 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Topology-Preserved Distance Transform for Pulmonary Airway Segmentation
Sep 17, 2022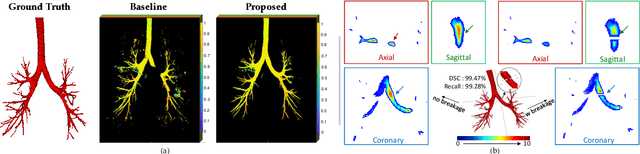
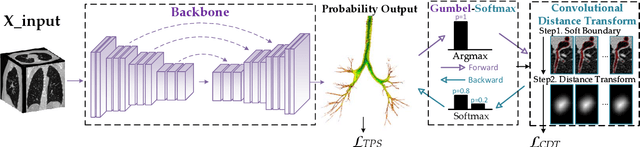
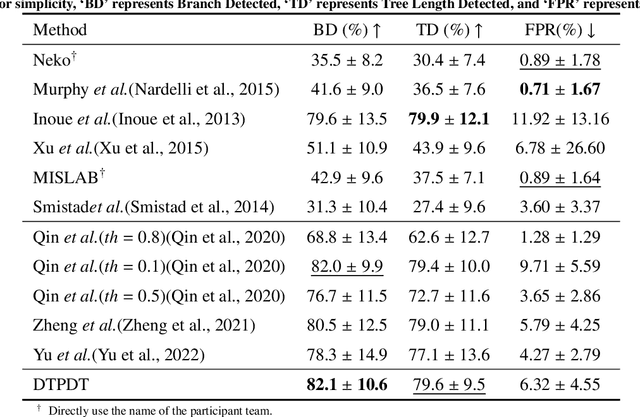
Detailed pulmonary airway segmentation is a clinically important task for endobronchial intervention and treatment of peripheral lung cancer lesions. Convolutional Neural Networks (CNNs) are promising tools for medical image analysis but have been performing poorly for cases when there is a significantly imbalanced feature distribution, which is true for the airway data as the trachea and principal bronchi dominate most of the voxels whereas the lobar bronchi and distal segmental bronchi occupy only a small proportion. In this paper, we propose a Differentiable Topology-Preserved Distance Transform (DTPDT) framework to improve the performance of airway segmentation. A Topology-Preserved Surrogate (TPS) learning strategy is first proposed to equalize the training progress within-class distribution. Furthermore, a Convolutional Distance Transform (CDT) is designed to identify the breakage phenomenon with improved sensitivity, minimizing the variation of the distance map between the prediction and ground-truth. The proposed method is validated with the publicly available reference airway segmentation datasets.
A Compacted Structure for Cross-domain learning on Monocular Depth and Flow Estimation
Aug 25, 2022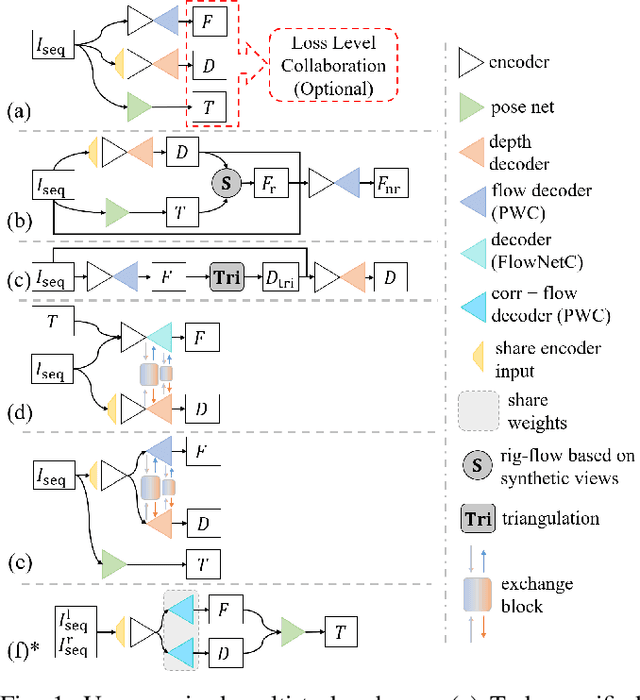
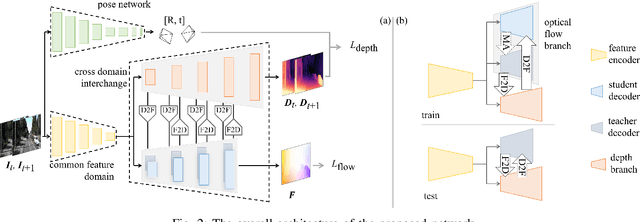
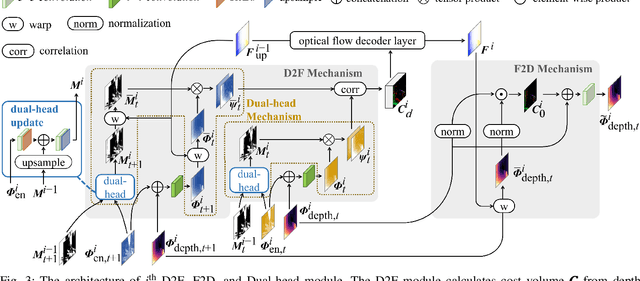
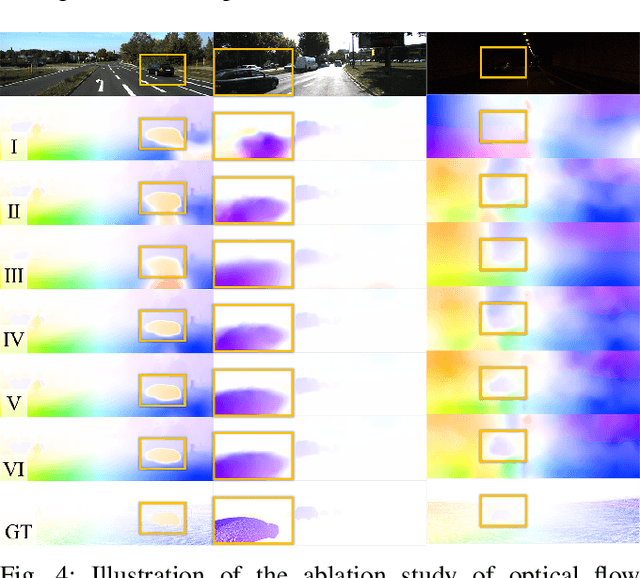
Accurate motion and depth recovery is important for many robot vision tasks including autonomous driving. Most previous studies have achieved cooperative multi-task interaction via either pre-defined loss functions or cross-domain prediction. This paper presents a multi-task scheme that achieves mutual assistance by means of our Flow to Depth (F2D), Depth to Flow (D2F), and Exponential Moving Average (EMA). F2D and D2F mechanisms enable multi-scale information integration between optical flow and depth domain based on differentiable shallow nets. A dual-head mechanism is used to predict optical flow for rigid and non-rigid motion based on a divide-and-conquer manner, which significantly improves the optical flow estimation performance. Furthermore, to make the prediction more robust and stable, EMA is used for our multi-task training. Experimental results on KITTI datasets show that our multi-task scheme outperforms other multi-task schemes and provide marked improvements on the prediction results.
Re-thinking and Re-labeling LIDC-IDRI for Robust Pulmonary Cancer Prediction
Jul 28, 2022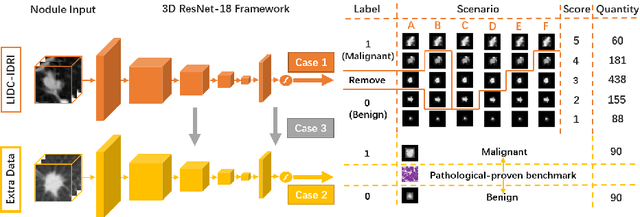
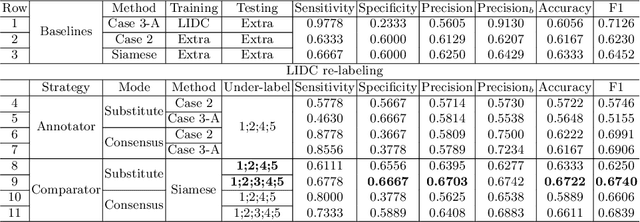
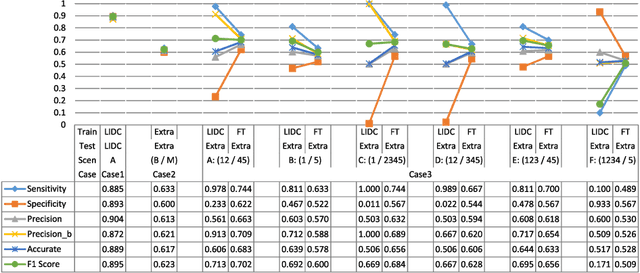
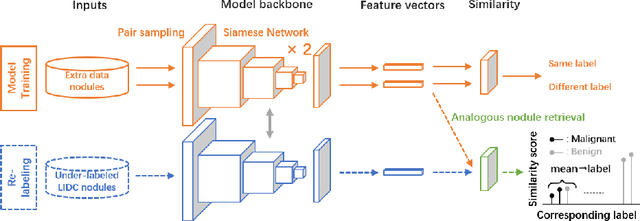
The LIDC-IDRI database is the most popular benchmark for lung cancer prediction. However, with subjective assessment from radiologists, nodules in LIDC may have entirely different malignancy annotations from the pathological ground truth, introducing label assignment errors and subsequent supervision bias during training. The LIDC database thus requires more objective labels for learning-based cancer prediction. Based on an extra small dataset containing 180 nodules diagnosed by pathological examination, we propose to re-label LIDC data to mitigate the effect of original annotation bias verified on this robust benchmark. We demonstrate in this paper that providing new labels by similar nodule retrieval based on metric learning would be an effective re-labeling strategy. Training on these re-labeled LIDC nodules leads to improved model performance, which is enhanced when new labels of uncertain nodules are added. We further infer that re-labeling LIDC is current an expedient way for robust lung cancer prediction while building a large pathological-proven nodule database provides the long-term solution.
