 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFei Wu
ConfounderGAN: Protecting Image Data Privacy with Causal Confounder
Dec 04, 2022
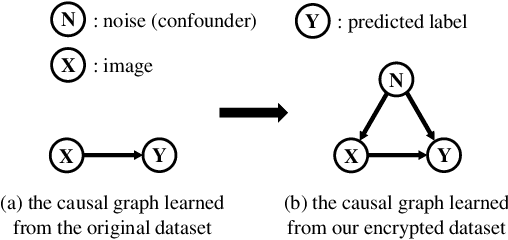
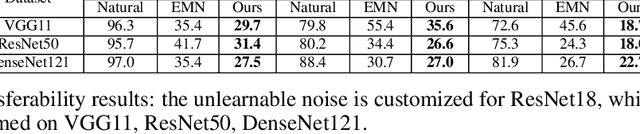
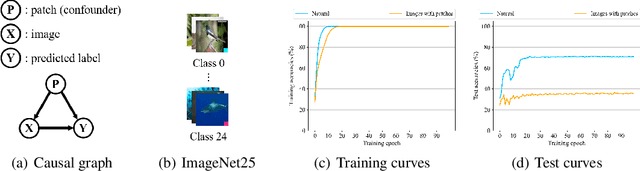
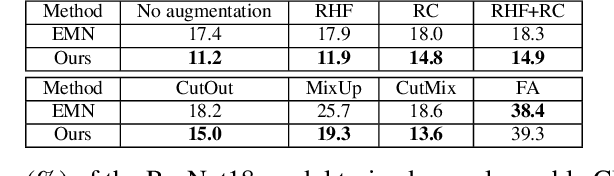
The success of deep learning is partly attributed to the availability of massive data downloaded freely from the Internet. However, it also means that users' private data may be collected by commercial organizations without consent and used to train their models. Therefore, it's important and necessary to develop a method or tool to prevent unauthorized data exploitation. In this paper, we propose ConfounderGAN, a generative adversarial network (GAN) that can make personal image data unlearnable to protect the data privacy of its owners. Specifically, the noise produced by the generator for each image has the confounder property. It can build spurious correlations between images and labels, so that the model cannot learn the correct mapping from images to labels in this noise-added dataset. Meanwhile, the discriminator is used to ensure that the generated noise is small and imperceptible, thereby remaining the normal utility of the encrypted image for humans. The experiments are conducted in six image classification datasets, consisting of three natural object datasets and three medical datasets. The results demonstrate that our method not only outperforms state-of-the-art methods in standard settings, but can also be applied to fast encryption scenarios. Moreover, we show a series of transferability and stability experiments to further illustrate the effectiveness and superiority of our method.
Confounder Balancing for Instrumental Variable Regression with Latent Variable
Nov 18, 2022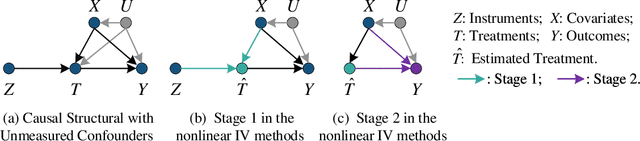
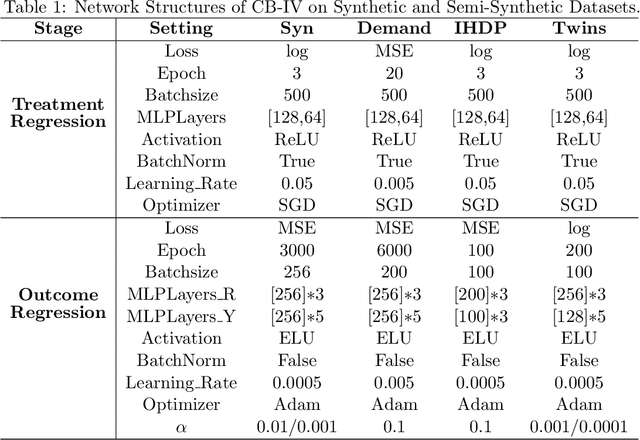
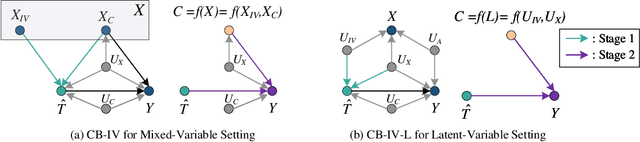
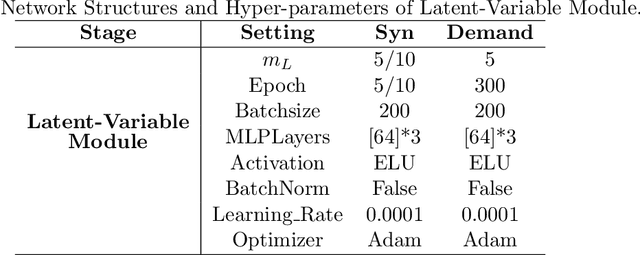
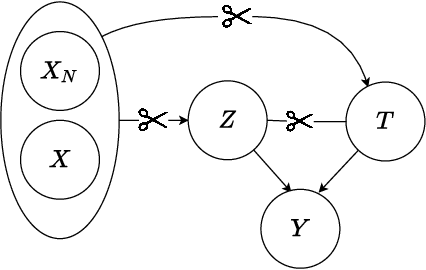
This paper studies the confounding effects from the unmeasured confounders and the imbalance of observed confounders in IV regression and aims at unbiased causal effect estimation. Recently, nonlinear IV estimators were proposed to allow for nonlinear model in both stages. However, the observed confounders may be imbalanced in stage 2, which could still lead to biased treatment effect estimation in certain cases. To