 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFunCineForge: A Unified Dataset Toolkit and Model for Zero-Shot Movie Dubbing in Diverse Cinematic Scenes
Jan 21, 2026Movie dubbing is the task of synthesizing speech from scripts conditioned on video scenes, requiring accurate lip sync, faithful timbre transfer, and proper modeling of character identity and emotion. However, existing methods face two major limitations: (1) high-quality multimodal dubbing datasets are limited in scale, suffer from high word error rates, contain sparse annotations, rely on costly manual labeling, and are restricted to monologue scenes, all of which hinder effective model training; (2) existing dubbing models rely solely on the lip region to learn audio-visual alignment, which limits their applicability to complex live-action cinematic scenes, and exhibit suboptimal performance in lip sync, speech quality, and emotional expressiveness. To address these issues, we propose FunCineForge, which comprises an end-to-end production pipeline for large-scale dubbing datasets and an MLLM-based dubbing model designed for diverse cinematic scenes. Using the pipeline, we construct the first Chinese television dubbing dataset with rich annotations, and demonstrate the high quality of these data. Experiments across monologue, narration, dialogue, and multi-speaker scenes show that our dubbing model consistently outperforms SOTA methods in audio quality, lip sync, timbre transfer, and instruction following. Code and demos are available at https://anonymous.4open.science/w/FunCineForge.
ArchAgent: Scalable Legacy Software Architecture Recovery with LLMs
Jan 19, 2026Recovering accurate architecture from large-scale legacy software is hindered by architectural drift, missing relations, and the limited context of Large Language Models (LLMs). We present ArchAgent, a scalable agent-based framework that combines static analysis, adaptive code segmentation, and LLM-powered synthesis to reconstruct multiview, business-aligned architectures from cross-repository codebases. ArchAgent introduces scalable diagram generation with contextual pruning and integrates cross-repository data to identify business-critical modules. Evaluations of typical large-scale GitHub projects show significant improvements over existing benchmarks. An ablation study confirms that dependency context improves the accuracy of generated architectures of production-level repositories, and a real-world case study demonstrates effective recovery of critical business logics from legacy projects. The dataset is available at https://github.com/panrusheng/arch-eval-benchmark.
IDMap: A Pseudo-Speaker Generator Framework Based on Speaker Identity Index to Vector Mapping
Nov 09, 2025Facilitated by the speech generation framework that disentangles speech into content, speaker, and prosody, voice anonymization is accomplished by substituting the original speaker embedding vector with that of a pseudo-speaker. In this framework, the pseudo-speaker generation forms a fundamental challenge. Current pseudo-speaker generation methods demonstrate limitations in the uniqueness of pseudo-speakers, consequently restricting their effectiveness in voice privacy protection. Besides, existing model-based methods suffer from heavy computation costs. Especially, in the large-scale scenario where a huge number of pseudo-speakers are generated, the limitations of uniqueness and computational inefficiency become more significant. To this end, this paper proposes a framework for pseudo-speaker generation, which establishes a mapping from speaker identity index to speaker vector in the feedforward architecture, termed IDMap. Specifically, the framework is specified into two models: IDMap-MLP and IDMap-Diff. Experiments were conducted on both small- and large-scale evaluation datasets. Small-scale evaluations on the LibriSpeech dataset validated the effectiveness of the proposed IDMap framework in enhancing the uniqueness of pseudo-speakers, thereby improving voice privacy protection, while at a reduced computational cost. Large-scale evaluations on the MLS and Common Voice datasets further justified the superiority of the IDMap framework regarding the stability of the voice privacy protection capability as the number of pseudo-speakers increased. Audio samples and open-source code can be found in https://github.com/VoicePrivacy/IDMap.
The CCF AATC 2025: Speech Restoration Challenge
Sep 16, 2025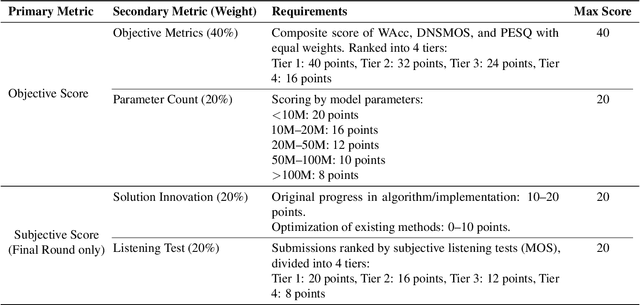
Real-world speech communication is often hampered by a variety of distortions that degrade quality and intelligibility. While many speech enhancement algorithms target specific degradations like noise or reverberation, they often fall short in realistic scenarios where multiple distortions co-exist and interact. To spur research in this area, we introduce the Speech Restoration Challenge as part of the China Computer Federation (CCF) Advanced Audio Technology Competition (AATC) 2025. This challenge focuses on restoring speech signals affected by a composite of three degradation types: (1) complex acoustic degradations including non-stationary noise and reverberation; (2) signal-chain artifacts such as those from MP3 compression; and (3) secondary artifacts introduced by other pre-processing enhancement models. We describe the challenge's background, the design of the task, the comprehensive dataset creation methodology, and the detailed evaluation protocol, which assesses both objective performance and model complexity. Homepage: https://ccf-aatc.org.cn/.
Pinhole Effect on Linkability and Dispersion in Speaker Anonymization
Aug 23, 2025Speaker anonymization aims to conceal speaker-specific attributes in speech signals, making the anonymized speech unlinkable to the original speaker identity. Recent approaches achieve this by disentangling speech into content and speaker components, replacing the latter with pseudo speakers. The anonymized speech can be mapped either to a common pseudo speaker shared across utterances or to distinct pseudo speakers unique to each utterance. This paper investigates the impact of these mapping strategies on three key dimensions: speaker linkability, dispersion in the anonymized speaker space, and de-identification from the original identity. Our findings show that using distinct pseudo speakers increases speaker dispersion and reduces linkability compared to common pseudo-speaker mapping, thereby enhancing privacy preservation. These observations are interpreted through the proposed pinhole effect, a conceptual framework introduced to explain the relationship between mapping strategies and anonymization performance. The hypothesis is validated through empirical evaluation.
Select to Know: An Internal-External Knowledge Self-Selection Framework for Domain-Specific Question Answering
Aug 21, 2025



