 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeaner Training, Lower Leakage: Revisiting Memorization in LLM Fine-Tuning with LoRA
Jun 25, 2025Memorization in large language models (LLMs) makes them vulnerable to data extraction attacks. While pre-training memorization has been extensively studied, fewer works have explored its impact in fine-tuning, particularly for LoRA fine-tuning, a widely adopted parameter-efficient method. In this work, we re-examine memorization in fine-tuning and uncover a surprising divergence from prior findings across different fine-tuning strategies. Factors such as model scale and data duplication, which strongly influence memorization in pre-training and full fine-tuning, do not follow the same trend in LoRA fine-tuning. Using a more relaxed similarity-based memorization metric, we demonstrate that LoRA significantly reduces memorization risks compared to full fine-tuning, while still maintaining strong task performance.
Hear No Evil: Detecting Gradient Leakage by Malicious Servers in Federated Learning
Jun 25, 2025Recent work has shown that gradient updates in federated learning (FL) can unintentionally reveal sensitive information about a client's local data. This risk becomes significantly greater when a malicious server manipulates the global model to provoke information-rich updates from clients. In this paper, we adopt a defender's perspective to provide the first comprehensive analysis of malicious gradient leakage attacks and the model manipulation techniques that enable them. Our investigation reveals a core trade-off: these attacks cannot be both highly effective in reconstructing private data and sufficiently stealthy to evade detection -- especially in realistic FL settings that incorporate common normalization techniques and federated averaging. Building on this insight, we argue that malicious gradient leakage attacks, while theoretically concerning, are inherently limited in practice and often detectable through basic monitoring. As a complementary contribution, we propose a simple, lightweight, and broadly applicable client-side detection mechanism that flags suspicious model updates before local training begins, despite the fact that such detection may not be strictly necessary in realistic FL settings. This mechanism further underscores the feasibility of defending against these attacks with minimal overhead, offering a deployable safeguard for privacy-conscious federated learning systems.
Merlin: Multi-View Representation Learning for Robust Multivariate Time Series Forecasting with Unfixed Missing Rates
Jun 14, 2025



Multivariate Time Series Forecasting (MTSF) involves predicting future values of multiple interrelated time series. Recently, deep learning-based MTSF models have gained significant attention for their promising ability to mine semantics (global and local information) within MTS data. However, these models are pervasively susceptible to missing values caused by malfunctioning data collectors. These missing values not only disrupt the semantics of MTS, but their distribution also changes over time. Nevertheless, existing models lack robustness to such issues, leading to suboptimal forecasting performance. To this end, in this paper, we propose Multi-View Representation Learning (Merlin), which can help existing models achieve semantic alignment between incomplete observations with different missing rates and complete observations in MTS. Specifically, Merlin consists of two key modules: offline knowledge distillation and multi-view contrastive learning. The former utilizes a teacher model to guide a student model in mining semantics from incomplete observations, similar to those obtainable from complete observations. The latter improves the student model's robustness by learning from positive/negative data pairs constructed from incomplete observations with different missing rates, ensuring semantic alignment across different missing rates. Therefore, Merlin is capable of effectively enhancing the robustness of existing models against unfixed missing rates while preserving forecasting accuracy. Experiments on four real-world datasets demonstrate the superiority of Merlin.
UdonCare: Hierarchy Pruning for Unseen Domain Discovery in Predictive Healthcare
Jun 08, 2025Domain generalization has become a critical challenge in clinical prediction, where patient cohorts often exhibit shifting data distributions that degrade model performance. Typical domain generalization approaches struggle in real-world healthcare settings for two main reasons: (1) patient-specific domain labels are typically unavailable, making domain discovery especially difficult; (2) purely data-driven approaches overlook key clinical insights, leading to a gap in medical knowledge integration. To address these problems, we leverage hierarchical medical ontologies like the ICD-9-CM hierarchy to group diseases into higher-level categories and discover more flexible latent domains. In this paper, we introduce UdonCare, a hierarchy-guided framework that iteratively prunes fine-grained domains, encodes these refined domains, and applies a Siamese-type inference mechanism to separate domain-related signals from patient-level features. Experimental results on clinical datasets (MIMIC-III and MIMIC-IV) show that the proposed model achieves higher performance compared to other domain generalization baselines when substantial domain gaps presents, highlighting the untapped potential of medical knowledge for enhancing domain generalization in practical healthcare applications.
