 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and Scalable Signal Inference for Active Robotic Source Seeking
Jan 06, 2023



In active source seeking, a robot takes repeated measurements in order to locate a signal source in a cluttered and unknown environment. A key component of an active source seeking robot planner is a model that can produce estimates of the signal at unknown locations with uncertainty quantification. This model allows the robot to plan for future measurements in the environment. Traditionally, this model has been in the form of a Gaussian process, which has difficulty scaling and cannot represent obstacles. %In this work, We propose a global and local factor graph model for active source seeking, which allows the model to scale to a large number of measurements and represent unknown obstacles in the environment. We combine this model with extensions to a highly scalable planner to form a system for large-scale active source seeking. We demonstrate that our approach outperforms baseline methods in both simulated and real robot experiments.
OpenD: A Benchmark for Language-Driven Door and Drawer Opening
Dec 10, 2022



We introduce OPEND, a benchmark for learning how to use a hand to open cabinet doors or drawers in a photo-realistic and physics-reliable simulation environment driven by language instruction. To solve the task, we propose a multi-step planner composed of a deep neural network and rule-base controllers. The network is utilized to capture spatial relationships from images and understand semantic meaning from language instructions. Controllers efficiently execute the plan based on the spatial and semantic understanding. We evaluate our system by measuring its zero-shot performance in test data set. Experimental results demonstrate the effectiveness of decision planning by our multi-step planner for different hands, while suggesting that there is significant room for developing better models to address the challenge brought by language understanding, spatial reasoning, and long-term manipulation. We will release OPEND and host challenges to promote future research in this area.
CLIP-Nav: Using CLIP for Zero-Shot Vision-and-Language Navigation
Nov 30, 2022



Household environments are visually diverse. Embodied agents performing Vision-and-Language Navigation (VLN) in the wild must be able to handle this diversity, while also following arbitrary language instructions. Recently, Vision-Language models like CLIP have shown great performance on the task of zero-shot object recognition. In this work, we ask if these models are also capable of zero-shot language grounding. In particular, we utilize CLIP to tackle the novel problem of zero-shot VLN using natural language referring expressions that describe target objects, in contrast to past work that used simple language templates describing object classes. We examine CLIP's capability in making sequential navigational decisions without any dataset-specific finetuning, and study how it influences the path that an agent takes. Our results on the coarse-grained instruction following task of REVERIE demonstrate the navigational capability of CLIP, surpassing the supervised baseline in terms of both success rate (SR) and success weighted by path length (SPL). More importantly, we quantitatively show that our CLIP-based zero-shot approach generalizes better to show consistent performance across environments when compared to SOTA, fully supervised learning approaches when evaluated via Relative Change in Success (RCS).
Efficiently Learning Small Policies for Locomotion and Manipulation
Sep 30, 2022



Neural control of memory-constrained, agile robots requires small, yet highly performant models. We leverage graph hyper networks to learn graph hyper policies trained with off-policy reinforcement learning resulting in networks that are two orders of magnitude smaller than commonly used networks yet encode policies comparable to those encoded by much larger networks trained on the same task. We show that our method can be appended to any off-policy reinforcement learning algorithm, without any change in hyperparameters, by showing results across locomotion and manipulation tasks. Further, we obtain an array of working policies, with differing numbers of parameters, allowing us to pick an optimal network for the memory constraints of a system. Training multiple policies with our method is as sample efficient as training a single policy. Finally, we provide a method to select the best architecture, given a constraint on the number of parameters. Project website: https://sites.google.com/usc.edu/graphhyperpolicy
CH-MARL: A Multimodal Benchmark for Cooperative, Heterogeneous Multi-Agent Reinforcement Learning
Aug 26, 2022
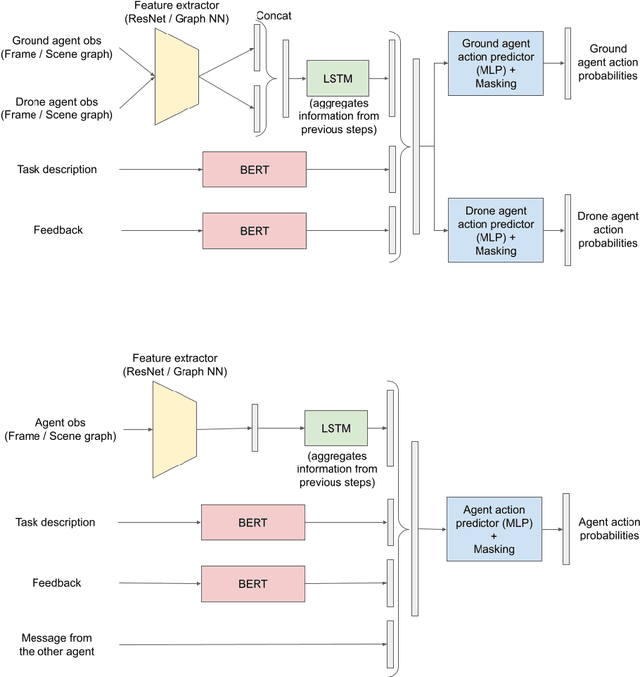


We propose a multimodal (vision-and-language) benchmark for cooperative and heterogeneous multi-agent learning. We introduce a benchmark multimodal dataset with tasks involving collaboration between multiple simulated heterogeneous robots in a rich multi-room home environment. We provide an integrated learning framework, multimodal implementations of state-of-the-art multi-agent reinforcement learning techniques, and a consistent evaluation protocol. Our experiments investigate the impact of different modalities on multi-agent learning performance. We also introduce a simple message passing method between agents. The results suggest that multimodality introduces unique challenges for cooperative multi-agent learning and there is significant room for advancing multi-agent reinforcement learning methods in such settings.