this end, we propose a Confounder Balanced IV Regression (CB-IV) algorithm to jointly remove the bias from the unmeasured confounders and the imbalance of observed confounders. Theoretically, by redefining and solving an inverse problem for potential outcome function, we show that our CB-IV algorithm can unbiasedly estimate treatment effects and achieve lower variance. The IV methods have a major disadvantage in that little prior or theory is currently available to pre-define a valid IV in real-world scenarios. Thus, we study two more challenging settings without pre-defined valid IVs: (1) indistinguishable IVs implicitly present in observations, i.e., mixed-variable challenge, and (2) latent IVs don't appear in observations, i.e., latent-variable challenge. To address these two challenges, we extend our CB-IV by a latent-variable module, namely CB-IV-L algorithm. Extensive experiments demonstrate that our CB-IV(-L) outperforms the existing approaches.
Exploiting Contrastive Learning and Numerical Evidence for Improving Confusing Legal Judgment Prediction
Nov 15, 2022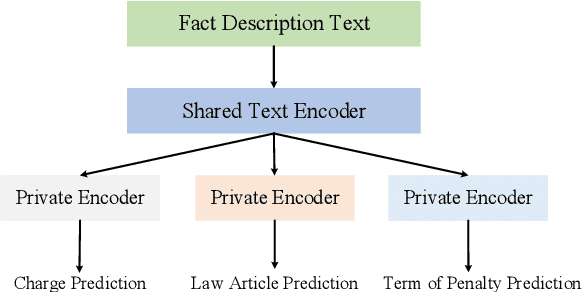
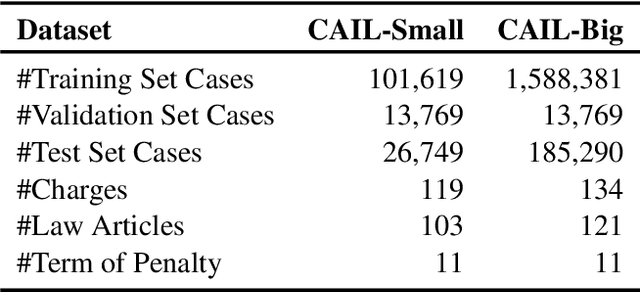
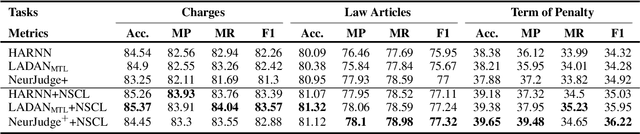
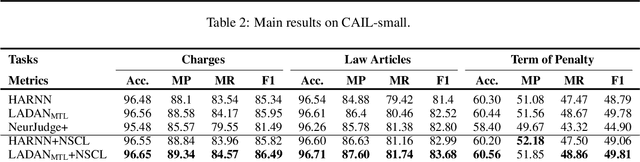
Given the fact description text of a legal case, legal judgment prediction (LJP) aims to predict the case's charge, law article and penalty term. A core problem of LJP is how to distinguish confusing legal cases, where only subtle text differences exist. Previous studies fail to distinguish different classification errors with a standard cross-entropy classification loss, and ignore the numbers in the fact description for predicting the term of penalty. To tackle these issues, in this work, first, we propose a moco-based supervised contrastive learning to learn distinguishable representations, and explore the best strategy to construct positive example pairs to benefit all three subtasks of LJP simultaneously. Second, in order to exploit the numbers in legal cases for predicting the penalty terms of certain cases, we further enhance the representation of the fact description with extracted crime amounts which are encoded by a pre-trained numeracy model. Extensive experiments on public benchmarks show that the proposed method achieves new state-of-the-art results, especially on confusing legal cases. Ablation studies also demonstrate the effectiveness of each component.
