 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkill Discovery for Software Scripting Automation via Offline Simulations with LLMs
Apr 29, 2025Scripting interfaces enable users to automate tasks and customize software workflows, but creating scripts traditionally requires programming expertise and familiarity with specific APIs, posing barriers for many users. While Large Language Models (LLMs) can generate code from natural language queries, runtime code generation is severely limited due to unverified code, security risks, longer response times, and higher computational costs. To bridge the gap, we propose an offline simulation framework to curate a software-specific skillset, a collection of verified scripts, by exploiting LLMs and publicly available scripting guides. Our framework comprises two components: (1) task creation, using top-down functionality guidance and bottom-up API synergy exploration to generate helpful tasks; and (2) skill generation with trials, refining and validating scripts based on execution feedback. To efficiently navigate the extensive API landscape, we introduce a Graph Neural Network (GNN)-based link prediction model to capture API synergy, enabling the generation of skills involving underutilized APIs and expanding the skillset's diversity. Experiments with Adobe Illustrator demonstrate that our framework significantly improves automation success rates, reduces response time, and saves runtime token costs compared to traditional runtime code generation. This is the first attempt to use software scripting interfaces as a testbed for LLM-based systems, highlighting the advantages of leveraging execution feedback in a controlled environment and offering valuable insights into aligning AI capabilities with user needs in specialized software domains.
GraphicBench: A Planning Benchmark for Graphic Design with Language Agents
Apr 15, 2025Large Language Model (LLM)-powered agents have unlocked new possibilities for automating human tasks. While prior work has focused on well-defined tasks with specified goals, the capabilities of agents in creative design tasks with open-ended goals remain underexplored. We introduce GraphicBench, a new planning benchmark for graphic design that covers 1,079 user queries and input images across four design types. We further present GraphicTown, an LLM agent framework with three design experts and 46 actions (tools) to choose from for executing each step of the planned workflows in web environments. Experiments with six LLMs demonstrate their ability to generate workflows that integrate both explicit design constraints from user queries and implicit commonsense constraints. However, these workflows often do not lead to successful execution outcomes, primarily due to challenges in: (1) reasoning about spatial relationships, (2) coordinating global dependencies across experts, and (3) retrieving the most appropriate action per step. We envision GraphicBench as a challenging yet valuable testbed for advancing LLM-agent planning and execution in creative design tasks.
Beyond Degradation Redundancy: Contrastive Prompt Learning for All-in-One Image Restoration
Apr 14, 2025
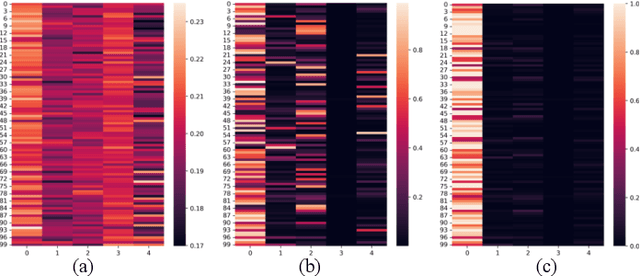


All-in-one image restoration, addressing diverse degradation types with a unified model, presents significant challenges in designing task-specific prompts that effectively guide restoration across multiple degradation scenarios. While adaptive prompt learning enables end-to-end optimization, it often yields overlapping or redundant task representations. Conversely, explicit prompts derived from pretrained classifiers enhance discriminability but may discard critical visual information for reconstruction. To address these limitations, we introduce Contrastive Prompt Learning (CPL), a novel framework that fundamentally enhances prompt-task alignment through two complementary innovations: a \emph{Sparse Prompt Module (SPM)} that efficiently captures degradation-specific features while minimizing redundancy, and a \emph{Contrastive Prompt Regularization (CPR)} that explicitly strengthens task boundaries by incorporating negative prompt samples across different degradation types. Unlike previous approaches that focus primarily on degradation classification, CPL optimizes the critical interaction between prompts and the restoration model itself. Extensive experiments across five comprehensive benchmarks demonstrate that CPL consistently enhances state-of-the-art all-in-one restoration models, achieving significant improvements in both standard multi-task scenarios and challenging composite degradation settings. Our framework establishes new state-of-the-art performance while maintaining parameter efficiency, offering a principled solution for unified image restoration.