Tackling Long-Tailed Category Distribution Under Domain Shifts
Jul 20, 2022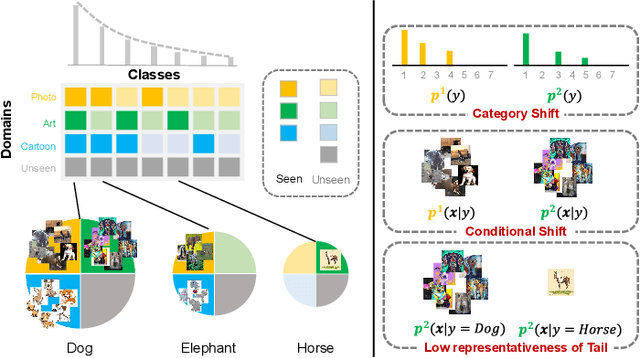
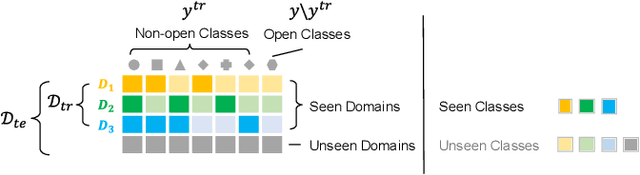
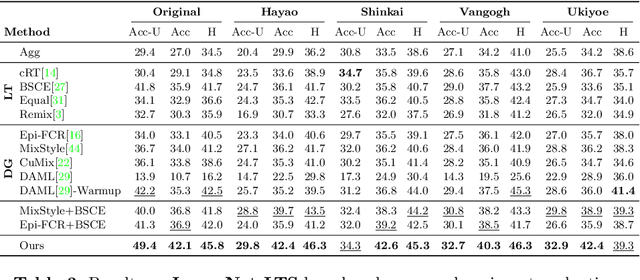
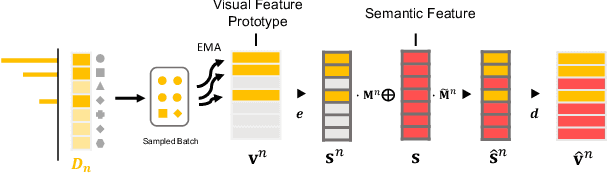
Machine learning models fail to perform well on real-world applications when 1) the category distribution P(Y) of the training dataset suffers from long-tailed distribution and 2) the test data is drawn from different conditional distributions P(X|Y). Existing approaches cannot handle the scenario where both issues exist, which however is common for real-world applications. In this study, we took a step forward and looked into the problem of long-tailed classification under domain shifts. We designed three novel core functional blocks including Distribution Calibrated Classification Loss, Visual-Semantic Mapping and Semantic-Similarity Guided Augmentation. Furthermore, we adopted a meta-learning framework which integrates these three blocks to improve domain generalization on unseen target domains. Two new datasets were proposed for this problem, named AWA2-LTS and ImageNet-LTS. We evaluated our method on the two datasets and extensive experimental results demonstrate that our proposed method can achieve superior performance over state-of-the-art long-tailed/domain generalization approaches and the combinations. Source codes and datasets can be found at our project page https://xiaogu.site/LTDS.