Learning Individual Treatment Effects under Heterogeneous Interference in Networks
Oct 25, 2022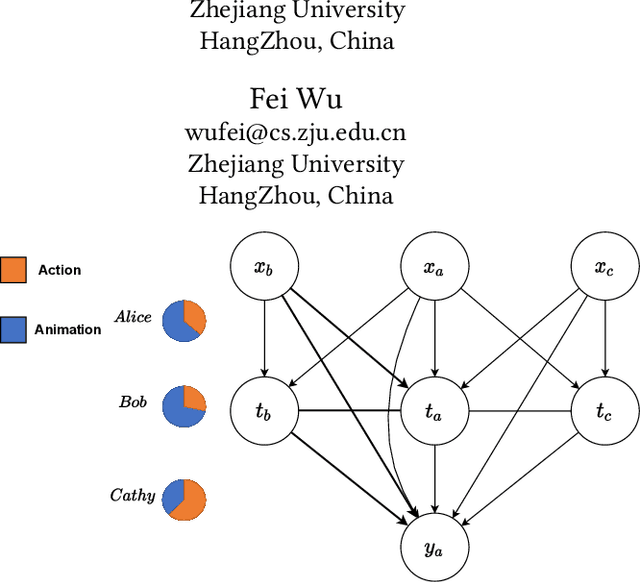
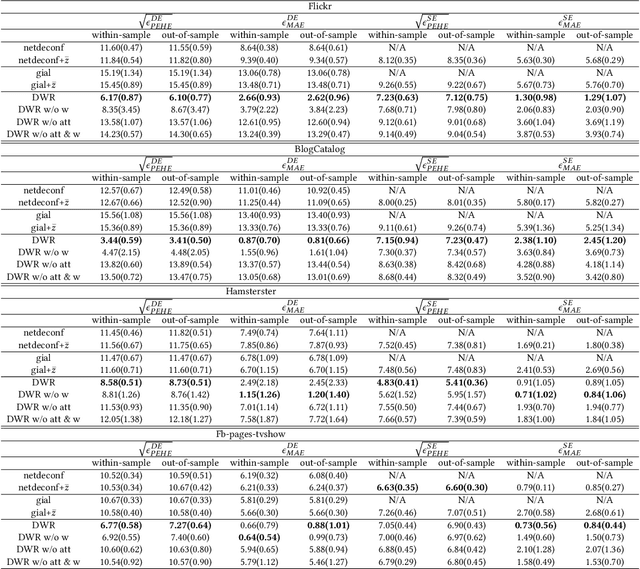
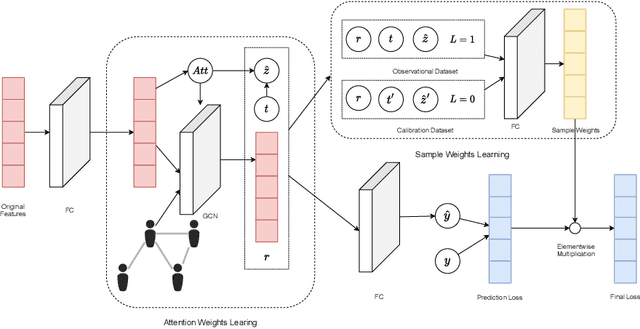
Estimates of individual treatment effects from networked observational data are attracting increasing attention these days. One major challenge in network scenarios is the violation of the stable unit treatment value assumption (SUTVA), which assumes that the treatment assignment of a unit does not influence others' outcomes. In network data, due to interference, the outcome of a unit is influenced not only by its treatment (i.e., direct effects) but also by others' treatments (i.e., spillover effects). Furthermore, the influences from other units are always heterogeneous (e.g., friends with similar interests affect a person differently than friends with different interests). In this paper, we focus on the problem of estimating individual treatment effects (both direct and spillover effects) under heterogeneous interference. To address this issue, we propose a novel Dual Weighting Regression (DWR) algorithm by simultaneously learning attention weights that capture the heterogeneous interference and sample weights to eliminate the complex confounding bias in networks. We formulate the entire learning process as a bi-level optimization problem. In theory, we present generalization error bounds for individual treatment effect estimation. Extensive experiments on four benchmark datasets demonstrate that the proposed DWR algorithm outperforms state-of-the-art methods for estimating individual treatment effects under heterogeneous interference.
