 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePYRA: Parallel Yielding Re-Activation for Training-Inference Efficient Task Adaptation
Mar 14, 2024



Recently, the scale of transformers has grown rapidly, which introduces considerable challenges in terms of training overhead and inference efficiency in the scope of task adaptation. Existing works, namely Parameter-Efficient Fine-Tuning (PEFT) and model compression, have separately investigated the challenges. However, PEFT cannot guarantee the inference efficiency of the original backbone, especially for large-scale models. Model compression requires significant training costs for structure searching and re-training. Consequently, a simple combination of them cannot guarantee accomplishing both training efficiency and inference efficiency with minimal costs. In this paper, we propose a novel Parallel Yielding Re-Activation (PYRA) method for such a challenge of training-inference efficient task adaptation. PYRA first utilizes parallel yielding adaptive weights to comprehensively perceive the data distribution in downstream tasks. A re-activation strategy for token modulation is then applied for tokens to be merged, leading to calibrated token features. Extensive experiments demonstrate that PYRA outperforms all competing methods under both low compression rate and high compression rate, demonstrating its effectiveness and superiority in maintaining both training efficiency and inference efficiency for large-scale foundation models. Our code will be released to the public.
A Bi-Pyramid Multimodal Fusion Method for the Diagnosis of Bipolar Disorders
Jan 15, 2024



Previous research on the diagnosis of Bipolar disorder has mainly focused on resting-state functional magnetic resonance imaging. However, their accuracy can not meet the requirements of clinical diagnosis. Efficient multimodal fusion strategies have great potential for applications in multimodal data and can further improve the performance of medical diagnosis models. In this work, we utilize both sMRI and fMRI data and propose a novel multimodal diagnosis model for bipolar disorder. The proposed Patch Pyramid Feature Extraction Module extracts sMRI features, and the spatio-temporal pyramid structure extracts the fMRI features. Finally, they are fused by a fusion module to output diagnosis results with a classifier. Extensive experiments show that our proposed method outperforms others in balanced accuracy from 0.657 to 0.732 on the OpenfMRI dataset, and achieves the state of the art.
Unsupervised Pre-Training Using Masked Autoencoders for ECG Analysis
Oct 17, 2023



Unsupervised learning methods have become increasingly important in deep learning due to their demonstrated large utilization of datasets and higher accuracy in computer vision and natural language processing tasks. There is a growing trend to extend unsupervised learning methods to other domains, which helps to utilize a large amount of unlabelled data. This paper proposes an unsupervised pre-training technique based on masked autoencoder (MAE) for electrocardiogram (ECG) signals. In addition, we propose a task-specific fine-tuning to form a complete framework for ECG analysis. The framework is high-level, universal, and not individually adapted to specific model architectures or tasks. Experiments are conducted using various model architectures and large-scale datasets, resulting in an accuracy of 94.39% on the MITDB dataset for ECG arrhythmia classification task. The result shows a better performance for the classification of previously unseen data for the proposed approach compared to fully supervised methods.
Multi-Dimension-Embedding-Aware Modality Fusion Transformer for Psychiatric Disorder Clasification
Oct 04, 2023



Deep learning approaches, together with neuroimaging techniques, play an important role in psychiatric disorders classification. Previous studies on psychiatric disorders diagnosis mainly focus on using functional connectivity matrices of resting-state functional magnetic resonance imaging (rs-fMRI) as input, which still needs to fully utilize the rich temporal information of the time series of rs-fMRI data. In this work, we proposed a multi-dimension-embedding-aware modality fusion transformer (MFFormer) for schizophrenia and bipolar disorder classification using rs-fMRI and T1 weighted structural MRI (T1w sMRI). Concretely, to fully utilize the temporal information of rs-fMRI and spatial information of sMRI, we constructed a deep learning architecture that takes as input 2D time series of rs-fMRI and 3D volumes T1w. Furthermore, to promote intra-modality attention and information fusion across different modalities, a fusion transformer module (FTM) is designed through extensive self-attention of hybrid feature maps of multi-modality. In addition, a dimension-up and dimension-down strategy is suggested to properly align feature maps of multi-dimensional from different modalities. Experimental results on our private and public OpenfMRI datasets show that our proposed MFFormer performs better than that using a single modality or multi-modality MRI on schizophrenia and bipolar disorder diagnosis.
Kosmos-2.5: A Multimodal Literate Model
Sep 20, 2023