Human-Robot Shared Control for Surgical Robot Based on Context-Aware Sim-to-Real Adaptation
Apr 23, 2022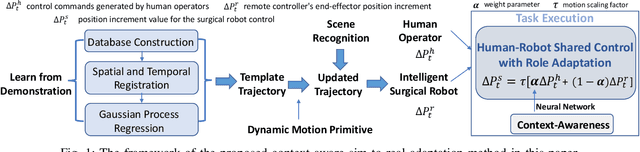
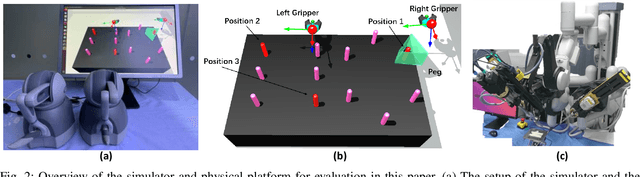
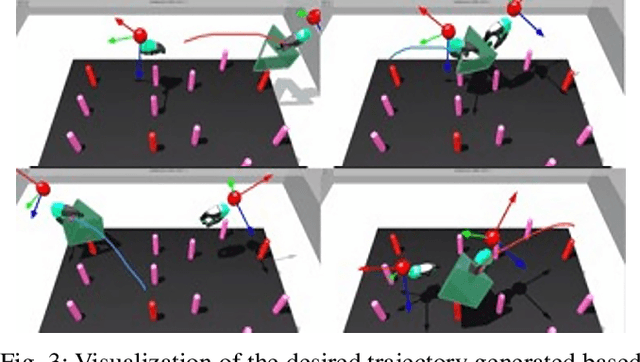
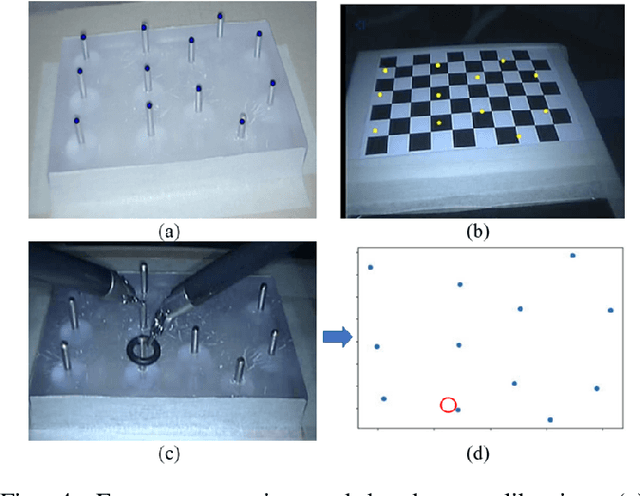
Human-robot shared control, which integrates the advantages of both humans and robots, is an effective approach to facilitate efficient surgical operation. Learning from demonstration (LfD) techniques can be used to automate some of the surgical subtasks for the construction of the shared control mechanism. However, a sufficient amount of data is required for the robot to learn the manoeuvres. Using a surgical simulator to collect data is a less resource-demanding approach. With sim-to-real adaptation, the manoeuvres learned from a simulator can be transferred to a physical robot. To this end, we propose a sim-to-real adaptation method to construct a human-robot shared control framework for robotic surgery. In this paper, a desired trajectory is generated from a simulator using LfD method, while dynamic motion primitives (DMP) is used to transfer the desired trajectory from the simulator to the physical robotic platform. Moreover, a role adaptation mechanism is developed such that the robot can adjust its role according to the surgical operation contexts predicted by a neural network model. The effectiveness of the proposed framework is validated on the da Vinci Research Kit (dVRK). Results of the user studies indicated that with the adaptive human-robot shared control framework, the path length of the remote controller, the total clutching number and the task completion time can be reduced significantly. The proposed method outperformed the traditional manual control via teleoperation.
A Long Short-term Memory Based Recurrent Neural Network for Interventional MRI Reconstruction
Apr 12, 2022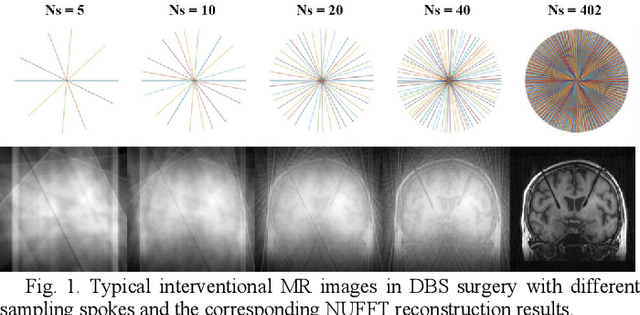
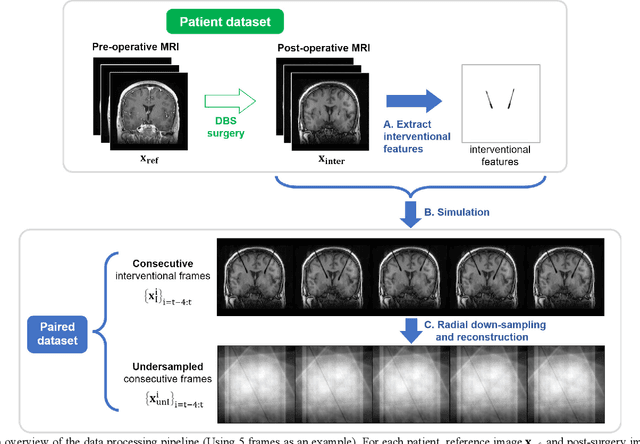
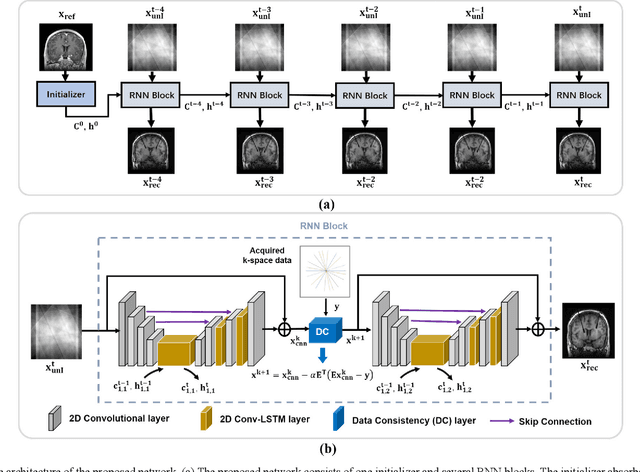
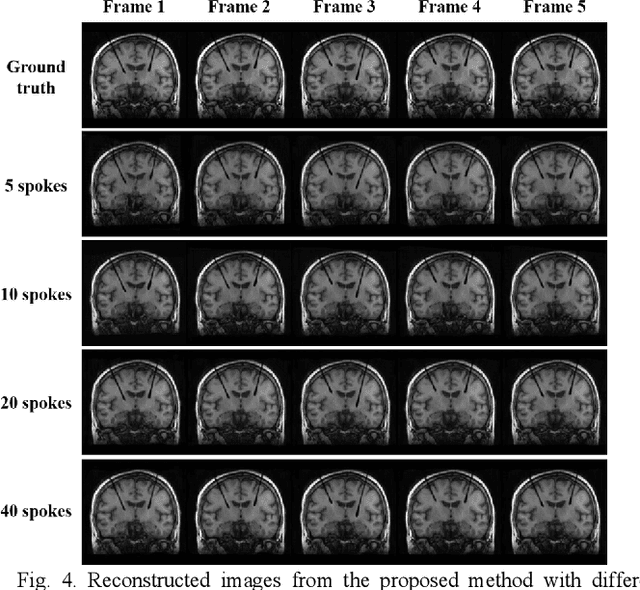
Interventional magnetic resonance imaging (i-MRI) for surgical guidance could help visualize the interventional process such as deep brain stimulation (DBS), improving the surgery performance and patient outcome. Different from retrospective reconstruction in conventional dynamic imaging, i-MRI for DBS has to acquire and reconstruct the interventional images sequentially online. Here we proposed a convolutional long short-term memory (Conv-LSTM) based recurrent neural network (RNN), or ConvLR, to reconstruct interventional images with golden-angle radial sampling. By using an initializer and Conv-LSTM blocks, the priors from the pre-operative reference image and intra-operative frames were exploited for reconstructing the current frame. Data consistency for radial sampling was implemented by a soft-projection method. To improve the reconstruction accuracy, an adversarial learning strategy was adopted. A set of interventional images based on the pre-operative and post-operative MR images were simulated for algorithm validation. Results showed with only 10 radial spokes, ConvLR provided the best performance compared with state-of-the-art methods, giving an acceleration up to 40 folds. The proposed algorithm has the potential to achieve real-time i-MRI for DBS and can be used for general purpose MR-guided intervention.
Faithful learning with sure data for lung nodule diagnosis
Feb 25, 2022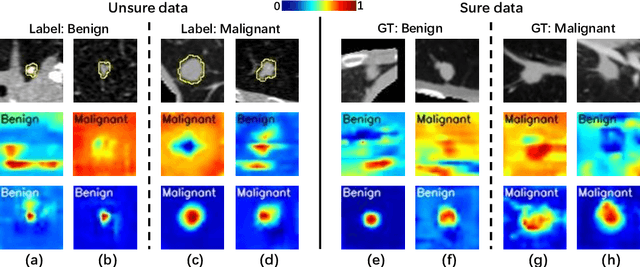
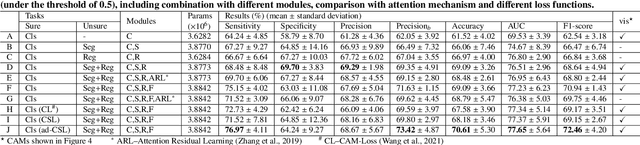
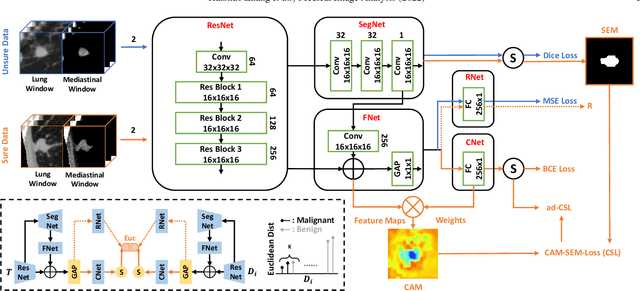

Recent evolution in deep learning has proven its value for CT-based lung nodule classification. Most current techniques are intrinsically black-box systems, suffering from two generalizability issues in clinical practice. First, benign-malignant discrimination is often assessed by human observers without pathologic diagnoses at the nodule level. We termed these data as "unsure data". Second, a classifier does not necessarily acquire reliable nodule features for stable learning and robust prediction with patch-level labels during learning. In this study, we construct a sure dataset with pathologically-confirmed labels and propose a collaborative learning framework to facilitate sure nodule classification by integrating unsure data knowledge through nodule segmentation and malignancy score regression. A loss function is designed to learn reliable features by introducing interpretability constraints regulated with nodule segmentation maps. Furthermore, based on model inference results that reflect the understanding from both machine and experts, we explore a new nodule analysis method for similar historical nodule retrieval and interpretable diagnosis. Detailed experimental results demonstrate that our approach is beneficial for achieving improved performance coupled with faithful model reasoning for lung cancer prediction. Extensive cross-evaluation results further illustrate the effect of unsure data for deep-learning-based methods in lung nodule classification.
