 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteering Multirobot Behavior via Closed-Loop Affine Activation Editing
Jun 09, 2026Real-world robots need to adapt their behavior beyond the envelope of their pre-trained policy. Policy finetuning or retraining are options, but they risk catastrophic forgetting, degrading the pretrained policy's base performance. To combat this, we introduce CLAE: Closed-Loop Affine Activation Editing, an inference-time framework for steering the behavior of a frozen policy by editing intermediate activations while keeping the base policy weights and downstream action head untouched. CLAE approaches behavior steering as a closed-loop problem whose outputs edit policy activations that adapt online to the robot state, environment, target behavior, and multi-robot context. It trains a sparse autoencoder over frozen-policy activations, selects behavior-relevant latent features via post-hoc probing, and learns a lightweight RL-based steering policy that applies state-dependent affine edits to selected latents during inference. We validate CLAE on a frozen multi-quadrotor navigation policy trained to perform a single task: navigating robots to a set of goal locations while avoiding obstacles. Through extensive simulations and physical tests, we show that while navigating to their goal positions, CLAE can 1. steer individual robot behavior by controlling each robot's velocity profile; 2. coordinate multirobot behavior by preserving a desired formation; and 3. produce entirely new behavior wherein robots are required to reduce their exposure to surveillance cameras in the environment.
Latent Weight Diffusion: Generating Policies from Trajectories
Oct 17, 2024With the increasing availability of open-source robotic data, imitation learning has emerged as a viable approach for both robot manipulation and locomotion. Currently, large generalized policies are trained to predict controls or trajectories using diffusion models, which have the desirable property of learning multimodal action distributions. However, generalizability comes with a cost - namely, larger model size and slower inference. Further, there is a known trade-off between performance and action horizon for Diffusion Policy (i.e., diffusing trajectories): fewer diffusion queries accumulate greater trajectory tracking errors. Thus, it is common practice to run these models at high inference frequency, subject to robot computational constraints. To address these limitations, we propose Latent Weight Diffusion (LWD), a method that uses diffusion to learn a distribution over policies for robotic tasks, rather than over trajectories. Our approach encodes demonstration trajectories into a latent space and then decodes them into policies using a hypernetwork. We employ a diffusion denoising model within this latent space to learn its distribution. We demonstrate that LWD can reconstruct the behaviors of the original policies that generated the trajectory dataset. LWD offers the benefits of considerably smaller policy networks during inference and requires fewer diffusion model queries. When tested on the Metaworld MT10 benchmark, LWD achieves a higher success rate compared to a vanilla multi-task policy, while using models up to ~18x smaller during inference. Additionally, since LWD generates closed-loop policies, we show that it outperforms Diffusion Policy in long action horizon settings, with reduced diffusion queries during rollout.
HyperPPO: A scalable method for finding small policies for robotic control
Sep 28, 2023



Models with fewer parameters are necessary for the neural control of memory-limited, performant robots. Finding these smaller neural network architectures can be time-consuming. We propose HyperPPO, an on-policy reinforcement learning algorithm that utilizes graph hypernetworks to estimate the weights of multiple neural architectures simultaneously. Our method estimates weights for networks that are much smaller than those in common-use networks yet encode highly performant policies. We obtain multiple trained policies at the same time while maintaining sample efficiency and provide the user the choice of picking a network architecture that satisfies their computational constraints. We show that our method scales well - more training resources produce faster convergence to higher-performing architectures. We demonstrate that the neural policies estimated by HyperPPO are capable of decentralized control of a Crazyflie2.1 quadrotor. Website: https://sites.google.com/usc.edu/hyperppo
Generating Behaviorally Diverse Policies with Latent Diffusion Models
May 30, 2023Recent progress in Quality Diversity Reinforcement Learning (QD-RL) has enabled learning a collection of behaviorally diverse, high performing policies. However, these methods typically involve storing thousands of policies, which results in high space-complexity and poor scaling to additional behaviors. Condensing the archive into a single model while retaining the performance and coverage of the original collection of policies has proved challenging. In this work, we propose using diffusion models to distill the archive into a single generative model over policy parameters. We show that our method achieves a compression ratio of 13x while recovering 98% of the original rewards and 89% of the original coverage. Further, the conditioning mechanism of diffusion models allows for flexibly selecting and sequencing behaviors, including using language. Project website: https://sites.google.com/view/policydiffusion/home
Efficiently Learning Small Policies for Locomotion and Manipulation
Sep 30, 2022