Large Language Models (LLMs) perform well in general QA but often struggle in domain-specific scenarios. Retrieval-Augmented Generation (RAG) introduces external knowledge but suffers from hallucinations and latency due to noisy retrievals. Continued pretraining internalizes domain knowledge but is costly and lacks cross-domain flexibility. We attribute this challenge to the long-tail distribution of domain knowledge, which leaves partial yet useful internal knowledge underutilized. We further argue that knowledge acquisition should be progressive, mirroring human learning: first understanding concepts, then applying them to complex reasoning. To address this, we propose Selct2Know (S2K), a cost-effective framework that internalizes domain knowledge through an internal-external knowledge self-selection strategy and selective supervised fine-tuning. We also introduce a structured reasoning data generation pipeline and integrate GRPO to enhance reasoning ability. Experiments on medical, legal, and financial QA benchmarks show that S2K consistently outperforms existing methods and matches domain-pretrained LLMs with significantly lower cost.
RISE: Reasoning Enhancement via Iterative Self-Exploration in Multi-hop Question Answering
May 28, 2025Large Language Models (LLMs) excel in many areas but continue to face challenges with complex reasoning tasks, such as Multi-Hop Question Answering (MHQA). MHQA requires integrating evidence from diverse sources while managing intricate logical dependencies, often leads to errors in reasoning. Retrieval-Augmented Generation (RAG), widely employed in MHQA tasks, faces challenges in effectively filtering noisy data and retrieving all necessary evidence, thereby limiting its effectiveness in addressing MHQA challenges. To address these challenges, we propose RISE:Reasoning Enhancement via Iterative Self-Exploration, a novel framework designed to enhance models' reasoning capability through iterative self-exploration. Specifically, RISE involves three key steps in addressing MHQA tasks: question decomposition, retrieve-then-read, and self-critique. By leveraging continuous self-exploration, RISE identifies accurate reasoning paths, iteratively self-improving the model's capability to integrate evidence, maintain logical consistency, and enhance performance in MHQA tasks. Extensive experiments on multiple MHQA benchmarks demonstrate that RISE significantly improves reasoning accuracy and task performance.
UDDETTS: Unifying Discrete and Dimensional Emotions for Controllable Emotional Text-to-Speech
May 15, 2025



Recent neural codec language models have made great progress in the field of text-to-speech (TTS), but controllable emotional TTS still faces many challenges. Traditional methods rely on predefined discrete emotion labels to control emotion categories and intensities, which can't capture the complexity and continuity of human emotional perception and expression. The lack of large-scale emotional speech datasets with balanced emotion distributions and fine-grained emotion annotations often causes overfitting in synthesis models and impedes effective emotion control. To address these issues, we propose UDDETTS, a neural codec language model unifying discrete and dimensional emotions for controllable emotional TTS. This model introduces the interpretable Arousal-Dominance-Valence (ADV) space for dimensional emotion description and supports emotion control driven by either discrete emotion labels or nonlinearly quantified ADV values. Furthermore, a semi-supervised training strategy is designed to comprehensively utilize diverse speech datasets with different types of emotion annotations to train the UDDETTS. Experiments show that UDDETTS achieves linear emotion control along the three dimensions of ADV space, and exhibits superior end-to-end emotional speech synthesis capabilities.
DiffStyleTTS: Diffusion-based Hierarchical Prosody Modeling for Text-to-Speech with Diverse and Controllable Styles
Dec 04, 2024



Human speech exhibits rich and flexible prosodic variations. To address the one-to-many mapping problem from text to prosody in a reasonable and flexible manner, we propose DiffStyleTTS, a multi-speaker acoustic model based on a conditional diffusion module and an improved classifier-free guidance, which hierarchically models speech prosodic features, and controls different prosodic styles to guide prosody prediction. Experiments show that our method outperforms all baselines in naturalness and achieves superior synthesis speed compared to three diffusion-based baselines. Additionally, by adjusting the guiding scale, DiffStyleTTS effectively controls the guidance intensity of the synthetic prosody.
Refining Self-Supervised Learnt Speech Representation using Brain Activations
Jun 12, 2024



It was shown in literature that speech representations extracted by self-supervised pre-trained models exhibit similarities with brain activations of human for speech perception and fine-tuning speech representation models on downstream tasks can further improve the similarity. However, it still remains unclear if this similarity can be used to optimize the pre-trained speech models. In this work, we therefore propose to use the brain activations recorded by fMRI to refine the often-used wav2vec2.0 model by aligning model representations toward human neural responses. Experimental results on SUPERB reveal that this operation is beneficial for several downstream tasks, e.g., speaker verification, automatic speech recognition, intent classification.One can then consider the proposed method as a new alternative to improve self-supervised speech models.