Occlusion-Invariant Rotation-Equivariant Semi-Supervised Depth Based Cross-View Gait Pose Estimation
Sep 03, 2021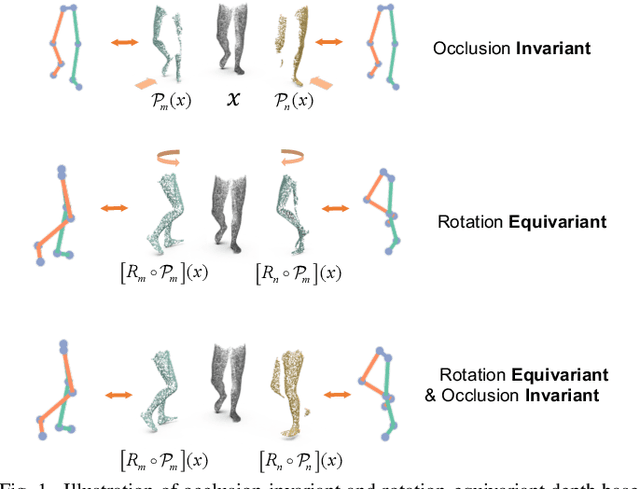
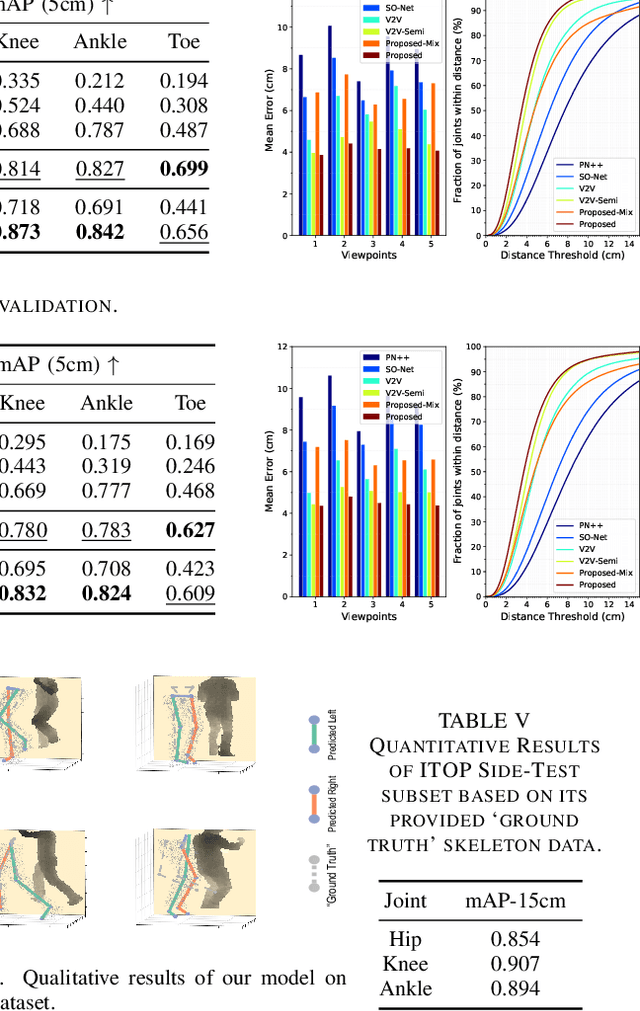
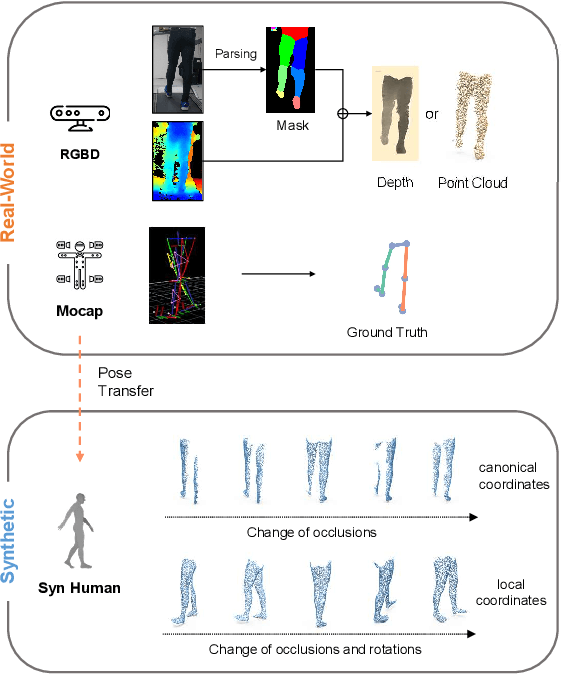
Accurate estimation of three-dimensional human skeletons from depth images can provide important metrics for healthcare applications, especially for biomechanical gait analysis. However, there exist inherent problems associated with depth images captured from a single view. The collected data is greatly affected by occlusions where only partial surface data can be recorded. Furthermore, depth images of human body exhibit heterogeneous characteristics with viewpoint changes, and the estimated poses under local coordinate systems are expected to go through equivariant rotations. Most existing pose estimation models are sensitive to both issues. To address this, we propose a novel approach for cross-view generalization with an occlusion-invariant semi-supervised learning framework built upon a novel rotation-equivariant backbone. Our model was trained with real-world data from a single view and unlabelled synthetic data