Decentralized Risk-Aware Tracking of Multiple Targets
Aug 04, 2022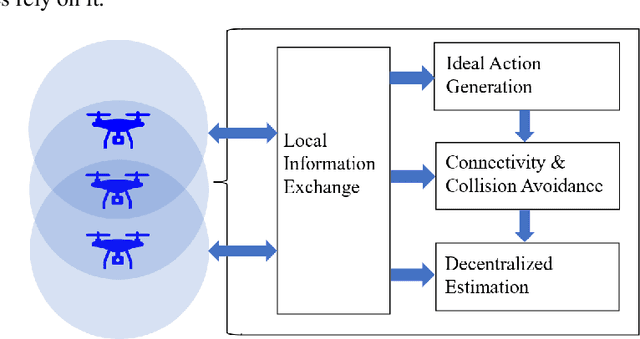
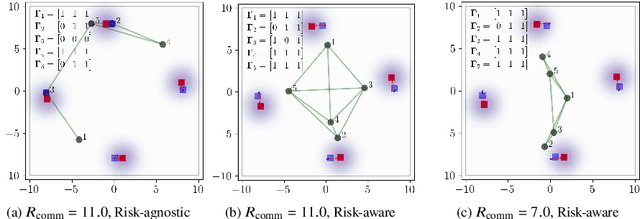
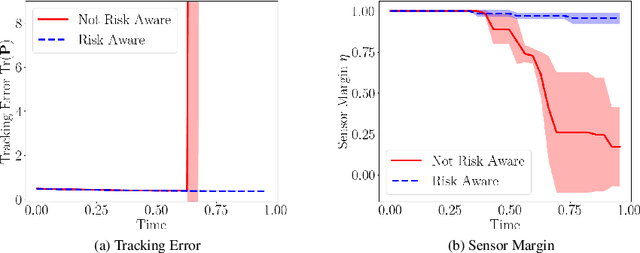
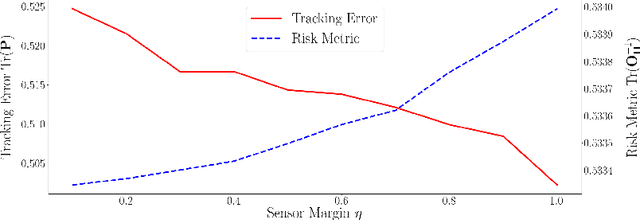
We consider the setting where a team of robots is tasked with tracking multiple targets with the following property: approaching the targets enables more accurate target position estimation, but also increases the risk of sensor failures. Therefore, it is essential to address the trade-off between tracking quality maximization and risk minimization. In our previous work, a centralized controller is developed to plan motions for all the robots -- however, this is not a scalable approach. Here, we present a decentralized and risk-aware multi-target tracking framework, in which each robot plans its motion trading off tracking accuracy maximization and aversion to risk, while only relying on its own information and information exchanged with its neighbors. We use the control barrier function to guarantee network connectivity throughout the tracking process. Extensive numerical experiments demonstrate that our system can achieve similar tracking accuracy and risk-awareness to its centralized counterpart.