Investigating the Robustness of Natural Language Generation from Logical Forms via Counterfactual Samples
Oct 16, 2022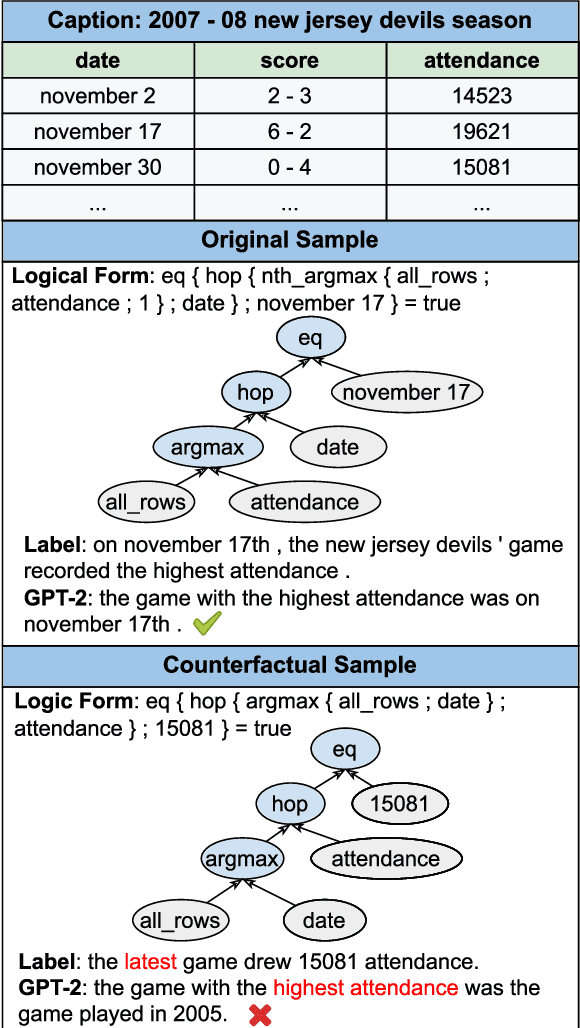
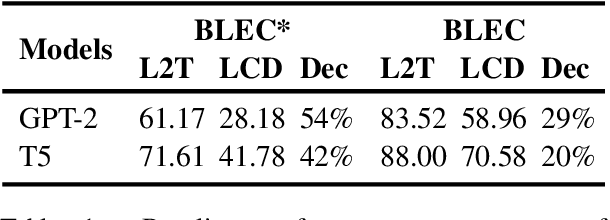
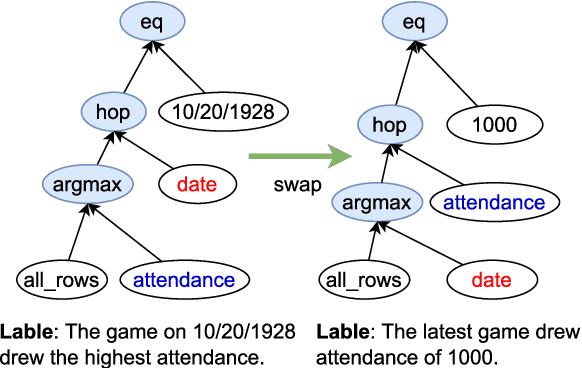
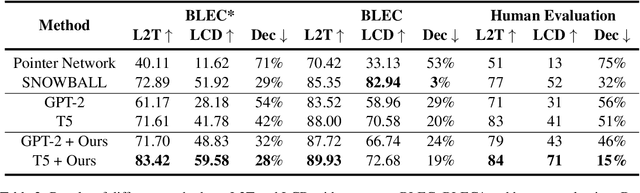
The aim of Logic2Text is to generate controllable and faithful texts conditioned on tables and logical forms, which not only requires a deep understanding of the tables and logical forms, but also warrants symbolic reasoning over the tables. State-of-the-art methods based on pre-trained models have achieved remarkable performance on the standard test dataset. However, we question whether these methods really learn how to perform logical reasoning, rather than just relying on the spurious correlations between the headers of the tables and operators of the logical form. To verify this hypothesis, we manually construct a set of counterfactual samples, which modify the original logical forms to generate counterfactual logical forms with rarely co-occurred table headers and logical operators. SOTA methods give much worse results on these counterfactual samples compared with the results on the original test dataset, which verifies our hypothesis. To deal with this problem, we firstly analyze this bias from a causal perspective, based on which we propose two approaches to reduce the model's reliance on the shortcut. The first one incorporates the hierarchical structure of the logical forms into the model. The second one exploits automatically generated counterfactual data for training. Automatic and manual experimental results on the original test dataset and the counterfactual dataset show that our method is effective to alleviate the spurious correlation. Our work points out the weakness of previous methods and takes a further step toward developing Logic2Text models with real logical reasoning ability.