from multiple views. It can generalize well on the real-world data from all the other unseen views. Our approach has shown superior performance on gait analysis on our ICL-Gait dataset compared to other state-of-the-arts and it can produce more convincing keypoints on ITOP dataset, than its provided "ground truth".
TransAction: ICL-SJTU Submission to EPIC-Kitchens Action Anticipation Challenge 2021
Jul 28, 2021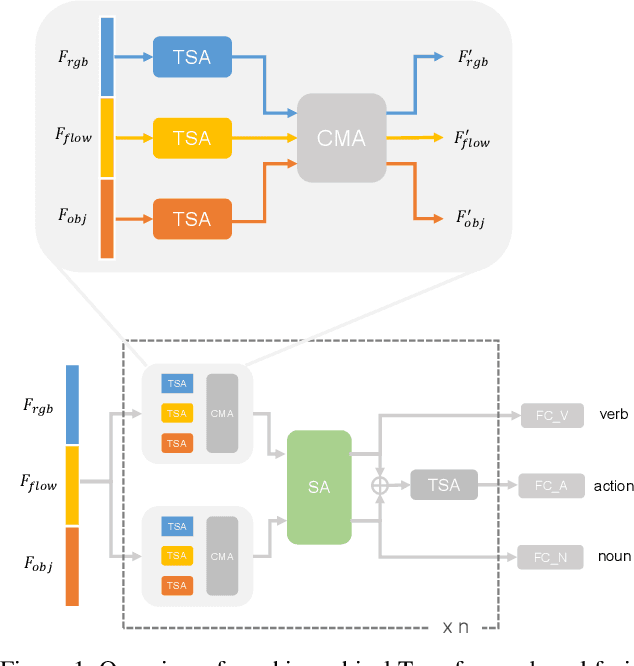
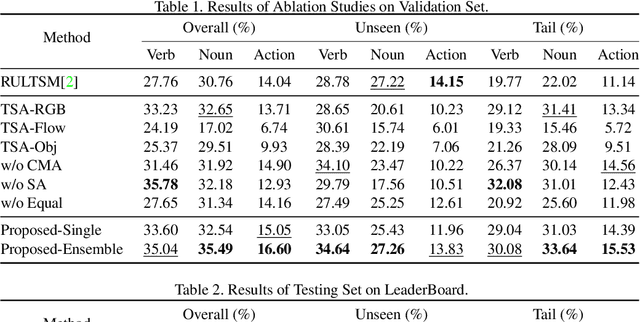
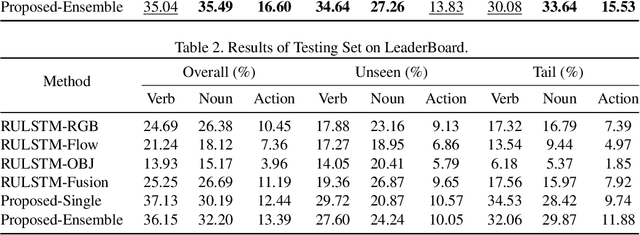
In this report, the technical details of our submission to the EPIC-Kitchens Action Anticipation Challenge 2021 are given. We developed a hierarchical attention model for action anticipation, which leverages Transformer-based attention mechanism to aggregate features across temporal dimension, modalities, symbiotic branches respectively. In terms of Mean Top-5 Recall of action, our submission with team name ICL-SJTU achieved 13.39% for overall testing set, 10.05% for unseen subsets and 11.88% for tailed subsets. Additionally, it is noteworthy that our submission ranked 1st in terms of verb class in all three (sub)sets.