We present Kosmos-2.5, a multimodal literate model for machine reading of text-intensive images. Pre-trained on large-scale text-intensive images, Kosmos-2.5 excels in two distinct yet cooperative transcription tasks: (1) generating spatially-aware text blocks, where each block of text is assigned its spatial coordinates within the image, and (2) producing structured text output that captures styles and structures into the markdown format. This unified multimodal literate capability is achieved through a shared Transformer architecture, task-specific prompts, and flexible text representations. We evaluate Kosmos-2.5 on end-to-end document-level text recognition and image-to-markdown text generation. Furthermore, the model can be readily adapted for any text-intensive image understanding task with different prompts through supervised fine-tuning, making it a general-purpose tool for real-world applications involving text-rich images. This work also paves the way for the future scaling of multimodal large language models.
Unifying Vision, Text, and Layout for Universal Document Processing
Dec 20, 2022



We propose Universal Document Processing (UDOP), a foundation Document AI model which unifies text, image, and layout modalities together with varied task formats, including document understanding and generation. UDOP leverages the spatial correlation between textual content and document image to model image, text, and layout modalities with one uniform representation. With a novel Vision-Text-Layout Transformer, UDOP unifies pretraining and multi-domain downstream tasks into a prompt-based sequence generation scheme. UDOP is pretrained on both large-scale unlabeled document corpora using innovative self-supervised objectives and diverse labeled data. UDOP also learns to generate document images from text and layout modalities via masked image reconstruction. To the best of our knowledge, this is the first time in the field of document AI that one model simultaneously achieves high-quality neural document editing and content customization. Our method sets the state-of-the-art on 9 Document AI tasks, e.g., document understanding and QA, across diverse data domains like finance reports, academic papers, and websites. UDOP ranks first on the leaderboard of the Document Understanding Benchmark (DUE).
Understanding Long Documents with Different Position-Aware Attentions
Aug 17, 2022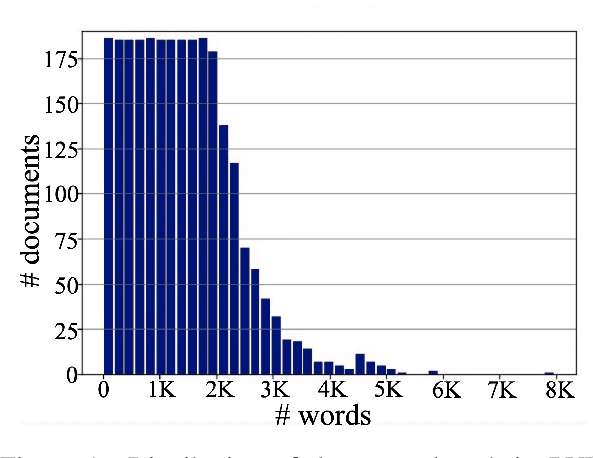
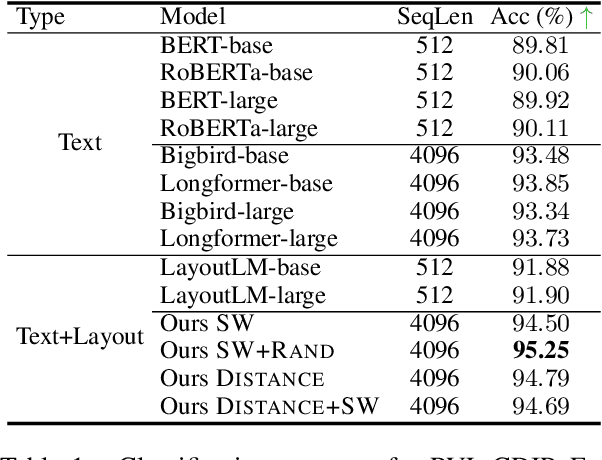
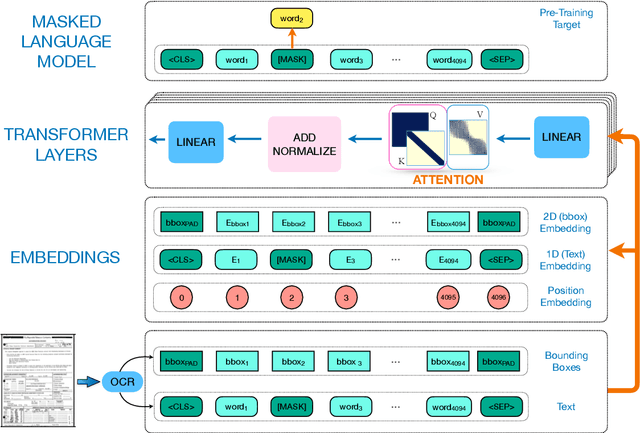
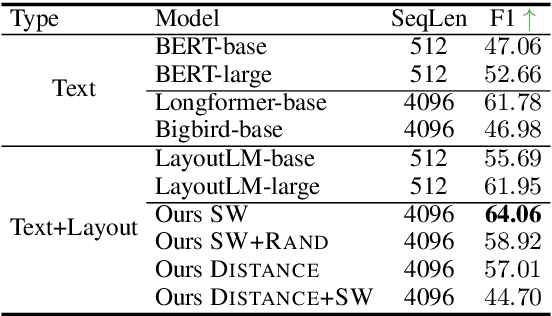