MetaNetwork: A Task-agnostic Network Parameters Generation Framework for Improving Device Model Generalization
Sep 12, 2022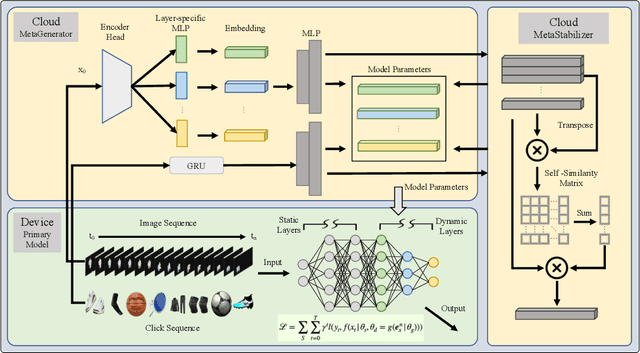
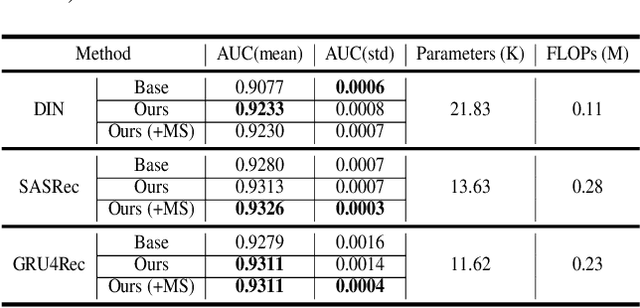
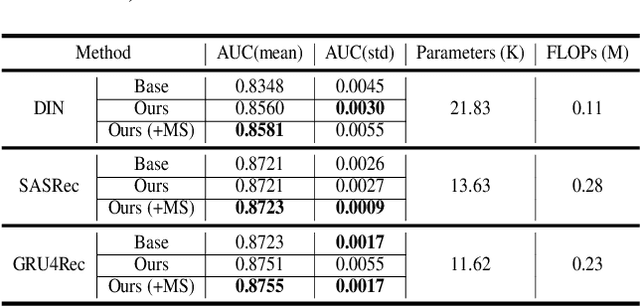

Deploying machine learning models on mobile devices has gained increasing attention. To tackle the model generalization problem with the limitations of hardware resources on the device, the device model needs to be lightweight by techniques such as model compression from the cloud model. However, the major obstacle to improve the device model generalization is the distribution shift between the data of cloud and device models, since the data distribution on device model often changes over time (e.g., users might have different preferences in recommendation system). Although real-time fine-tuning and distillation method take this situation into account, these methods require on-device training, which are practically infeasible due to the low computational power and a lack of real-time labeled samples on the device. In this paper, we propose a novel task-agnostic framework, named MetaNetwork, for generating adaptive device model parameters from cloud without on-device training. Specifically, our MetaNetwork is deployed on cloud and consists of MetaGenerator and MetaStabilizer modules. The MetaGenerator is designed to learn a mapping function from samples to model parameters, and it can generate and deliver the adaptive parameters to the device based on samples uploaded from the device to the cloud. The MetaStabilizer aims to reduce the oscillation of the MetaGenerator, accelerate the convergence and improve the model performance during both training and inference. We evaluate our method on two tasks with three datasets. Extensive experiments show that MetaNetwork can achieve competitive performances in different modalities.