KnowCoder-V2: Deep Knowledge Analysis
Jun 07, 2025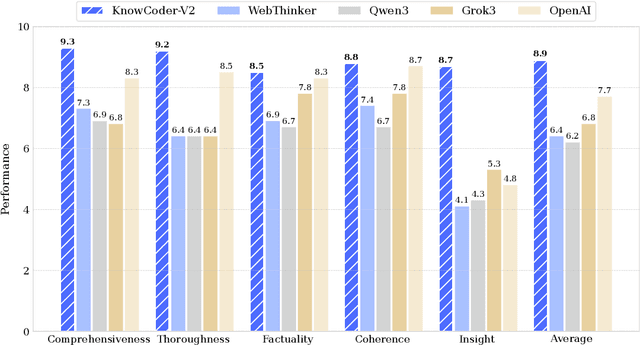
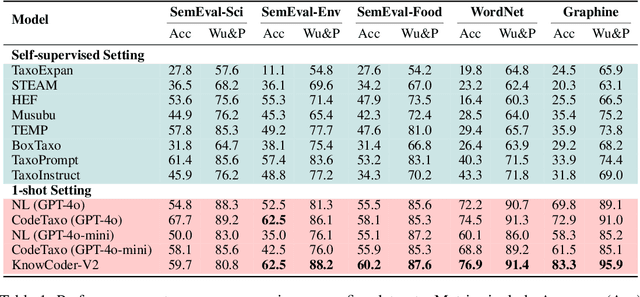
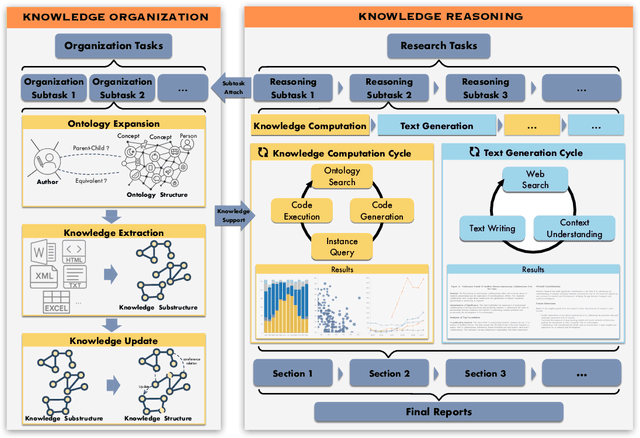
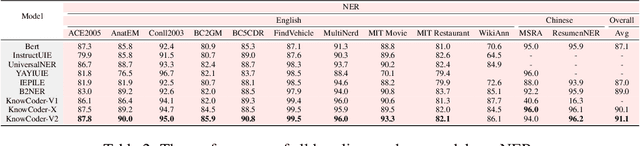
Deep knowledge analysis tasks always involve the systematic extraction and association of knowledge from large volumes of data, followed by logical reasoning to discover insights. However, to solve such complex tasks, existing deep research frameworks face three major challenges: 1) They lack systematic organization and management of knowledge; 2) They operate purely online, making it inefficient for tasks that rely on shared and large-scale knowledge; 3) They cannot perform complex knowledge computation, limiting their abilities to produce insightful analytical results. Motivated by these, in this paper, we propose a \textbf{K}nowledgeable \textbf{D}eep \textbf{R}esearch (\textbf{KDR}) framework that empowers deep research with deep knowledge analysis capability. Specifically, it introduces an independent knowledge organization phase to preprocess large-scale, domain-relevant data into systematic knowledge offline. Based on this knowledge, it extends deep research with an additional kind of reasoning steps that perform complex knowledge computation in an online manner. To enhance the abilities of LLMs to solve knowledge analysis tasks in the above framework, we further introduce \textbf{\KCII}, an LLM that bridges knowledge organization and reasoning via unified code generation. For knowledge organization, it generates instantiation code for predefined classes, transforming data into knowledge objects. For knowledge computation, it generates analysis code and executes on the above knowledge objects to obtain deep analysis results. Experimental results on more than thirty datasets across six knowledge analysis tasks demonstrate the effectiveness of \KCII. Moreover, when integrated into the KDR framework, \KCII can generate high-quality reports with insightful analytical results compared to the mainstream deep research framework.
LayerIF: Estimating Layer Quality for Large Language Models using Influence Functions
May 27, 2025Pretrained Large Language Models (LLMs) achieve strong performance across a wide range of tasks, yet exhibit substantial variability in the various layers' training quality with respect to specific downstream applications, limiting their downstream performance.It is therefore critical to estimate layer-wise training quality in a manner that accounts for both model architecture and training data. However, existing approaches predominantly rely on model-centric heuristics (such as spectral statistics, outlier detection, or uniform allocation) while overlooking the influence of data. To address these limitations, we propose LayerIF, a data-driven framework that leverages Influence Functions to quantify the training quality of individual layers in a principled and task-sensitive manner. By isolating each layer's gradients and measuring the sensitivity of the validation loss to training examples by computing layer-wise influences, we derive data-driven estimates of layer importance. Notably, our method produces task-specific layer importance estimates for the same LLM, revealing how layers specialize for different test-time evaluation tasks. We demonstrate the utility of our scores by leveraging them for two downstream applications: (a) expert allocation in LoRA-MoE architectures and (b) layer-wise sparsity distribution for LLM pruning. Experiments across multiple LLM architectures demonstrate that our model-agnostic, influence-guided allocation leads to consistent gains in task performance.