Content-Aware Transformer for All-in-one Image Restoration
Apr 07, 2025



Image restoration has witnessed significant advancements with the development of deep learning models. Although Transformer architectures have progressed considerably in recent years, challenges remain, particularly the limited receptive field in window-based self-attention. In this work, we propose DSwinIR, a Deformable Sliding window Transformer for Image Restoration. DSwinIR introduces a novel deformable sliding window self-attention that adaptively adjusts receptive fields based on image content, enabling the attention mechanism to focus on important regions and enhance feature extraction aligned with salient features. Additionally, we introduce a central ensemble pattern to reduce the inclusion of irrelevant content within attention windows. In this way, the proposed DSwinIR model integrates the deformable sliding window Transformer and central ensemble pattern to amplify the strengths of both CNNs and Transformers while mitigating their limitations. Extensive experiments on various image restoration tasks demonstrate that DSwinIR achieves state-of-the-art performance. For example, in image deraining, compared to DRSformer on the SPA dataset, DSwinIR achieves a 0.66 dB PSNR improvement. In all-in-one image restoration, compared to PromptIR, DSwinIR achieves over a 0.66 dB and 1.04 dB improvement on three-task and five-task settings, respectively. Pretrained models and code are available at our project https://github.com/Aitical/DSwinIR.
ScreenLLM: Stateful Screen Schema for Efficient Action Understanding and Prediction
Mar 26, 2025Graphical User Interface (GUI) agents are autonomous systems that interpret and generate actions, enabling intelligent user assistance and automation. Effective training of these agent presents unique challenges, such as sparsity in supervision signals, scalability for large datasets, and the need for nuanced user understanding. We propose stateful screen schema, an efficient representation of GUI interactions that captures key user actions and intentions over time. Building on this foundation, we introduce ScreenLLM, a set of multimodal large language models (MLLMs) tailored for advanced UI understanding and action prediction. Extensive experiments on both open-source and proprietary models show that ScreenLLM accurately models user behavior and predicts actions. Our work lays the foundation for scalable, robust, and intelligent GUI agents that enhance user interaction in diverse software environments.
SKALD: Learning-Based Shot Assembly for Coherent Multi-Shot Video Creation
Mar 11, 2025
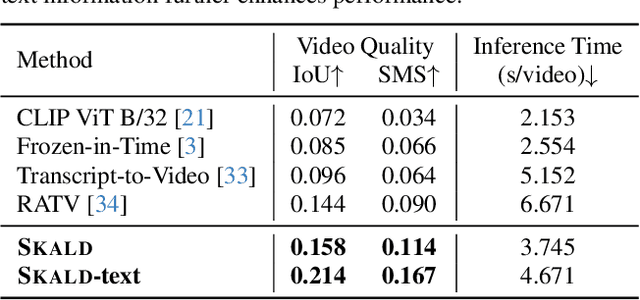

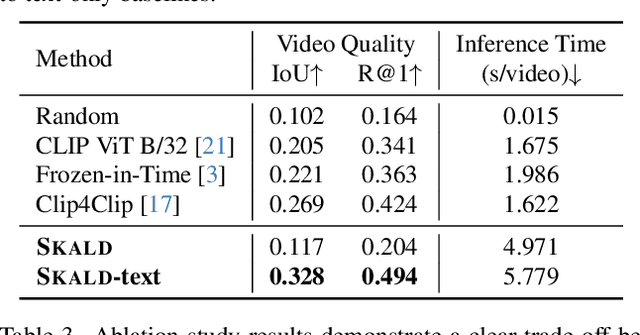
We present SKALD, a multi-shot video assembly method that constructs coherent video sequences from candidate shots with minimal reliance on text. Central to our approach is the Learned Clip Assembly (LCA) score, a learning-based metric that measures temporal and semantic relationships between shots to quantify narrative coherence. We tackle the exponential complexity of combining multiple shots with an efficient beam-search algorithm guided by the LCA score. To train our model effectively with limited human annotations, we propose two tasks for the LCA encoder: Shot Coherence Learning, which uses contrastive learning to distinguish coherent and incoherent sequences, and Feature Regression, which converts these learned representations into a real-valued coherence score. We develop two variants: a base SKALD model that relies solely on visual coherence and SKALD-text, which integrates auxiliary text information when available. Experiments on the VSPD and our curated MSV3C datasets show that SKALD achieves an improvement of up to 48.6% in IoU and a 43% speedup over the state-of-the-art methods. A user study further validates our approach, with 45% of participants favoring SKALD-assembled videos, compared to 22% preferring text-based assembly methods.