Treatment Effect Estimation with Unmeasured Confounders in Data Fusion
Aug 23, 2022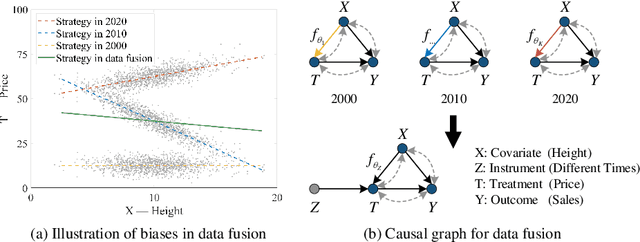
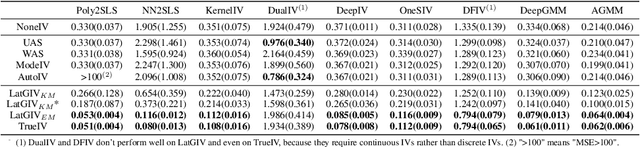
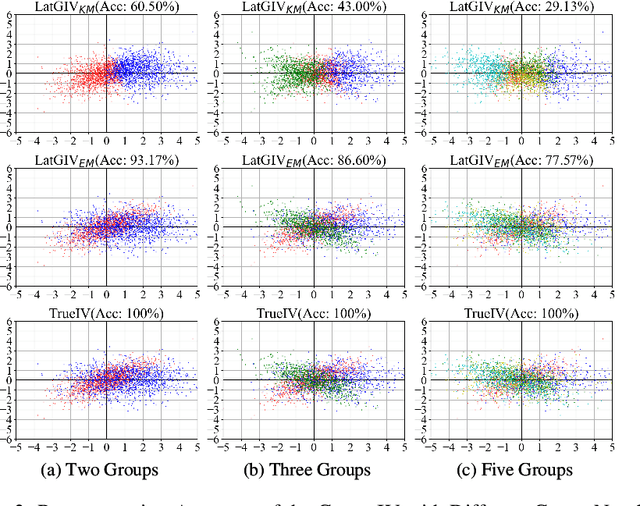
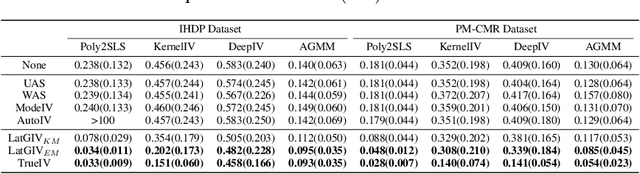
In the presence of unmeasured confounders, we address the problem of treatment effect estimation from data fusion, that is, multiple datasets collected under different treatment assignment mechanisms. For example, marketers may assign different advertising strategies to the same products at different times/places. To handle the bias induced by unmeasured confounders and data fusion, we propose to separate the observational data into multiple groups (each group with an independent treatment assignment mechanism), and then explicitly model the group indicator as a Latent Group Instrumental Variable (LatGIV) to implement IV-based Regression. In this paper, we conceptualize this line of thought and develop a unified framework to (1) estimate the distribution differences of observed variables across groups; (2) model the LatGIVs from the different treatment assignment mechanisms; and (3) plug LatGIVs to estimate the treatment-response function. Empirical results demonstrate the advantages of the LatGIV compared with state-of-the-art methods.