Despite several successes in document understanding, the practical task for long document understanding is largely under-explored due to several challenges in computation and how to efficiently absorb long multimodal input. Most current transformer-based approaches only deal with short documents and employ solely textual information for attention due to its prohibitive computation and memory limit. To address those issues in long document understanding, we explore different approaches in handling 1D and new 2D position-aware attention with essentially shortened context. Experimental results show that our proposed models have advantages for this task based on various evaluation metrics. Furthermore, our model makes changes only to the attention and thus can be easily adapted to any transformer-based architecture.
BoningKnife: Joint Entity Mention Detection and Typing for Nested NER via prior Boundary Knowledge
Jul 20, 2021
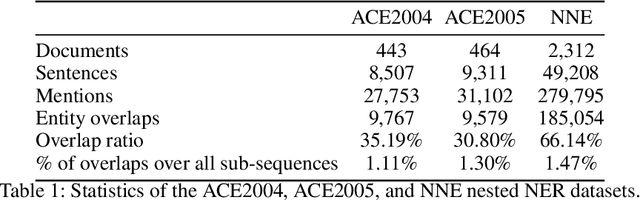
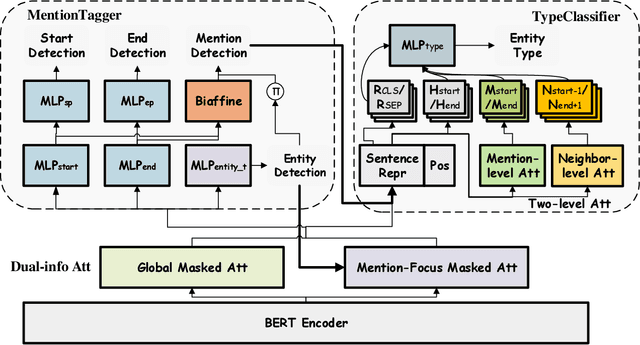
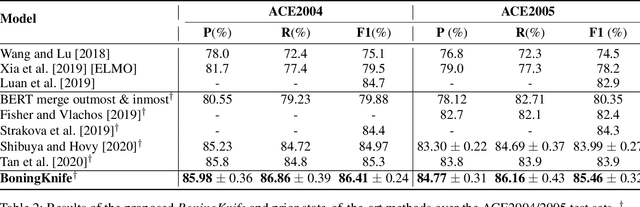
While named entity recognition (NER) is a key task in natural language processing, most approaches only target flat entities, ignoring nested structures which are common in many scenarios. Most existing nested NER methods traverse all sub-sequences which is both expensive and inefficient, and also don't well consider boundary knowledge which is significant for nested entities. In this paper, we propose a joint entity mention detection and typing model via prior boundary knowledge (BoningKnife) to better handle nested NER extraction and recognition tasks. BoningKnife consists of two modules, MentionTagger and TypeClassifier. MentionTagger better leverages boundary knowledge beyond just entity start/end to improve the handling of nesting levels and longer spans, while generating high quality mention candidates. TypeClassifier utilizes a two-level attention mechanism to decouple different nested level representations and better distinguish entity types. We jointly train both modules sharing a common representation and a new dual-info attention layer, which leads to improved representation focus on entity-related information. Experiments over different datasets show that our approach outperforms previous state of the art methods and achieves 86.41, 85.46, and 94.2 F1 scores on ACE2004, ACE2005, and NNE, respectively.
Understanding Chinese Video and Language via Contrastive Multimodal Pre-Training
Apr 19, 2021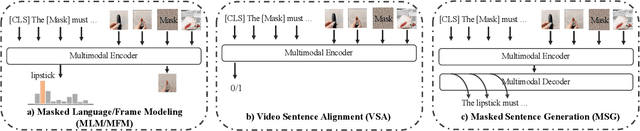
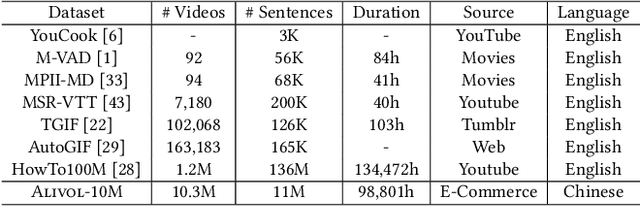