Learning Deformable Object Manipulation from Expert Demonstrations
Jul 20, 2022
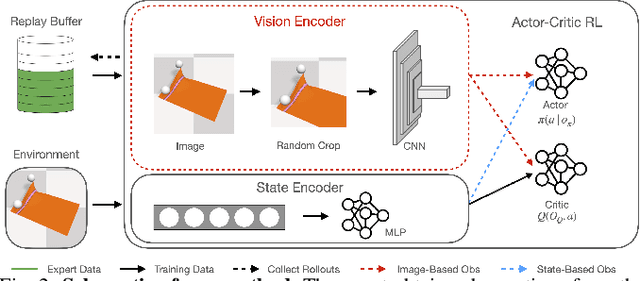
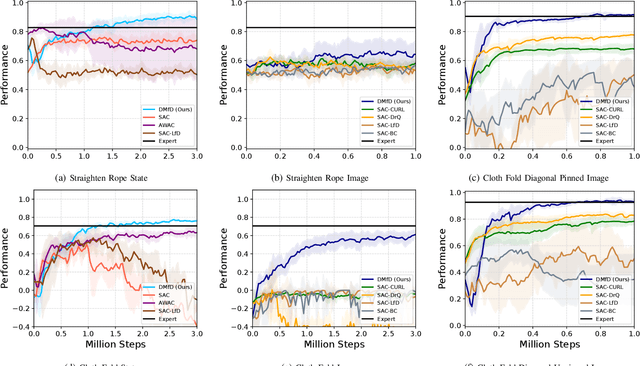
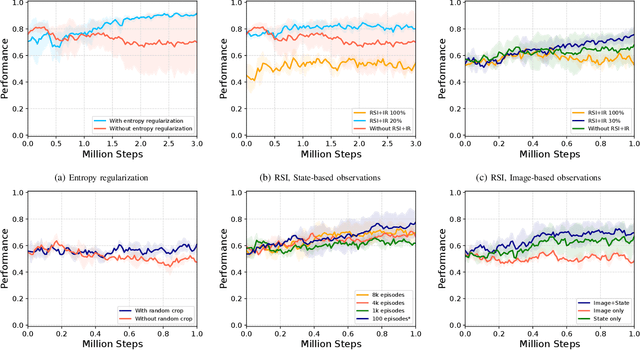
We present a novel Learning from Demonstration (LfD) method, Deformable Manipulation from Demonstrations (DMfD), to solve deformable manipulation tasks using states or images as inputs, given expert demonstrations. Our method uses demonstrations in three different ways, and balances the trade-off between exploring the environment online and using guidance from experts to explore high dimensional spaces effectively. We test DMfD on a set of representative manipulation tasks for a 1-dimensional rope and a 2-dimensional cloth from the SoftGym suite of tasks, each with state and image observations. Our method exceeds baseline performance by up to 12.9% for state-based tasks and up to 33.44% on image-based tasks, with comparable or better robustness to randomness. Additionally, we create two challenging environments for folding a 2D cloth using image-based observations, and set a performance benchmark for them. We deploy DMfD on a real robot with a minimal loss in normalized performance during real-world execution compared to simulation (~6%). Source code is on github.com/uscresl/dmfd
* Accepted to IEEE Robotics & Automation Letters (RA-L) and IEEE IROS 2022. Project website: https://uscresl.github.io/dmfd
A Simple Approach for Visual Rearrangement: 3D Mapping and Semantic Search
Jun 21, 2022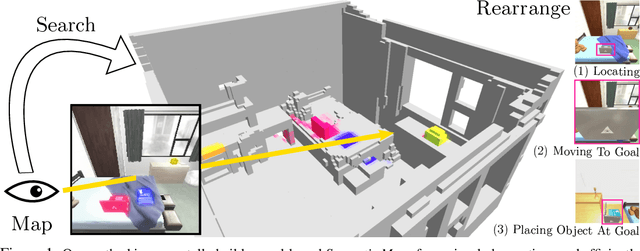
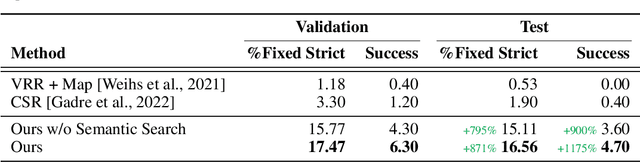
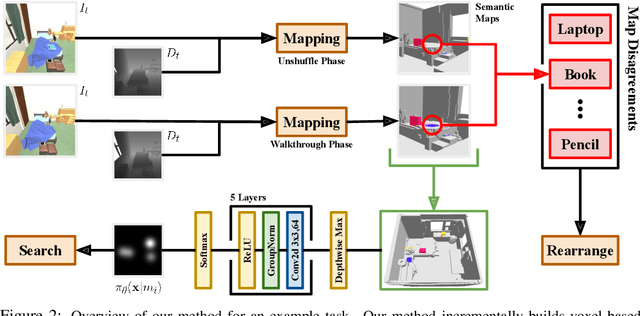
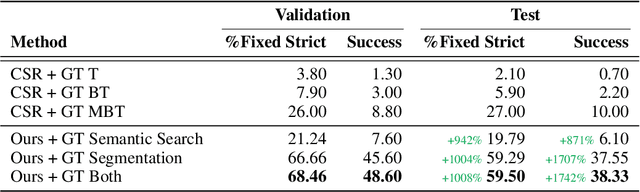
Physically rearranging objects is an important capability for embodied agents. Visual room rearrangement evaluates an agent's ability to rearrange objects in a room to a desired goal based solely on visual input. We propose a simple yet effective method for this problem: (1) search for and map which objects