Personalizing Intervened Network for Long-tailed Sequential User Behavior Modeling
Aug 19, 2022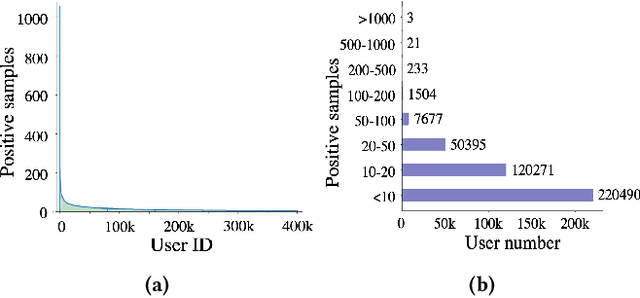


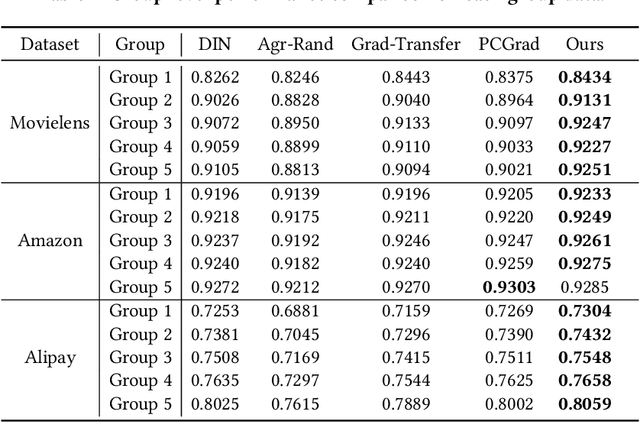
In an era of information explosion, recommendation systems play an important role in people's daily life by facilitating content exploration. It is known that user activeness, i.e., number of behaviors, tends to follow a long-tail distribution, where the majority of users are with low activeness. In practice, we observe that tail users suffer from significantly lower-quality recommendation than the head users after joint training. We further identify that a model trained on tail users separately still achieve inferior results due to limited data. Though long-tail distributions are ubiquitous in recommendation systems, improving the recommendation performance on the tail users still remains challenge in both research and industry. Directly applying related methods on long-tail distribution might be at risk of hurting the experience of head users, which is less affordable since a small portion of head users with high activeness contribute a considerate portion of platform revenue. In this paper, we propose a novel approach that significantly improves the recommendation performance of the tail users while achieving at least comparable performance for the head users over the base model. The essence of this approach is a novel Gradient Aggregation technique that learns common knowledge shared by all users into a backbone model, followed by separate plugin prediction networks for the head users and the tail users personalization. As for common knowledge learning, we leverage the backward adjustment from the causality theory for deconfounding the gradient estimation and thus shielding off the backbone training from the confounder, i.e., user activeness. We conduct extensive experiments on two public recommendation benchmark datasets and a large-scale industrial datasets collected from the Alipay platform. Empirical studies validate the rationality and effectiveness of our approach.
CCL4Rec: Contrast over Contrastive Learning for Micro-video Recommendation
Aug 17, 2022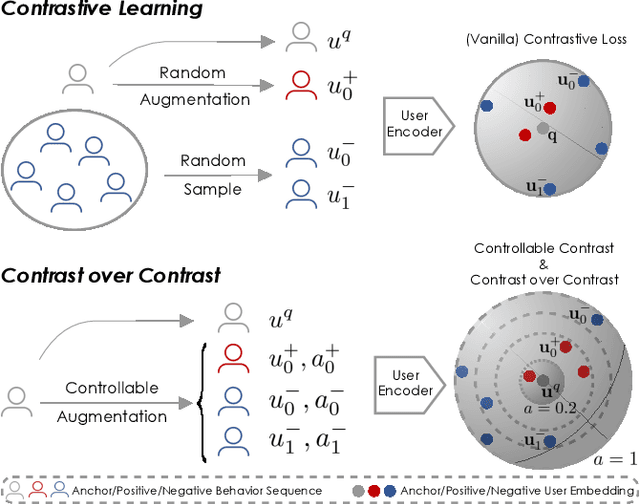

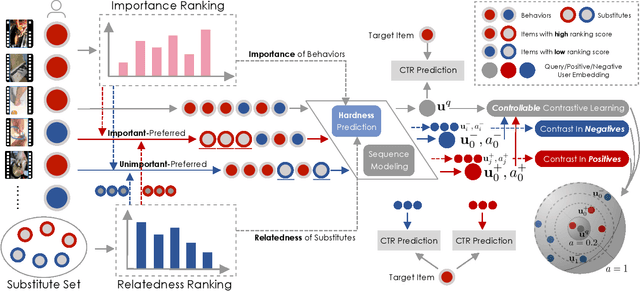
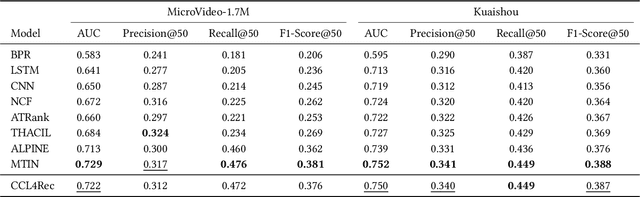
Micro-video recommender systems suffer from the ubiquitous noises in users' behaviors, which might render the learned user representation indiscriminating, and lead to trivial recommendations (e.g., popular items) or even weird ones that are far beyond users' interests. Contrastive learning is an emergent technique for learning discriminating representations with random data augmentations. However, due to neglecting the noises in user behaviors and treating all augmented samples equally, the existing contrastive learning framework is insufficient for learning discriminating user representations in recommendation. To bridge this research gap, we propose the Contrast over Contrastive Learning framework for training recommender models, named CCL4Rec, which models the nuances of different augmented views by further contrasting augmented positives/negatives with adaptive pulling/pushing strengths, i.e., the contrast over (vanilla) contrastive learning. To accommodate these contrasts, we devise the hardness-aware augmentations that track the importance of behaviors being replaced in the query user and the relatedness of substitutes, and thus determining the quality of augmented positives/negatives. The hardness-aware augmentation also permits controllable contrastive learning, leading to performance gains and robust training. In this way, CCL4Rec captures the nuances of historical behaviors for a given user, which explicitly shields off the learned user representation from the effects of noisy behaviors. We conduct extensive experiments on two micro-video recommendation benchmarks, which demonstrate that CCL4Rec with far less model parameters could achieve comparable performance to existing state-of-the-art method, and improve the training/inference speed by several orders of magnitude.