GUI-Bee: Align GUI Action Grounding to Novel Environments via Autonomous Exploration
Jan 27, 2025
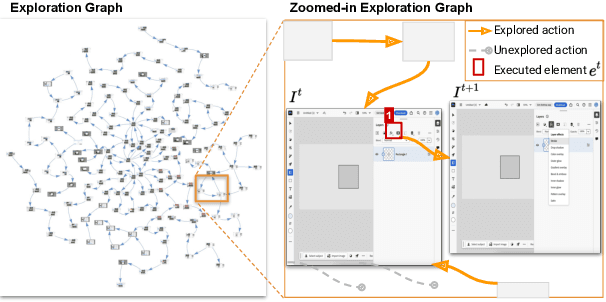
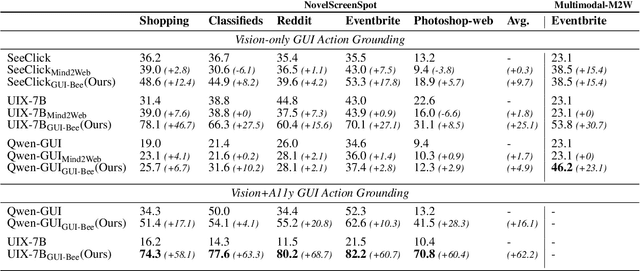
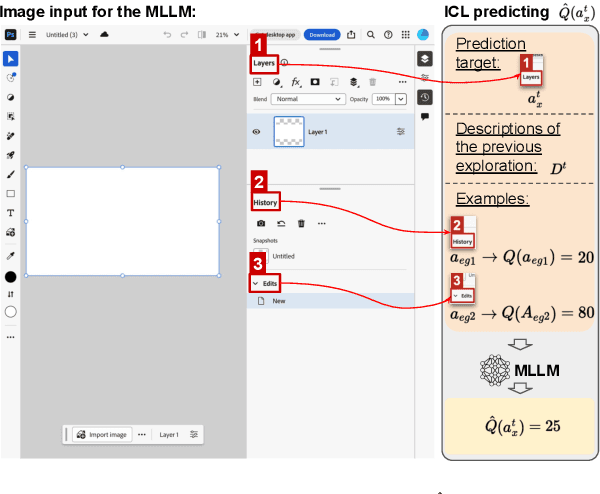
Graphical User Interface (GUI) action grounding is a critical step in GUI automation that maps language instructions to actionable elements on GUI screens. Most recent works of GUI action grounding leverage large GUI datasets to fine-tune MLLMs. However, the fine-tuning data always covers limited GUI environments, and we find the performance of the resulting model deteriorates in novel environments. We argue that the GUI grounding models should be further aligned to the novel environments to reveal their full potential, when the inference is known to involve novel environments, i.e., environments not used during the previous fine-tuning. To realize this, we first propose GUI-Bee, an MLLM-based autonomous agent, to collect high-quality, environment-specific data through exploration and then continuously fine-tune GUI grounding models with the collected data. Our agent leverages a novel Q-value-Incentive In-Context Reinforcement Learning (Q-ICRL) method to optimize exploration efficiency and data quality. Additionally, we introduce NovelScreenSpot, a benchmark for testing how well the data can help align GUI action grounding models to novel environments and demonstrate the effectiveness of data collected by GUI-Bee in the experiments. Furthermore, we conduct an ablation study to validate the Q-ICRL method in enhancing the efficiency of GUI-Bee. Project page: https://gui-bee.github.io
Knowledge Editing for Large Language Model with Knowledge Neuronal Ensemble
Dec 30, 2024



As real-world knowledge is constantly evolving, ensuring the timeliness and accuracy of a model's knowledge is crucial. This has made knowledge editing in large language models increasingly important. However, existing knowledge editing methods face several challenges, including parameter localization coupling, imprecise localization, and a lack of dynamic interaction across layers. In this paper, we propose a novel knowledge editing method called Knowledge Neuronal Ensemble (KNE). A knowledge neuronal ensemble represents a group of neurons encoding specific knowledge, thus mitigating the issue of frequent parameter modification caused by coupling in parameter localization. The KNE method enhances the precision and accuracy of parameter localization by computing gradient attribution scores for each parameter at each layer. During the editing process, only the gradients and losses associated with the knowledge neuronal ensemble are computed, with error backpropagation performed accordingly, ensuring dynamic interaction and collaborative updates among parameters. Experimental results on three widely used knowledge editing datasets show that the KNE method significantly improves the accuracy of knowledge editing and achieves, or even exceeds, the performance of the best baseline methods in portability and locality metrics.
