 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreResQ-R1: Towards Fine-Grained Rank-and-Score Reinforcement Learning for Visual Quality Assessment via Preference-Response Disentangled Policy Optimization
Nov 07, 2025Visual Quality Assessment (QA) seeks to predict human perceptual judgments of visual fidelity. While recent multimodal large language models (MLLMs) show promise in reasoning about image and video quality, existing approaches mainly rely on supervised fine-tuning or rank-only objectives, resulting in shallow reasoning, poor score calibration, and limited cross-domain generalization. We propose PreResQ-R1, a Preference-Response Disentangled Reinforcement Learning framework that unifies absolute score regression and relative ranking consistency within a single reasoning-driven optimization scheme. Unlike prior QA methods, PreResQ-R1 introduces a dual-branch reward formulation that separately models intra-sample response coherence and inter-sample preference alignment, optimized via Group Relative Policy Optimization (GRPO). This design encourages fine-grained, stable, and interpretable chain-of-thought reasoning about perceptual quality. To extend beyond static imagery, we further design a global-temporal and local-spatial data flow strategy for Video Quality Assessment. Remarkably, with reinforcement fine-tuning on only 6K images and 28K videos, PreResQ-R1 achieves state-of-the-art results across 10 IQA and 5 VQA benchmarks under both SRCC and PLCC metrics, surpassing by margins of 5.30% and textbf2.15% in IQA task, respectively. Beyond quantitative gains, it produces human-aligned reasoning traces that reveal the perceptual cues underlying quality judgments. Code and model are available.
Unveiling Deep Semantic Uncertainty Perception for Language-Anchored Multi-modal Vision-Brain Alignment
Nov 06, 2025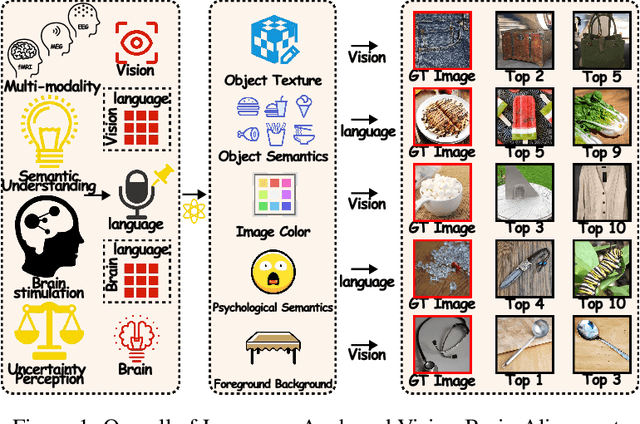
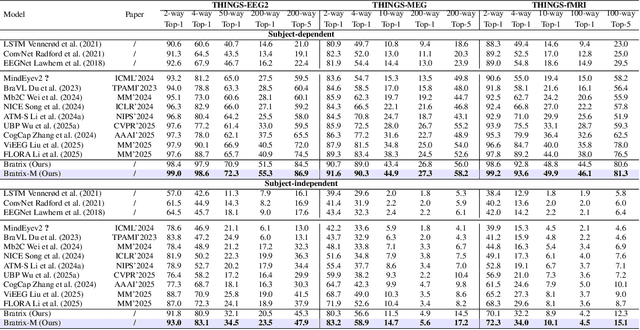
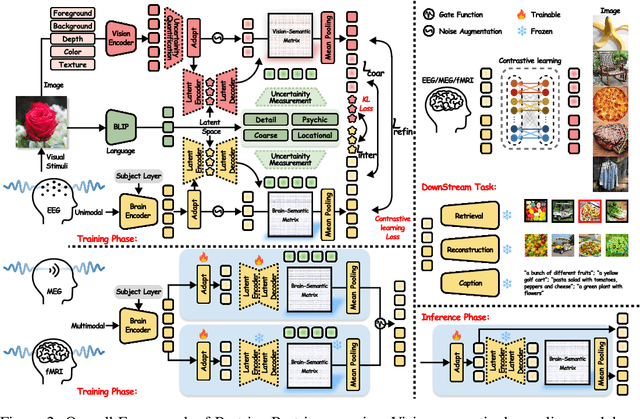
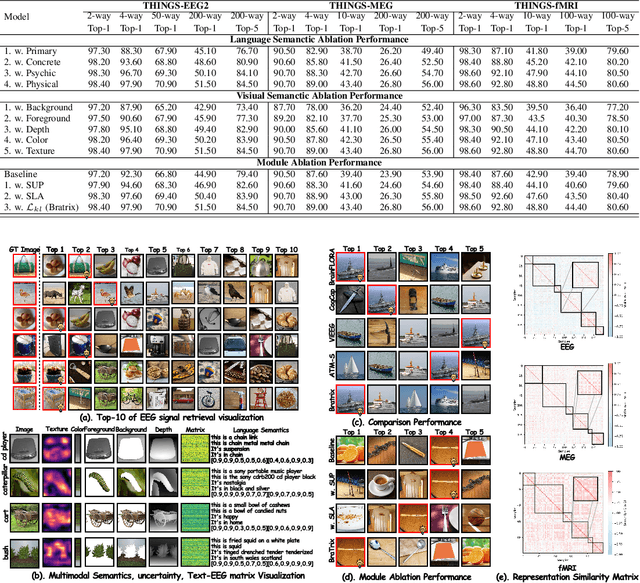
Unveiling visual semantics from neural signals such as EEG, MEG, and fMRI remains a fundamental challenge due to subject variability and the entangled nature of visual features. Existing approaches primarily align neural activity directly with visual embeddings, but visual-only representations often fail to capture latent semantic dimensions, limiting interpretability and deep robustness. To address these limitations, we propose