Re4: Learning to Re-contrast, Re-attend, Re-construct for Multi-interest Recommendation
Aug 17, 2022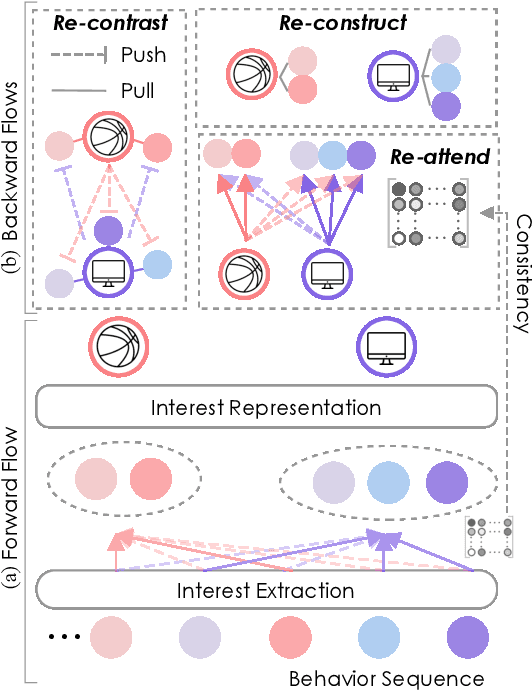
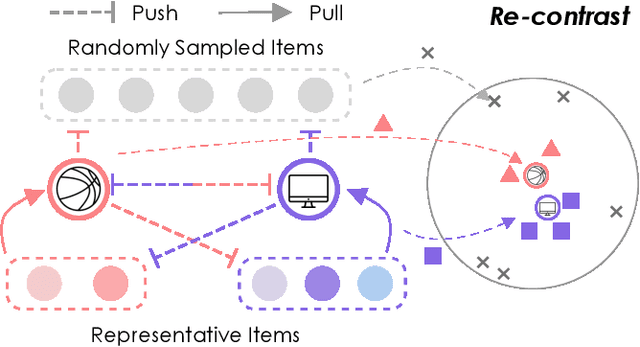
Effectively representing users lie at the core of modern recommender systems. Since users' interests naturally exhibit multiple aspects, it is of increasing interest to develop multi-interest frameworks for recommendation, rather than represent each user with an overall embedding. Despite their effectiveness, existing methods solely exploit the encoder (the forward flow) to represent multiple aspects of interests. However, without explicit regularization, the interest embeddings may not be distinct from each other nor semantically reflect representative historical items. Towards this end, we propose the Re4 framework, which leverages the backward flow to reexamine each interest embedding. Specifically, Re4 encapsulates three backward flows, i.e., 1) Re-contrast, which drives each interest embedding to be distinct from other interests using contrastive learning; 2) Re-attend, which ensures the interest-item correlation estimation in the forward flow to be consistent with the criterion used in final recommendation; and 3) Re-construct, which ensures that each interest embedding can semantically reflect the information of representative items that relate to the corresponding interest. We demonstrate the novel forward-backward multi-interest paradigm on ComiRec, and perform extensive experiments on three real-world datasets. Empirical studies validate that Re4 helps to learn learning distinct and effective multi-interest representations.