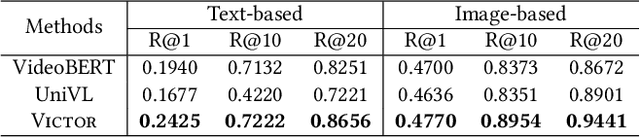
The pre-trained neural models have recently achieved impressive performances in understanding multimodal content. However, it is still very challenging to pre-train neural models for video and language understanding, especially for Chinese video-language data, due to the following reasons. Firstly, existing video-language pre-training algorithms mainly focus on the co-occurrence of words and video frames, but ignore other valuable semantic and structure information of video-language content, e.g., sequential order and spatiotemporal relationships. Secondly, there exist conflicts between video sentence alignment and other proxy tasks. Thirdly, there is a lack of large-scale and high-quality Chinese video-language datasets (e.g., including 10 million unique videos), which are the fundamental success conditions for pre-training techniques. In this work, we propose a novel video-language understanding framework named VICTOR, which stands for VIdeo-language understanding via Contrastive mulTimOdal pRe-training. Besides general proxy tasks such as masked language modeling, VICTOR constructs several novel proxy tasks under the contrastive learning paradigm, making the model be more robust and able to capture more complex multimodal semantic and structural relationships from different perspectives. VICTOR is trained on a large-scale Chinese video-language dataset, including over 10 million complete videos with corresponding high-quality textual descriptions. We apply the pre-trained VICTOR model to a series of downstream applications and demonstrate its superior performances, comparing against the state-of-the-art pre-training methods such as VideoBERT and UniVL. The codes and trained checkpoints will be publicly available to nourish further developments of the research community.
LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding
Apr 18, 2021
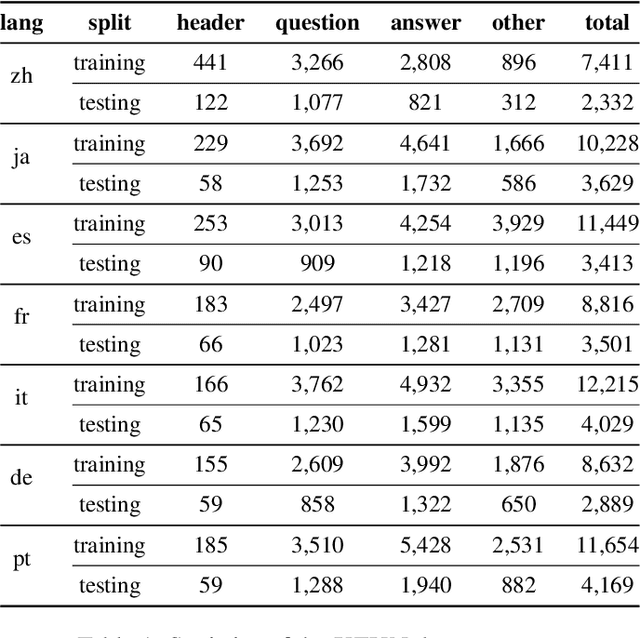
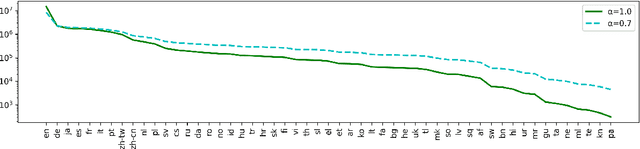
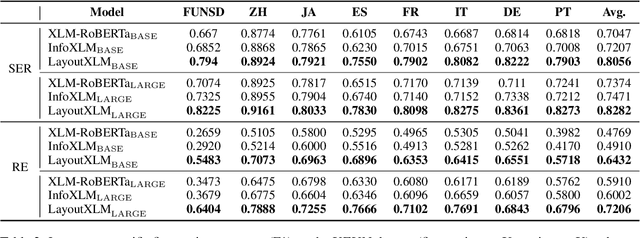
Multimodal pre-training with text, layout, and image has achieved SOTA performance for visually-rich document understanding tasks recently, which demonstrates the great potential for joint learning across different modalities. In this paper, we present LayoutXLM, a multimodal pre-trained model for multilingual document understanding, which aims to bridge the language barriers for visually-rich document understanding. To accurately evaluate LayoutXLM, we also introduce a multilingual form understanding benchmark dataset named XFUN, which includes form understanding samples in 7 languages (Chinese, Japanese, Spanish, French, Italian, German, Portuguese), and key-value pairs are manually labeled for each language. Experiment results show that the LayoutXLM model has significantly outperformed the existing SOTA cross-lingual pre-trained models on the XFUN dataset. The pre-trained LayoutXLM model and the XFUN dataset will be publicly available at https://aka.ms/layoutxlm.