need to be rearranged, and (2) rearrange each object until the task is complete. Our approach consists of an off-the-shelf semantic segmentation model, voxel-based semantic map, and semantic search policy to efficiently find objects that need to be rearranged. On the AI2-THOR Rearrangement Challenge, our method improves on current state-of-the-art end-to-end reinforcement learning-based methods that learn visual rearrangement policies from 0.53% correct rearrangement to 16.56%, using only 2.7% as many samples from the environment.
Loop Closure Prioritization for Efficient and Scalable Multi-Robot SLAM
May 24, 2022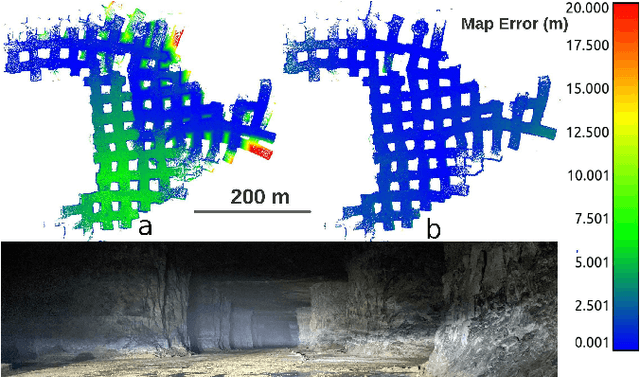
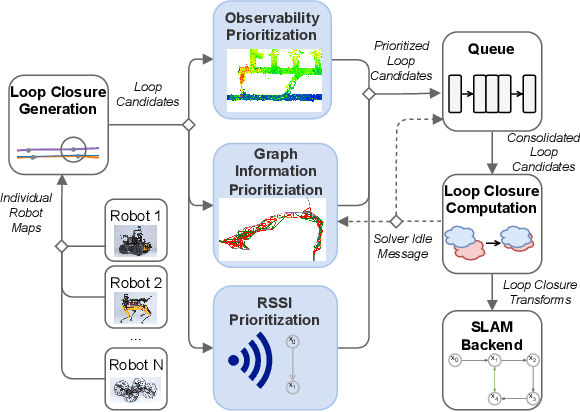
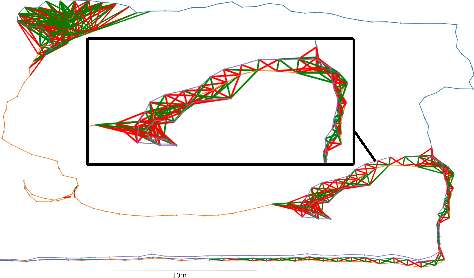
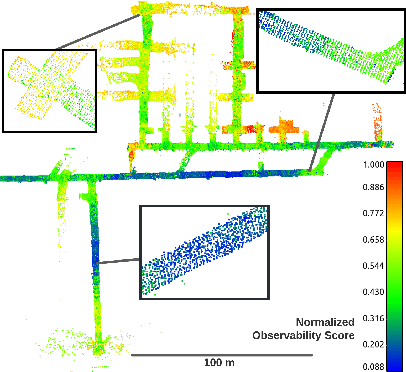
Multi-robot SLAM systems in GPS-denied environments require loop closures to maintain a drift-free centralized map. With an increasing number of robots and size of the environment, checking and computing the transformation for all the loop closure candidates becomes computationally infeasible. In this work, we describe a loop closure module that is able to prioritize which loop closures to compute based on the underlying pose graph, the proximity to known beacons, and the characteristics of the point clouds. We validate this system in the context of the DARPA Subterranean Challenge and on numerous challenging underground datasets and demonstrate the ability of this system to generate and maintain a map with low error. We find that our proposed techniques are able to select effective loop closures which results in 51% mean reduction in median error when compared to an odometric solution and 75% mean reduction in median error when compared to a baseline version of this system with no prioritization. We also find our proposed system is able to find a lower error in the mission time of one hour when compared to a system that processes every possible loop closure in four and a half hours.