Robotic Electrospinning Actuated by Non-Circular Joint Continuum Manipulator for Endoluminal Therapy
Jun 07, 2021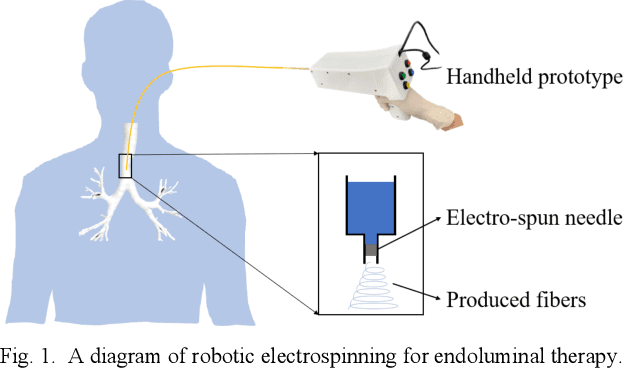
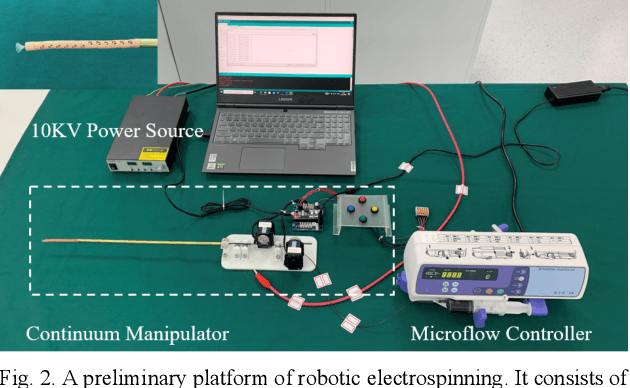
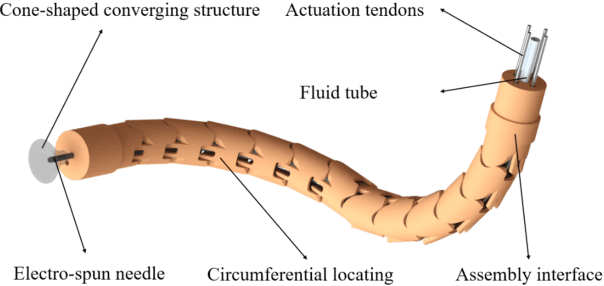
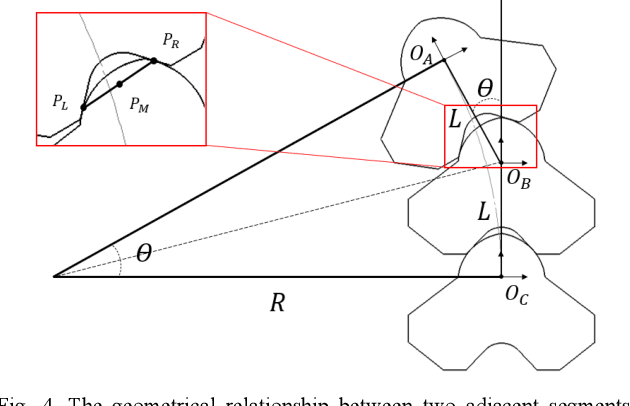
Electrospinning has exhibited excellent benefits to treat the trauma for tissue engineering due to its produced micro/nano fibrous structure. It can effectively adhere to the tissue surface for long-term continuous therapy. This paper develops a robotic electrospinning platform for endoluminal therapy. The platform consists of a continuum manipulator, the electrospinning device, and the actuation unit. The continuum manipulator has two bending sections to facilitate the steering of the tip needle for a controllable spinning direction. Non-circular joint profile is carefully designed to enable a constant length of the centreline of a continuum manipulator for stable fluid transmission inside it. Experiments are performed on a bronchus phantom, and the steering ability and bending limitation in each direction are also investigated. The endoluminal electrospinning is also fulfilled by a trajectory following and points targeting experiments. The effective adhesive area of the produced fibre is also illustrated. The proposed robotic electrospinning shows its feasibility to precisely spread more therapeutic drug to construct fibrous structure for potential endoluminal treatment.