UltraVSR: Achieving Ultra-Realistic Video Super-Resolution with Efficient One-Step Diffusion Space
May 26, 2025Diffusion models have shown great potential in generating realistic image detail. However, adapting these models to video super-resolution (VSR) remains challenging due to their inherent stochasticity and lack of temporal modeling. In this paper, we propose UltraVSR, a novel framework that enables ultra-realistic and temporal-coherent VSR through an efficient one-step diffusion space. A central component of UltraVSR is the Degradation-aware Restoration Schedule (DRS), which estimates a degradation factor from the low-resolution input and transforms iterative denoising process into a single-step reconstruction from from low-resolution to high-resolution videos. This design eliminates randomness from diffusion noise and significantly speeds up inference. To ensure temporal consistency, we propose a lightweight yet effective Recurrent Temporal Shift (RTS) module, composed of an RTS-convolution unit and an RTS-attention unit. By partially shifting feature components along the temporal dimension, these two units collaboratively facilitate effective feature propagation, fusion, and alignment across neighboring frames, without relying on explicit temporal layers. The RTS module is integrated into a pretrained text-to-image diffusion model and is further enhanced through Spatio-temporal Joint Distillation (SJD), which improves temporal coherence while preserving realistic details. Additionally, we introduce a Temporally Asynchronous Inference (TAI) strategy to capture long-range temporal dependencies under limited memory constraints. Extensive experiments show that UltraVSR achieves state-of-the-art performance, both qualitatively and quantitatively, in a single sampling step.
BLAST: Balanced Sampling Time Series Corpus for Universal Forecasting Models
May 23, 2025



The advent of universal time series forecasting models has revolutionized zero-shot forecasting across diverse domains, yet the critical role of data diversity in training these models remains underexplored. Existing large-scale time series datasets often suffer from inherent biases and imbalanced distributions, leading to suboptimal model performance and generalization. To address this gap, we introduce BLAST, a novel pre-training corpus designed to enhance data diversity through a balanced sampling strategy. First, BLAST incorporates 321 billion observations from publicly available datasets and employs a comprehensive suite of statistical metrics to characterize time series patterns. Then, to facilitate pattern-oriented sampling, the data is implicitly clustered using grid-based partitioning. Furthermore, by integrating grid sampling and grid mixup techniques, BLAST ensures a balanced and representative coverage of diverse patterns. Experimental results demonstrate that models pre-trained on BLAST achieve state-of-the-art performance with a fraction of the computational resources and training tokens required by existing methods. Our findings highlight the pivotal role of data diversity in improving both training efficiency and model performance for the universal forecasting task.
PrePrompt: Predictive prompting for class incremental learning
May 13, 2025Class Incremental Learning (CIL) based on pre-trained models offers a promising direction for open-world continual learning. Existing methods typically rely on correlation-based strategies, where an image's classification feature is used as a query to retrieve the most related key prompts and select the corresponding value prompts for training. However, these approaches face an inherent limitation: fitting the entire feature space of all tasks with only a few trainable prompts is fundamentally challenging. We propose Predictive Prompting (PrePrompt), a novel CIL framework that circumvents correlation-based limitations by leveraging pre-trained models' natural classification ability to predict task-specific prompts. Specifically, PrePrompt decomposes CIL into a two-stage prediction framework: task-specific prompt prediction followed by label prediction. While theoretically appealing, this framework risks bias toward recent classes due to missing historical data for older classifier calibration. PrePrompt then mitigates this by incorporating feature translation, dynamically balancing stability and plasticity. Experiments across multiple benchmarks demonstrate PrePrompt's superiority over state-of-the-art prompt-based CIL methods. The code will be released upon acceptance.
Federated Causal Inference in Healthcare: Methods, Challenges, and Applications
May 04, 2025



Federated causal inference enables multi-site treatment effect estimation without sharing individual-level data, offering a privacy-preserving solution for real-world evidence generation. However, data heterogeneity across sites, manifested in differences in covariate, treatment, and outcome, poses significant challenges for unbiased and efficient estimation. In this paper, we present a comprehensive review and theoretical analysis of federated causal effect estimation across both binary/continuous and time-to-event outcomes. We classify existing methods into weight-based strategies and optimization-based frameworks and further discuss extensions including personalized models, peer-to-peer communication, and model decomposition. For time-to-event outcomes, we examine federated Cox and Aalen-Johansen models, deriving asymptotic bias and variance under heterogeneity. Our analysis reveals that FedProx-style regularization achieves near-optimal bias-variance trade-offs compared to naive averaging and meta-analysis. We review related software tools and conclude by outlining opportunities, challenges, and future directions for scalable, fair, and trustworthy federated causal inference in distributed healthcare systems.