GUI Agents: A Survey
Dec 18, 2024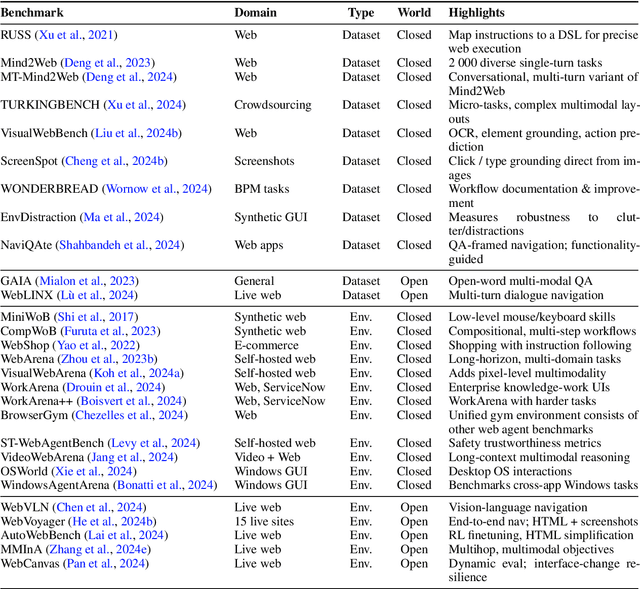
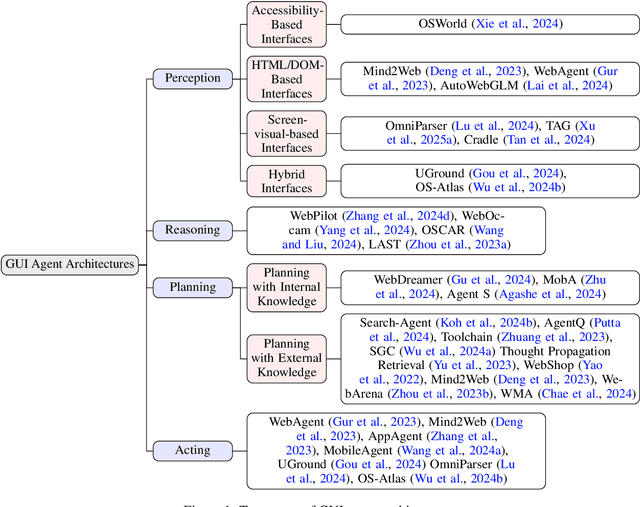

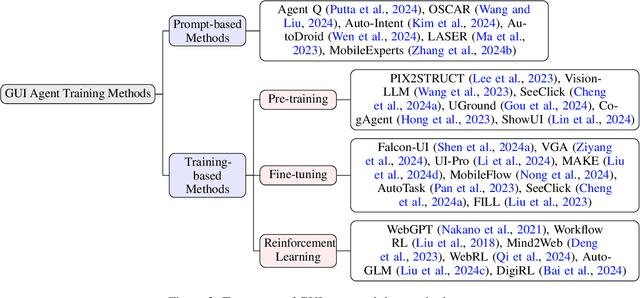
Graphical User Interface (GUI) agents, powered by Large Foundation Models, have emerged as a transformative approach to automating human-computer interaction. These agents autonomously interact with digital systems or software applications via GUIs, emulating human actions such as clicking, typing, and navigating visual elements across diverse platforms. Motivated by the growing interest and fundamental importance of GUI agents, we provide a comprehensive survey that categorizes their benchmarks, evaluation metrics, architectures, and training methods. We propose a unified framework that delineates their perception, reasoning, planning, and acting capabilities. Furthermore, we identify important open challenges and discuss key future directions. Finally, this work serves as a basis for practitioners and researchers to gain an intuitive understanding of current progress, techniques, benchmarks, and critical open problems that remain to be addressed.
Improving Domain Generalization in Self-supervised Monocular Depth Estimation via Stabilized Adversarial Training
Nov 05, 2024Learning a self-supervised Monocular Depth Estimation (MDE) model with great generalization remains significantly challenging. Despite the success of adversarial augmentation in the supervised learning generalization, naively incorporating it into self-supervised MDE models potentially causes over-regularization, suffering from severe performance degradation. In this paper, we conduct qualitative analysis and illuminate the main causes: (i) inherent sensitivity in the UNet-alike depth network and (ii) dual optimization conflict caused by over-regularization. To tackle these issues, we propose a general adversarial training framework, named Stabilized Conflict-optimization Adversarial Training (SCAT), integrating adversarial data augmentation into self-supervised MDE methods to achieve a balance between stability and generalization. Specifically, we devise an effective scaling depth network that tunes the coefficients of long skip connection and effectively stabilizes the training process. Then, we propose a conflict gradient surgery strategy, which progressively integrates the adversarial gradient and optimizes the model toward a conflict-free direction. Extensive experiments on five benchmarks demonstrate that SCAT can achieve state-of-the-art performance and significantly improve the generalization capability of existing self-supervised MDE methods.