subsequently leveraged by an iterative denoising diffusion process refining the coarse segmentation. Extensive experiments across five remote sensing semantic segmentation datasets (binary and multi-class segmentation) confirm our framework's capability of consistent boundary refinement for coarse results from diverse discriminative architectures. The source code will be available at https://github.com/KeyanHu-git/IDGBR.
SFNet: Fusion of Spatial and Frequency-Domain Features for Remote Sensing Image Forgery Detection
Jun 25, 2025



The rapid advancement of generative artificial intelligence is producing fake remote sensing imagery (RSI) that is increasingly difficult to detect, potentially leading to erroneous intelligence, fake news, and even conspiracy theories. Existing forgery detection methods typically rely on single visual features to capture predefined artifacts, such as spatial-domain cues to detect forged objects like roads or buildings in RSI, or frequency-domain features to identify artifacts from up-sampling operations in adversarial generative networks (GANs). However, the nature of artifacts can significantly differ depending on geographic terrain, land cover types, or specific features within the RSI. Moreover, these complex artifacts evolve as generative models become more sophisticated. In short, over-reliance on a single visual cue makes existing forgery detectors struggle to generalize across diverse remote sensing data. This paper proposed a novel forgery detection framework called SFNet, designed to identify fake images in diverse remote sensing data by leveraging spatial and frequency domain features. Specifically, to obtain rich and comprehensive visual information, SFNet employs two independent feature extractors to capture spatial and frequency domain features from input RSIs. To fully utilize the complementary domain features, the domain feature mapping module and the hybrid domain feature refinement module(CBAM attention) of SFNet are designed to successively align and fuse the multi-domain features while suppressing redundant information. Experiments on three datasets show that SFNet achieves an accuracy improvement of 4%-15.18% over the state-of-the-art RS forgery detection methods and exhibits robust generalization capabilities. The code is available at https://github.com/GeoX-Lab/RSTI/tree/main/SFNet.
BEDI: A Comprehensive Benchmark for Evaluating Embodied Agents on UAVs
May 23, 2025With the rapid advancement of low-altitude remote sensing and Vision-Language Models (VLMs), Embodied Agents based on Unmanned Aerial Vehicles (UAVs) have shown significant potential in autonomous tasks. However, current evaluation methods for UAV-Embodied Agents (UAV-EAs) remain constrained by the lack of standardized benchmarks, diverse testing scenarios and open system interfaces. To address these challenges, we propose BEDI (Benchmark for Embodied Drone Intelligence), a systematic and standardized benchmark designed for evaluating UAV-EAs. Specifically, we introduce a novel Dynamic Chain-of-Embodied-Task paradigm based on the perception-decision-action loop, which decomposes complex UAV tasks into standardized, measurable subtasks. Building on this paradigm, we design a unified evaluation framework encompassing five core sub-skills: semantic perception, spatial perception, motion control, tool utilization, and task planning. Furthermore, we construct a hybrid testing platform that integrates static real-world environments with dynamic virtual scenarios, enabling comprehensive performance assessment of UAV-EAs across varied contexts. The platform also offers open and standardized interfaces, allowing researchers to customize tasks and extend scenarios, thereby enhancing flexibility and scalability in the evaluation process. Finally, through empirical evaluations of several state-of-the-art (SOTA) VLMs, we reveal their limitations in embodied UAV tasks, underscoring the critical role of the BEDI benchmark in advancing embodied intelligence research and model optimization. By filling the gap in systematic and standardized evaluation within this field, BEDI facilitates objective model comparison and lays a robust foundation for future development in this field. Our benchmark will be released at https://github.com/lostwolves/BEDI .
Causal invariant geographic network representations with feature and structural distribution shifts
Mar 25, 2025The existing methods learn geographic network representations through deep graph neural networks (GNNs) based on the i.i.d. assumption. However, the spatial heterogeneity and temporal dynamics of geographic data make the out-of-distribution (OOD) generalisation problem particularly salient. The latter are particularly sensitive to distribution shifts (feature and structural shifts) between testing and training data and are the main causes of the OOD generalisation problem. Spurious correlations are present between invariant and background representations due to selection biases and environmental effects, resulting in the model extremes being more likely to learn background representations. The existing approaches focus on background representation changes that are determined by shifts in the feature distributions of nodes in the training and test data while ignoring changes in the proportional distributions of heterogeneous and homogeneous neighbour nodes, which we refer to as structural distribution shifts. We propose a feature-structure mixed invariant representation learning (FSM-IRL) model that accounts for both feature distribution shifts and structural distribution shifts. To address structural distribution shifts, we introduce a sampling method based on causal attention, encouraging the model to identify nodes possessing strong causal relationships with labels or nodes that are more similar to the target node. Inspired by the Hilbert-Schmidt independence criterion, we implement a reweighting strategy to maximise the orthogonality of the node representations, thereby mitigating the spurious correlations among the node representations and suppressing the learning of background representations. Our experiments demonstrate that FSM-IRL exhibits strong learning capabilities on both geographic and social network datasets in OOD scenarios.
* 15 pages, 3 figures, 8 tables