Neural control of memory-constrained, agile robots requires small, yet highly performant models. We leverage graph hyper networks to learn graph hyper policies trained with off-policy reinforcement learning resulting in networks that are two orders of magnitude smaller than commonly used networks yet encode policies comparable to those encoded by much larger networks trained on the same task. We show that our method can be appended to any off-policy reinforcement learning algorithm, without any change in hyperparameters, by showing results across locomotion and manipulation tasks. Further, we obtain an array of working policies, with differing numbers of parameters, allowing us to pick an optimal network for the memory constraints of a system. Training multiple policies with our method is as sample efficient as training a single policy. Finally, we provide a method to select the best architecture, given a constraint on the number of parameters. Project website: https://sites.google.com/usc.edu/graphhyperpolicy
Agents that Listen: High-Throughput Reinforcement Learning with Multiple Sensory Systems
Jul 05, 2021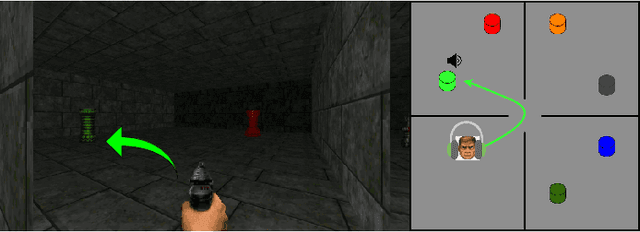
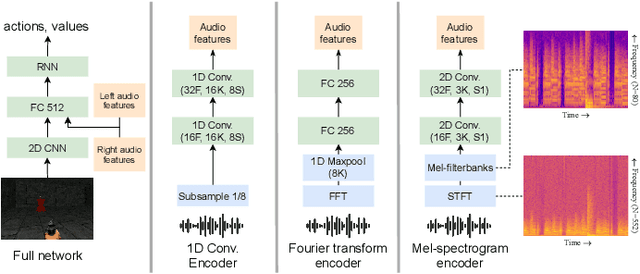

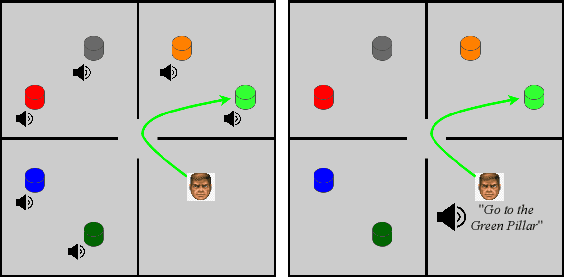
Humans and other intelligent animals evolved highly sophisticated perception systems that combine multiple sensory modalities. On the other hand, state-of-the-art artificial agents rely mostly on visual inputs or structured low-dimensional observations provided by instrumented environments. Learning to act based on combined visual and auditory inputs is still a new topic of research that has not been explored beyond simple scenarios. To facilitate progress in this area we introduce a new version of VizDoom simulator to create a highly efficient learning environment that provides raw audio observations. We study the performance of different model architectures in a series of tasks that require the agent to recognize sounds and execute instructions given in natural language. Finally, we train our agent to play the full game of Doom and find that it can consistently defeat a traditional vision-based adversary. We are currently in the process of merging the augmented simulator with the main ViZDoom code repository. Video demonstrations and experiment code can be found at https://sites.google.com/view/sound-rl.