Bratrix, the first end-to-end framework to achieve multimodal Language-Anchored Vision-Brain alignment. Bratrix decouples visual stimuli into hierarchical visual and linguistic semantic components, and projects both visual and brain representations into a shared latent space, enabling the formation of aligned visual-language and brain-language embeddings. To emulate human-like perceptual reliability and handle noisy neural signals, Bratrix incorporates a novel uncertainty perception module that applies uncertainty-aware weighting during alignment. By leveraging learnable language-anchored semantic matrices to enhance cross-modal correlations and employing a two-stage training strategy of single-modality pretraining followed by multimodal fine-tuning, Bratrix-M improves alignment precision. Extensive experiments on EEG, MEG, and fMRI benchmarks demonstrate that Bratrix improves retrieval, reconstruction, and captioning performance compared to state-of-the-art methods, specifically surpassing 14.3% in 200-way EEG retrieval task. Code and model are available.
ProGraph: Temporally-alignable Probability Guided Graph Topological Modeling for 3D Human Reconstruction
Nov 07, 2024



Current 3D human motion reconstruction methods from monocular videos rely on features within the current reconstruction window, leading to distortion and deformations in the human structure under local occlusions or blurriness in video frames. To estimate realistic 3D human mesh sequences based on incomplete features, we propose Temporally-alignable Probability Guided Graph Topological Modeling for 3D Human Reconstruction (ProGraph). For missing parts recovery, we exploit the explicit topological-aware probability distribution across the entire motion sequence. To restore the complete human, Graph Topological Modeling (GTM) learns the underlying topological structure, focusing on the relationships inherent in the individual parts. Next, to generate blurred motion parts, Temporal-alignable Probability Distribution (TPDist) utilizes the GTM to predict features based on distribution. This interactive mechanism facilitates motion consistency, allowing the restoration of human parts. Furthermore, Hierarchical Human Loss (HHLoss) constrains the probability distribution errors of inter-frame features during topological structure variation. Our Method achieves superior results than other SOTA methods in addressing occlusions and blurriness on 3DPW.