Inferring Articulated Rigid Body Dynamics from RGBD Video
Mar 20, 2022
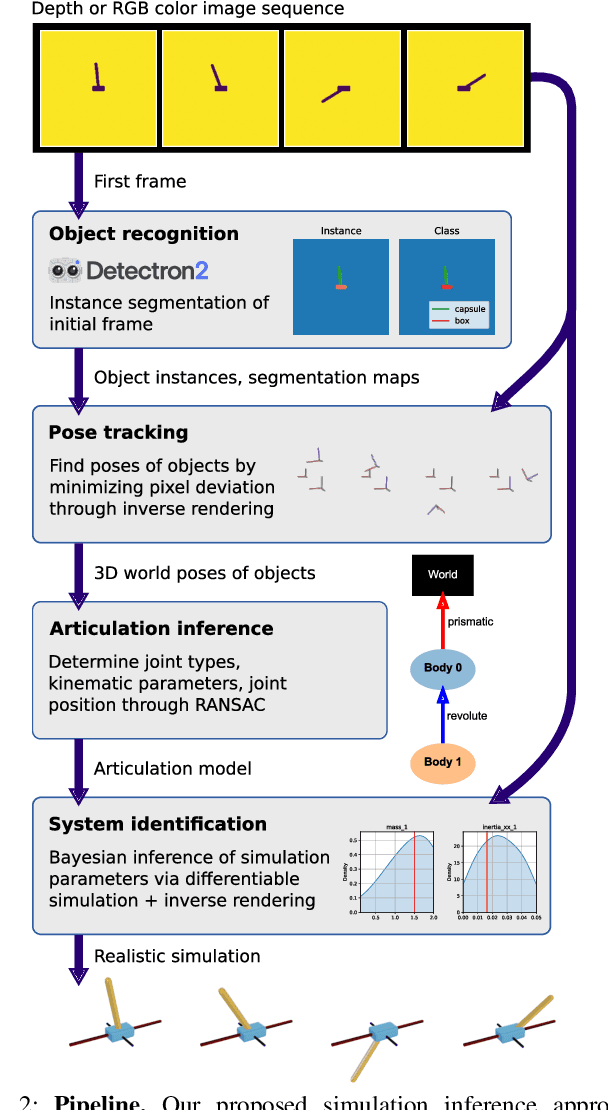
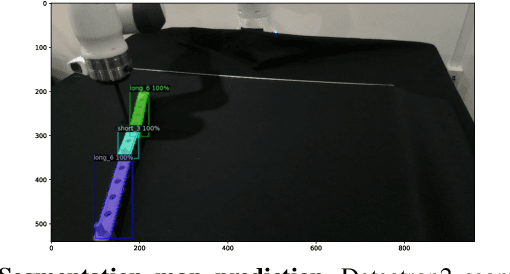
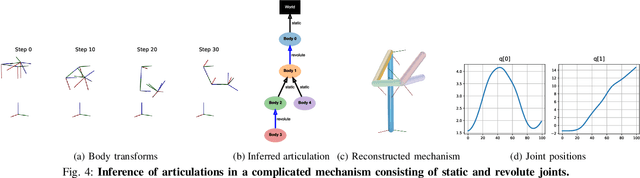
Being able to reproduce physical phenomena ranging from light interaction to contact mechanics, simulators are becoming increasingly useful in more and more application domains where real-world interaction or labeled data are difficult to obtain. Despite recent progress, significant human effort is needed to configure simulators to accurately reproduce real-world behavior. We introduce a pipeline that combines inverse rendering with differentiable simulation to create digital twins of real-world articulated mechanisms from depth or RGB videos. Our approach automatically discovers joint types and estimates their kinematic parameters, while the dynamic properties of the overall mechanism are tuned to attain physically accurate simulations. Control policies optimized in our derived simulation transfer successfully back to the original system, as we demonstrate on a simulated system. Further, our approach accurately reconstructs the kinematic tree of an articulated mechanism being manipulated by a robot, and highly nonlinear dynamics of a real-world coupled pendulum mechanism. Website: https://eric-heiden.github.io/video2sim