 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrimitive-Planner: An Ultra Lightweight Quadrotor Planner with Time-optimal Primitives
Feb 24, 2025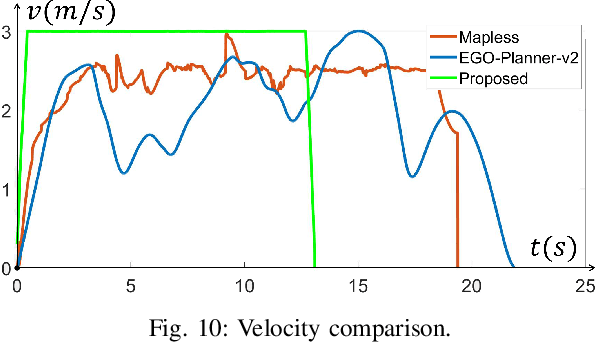
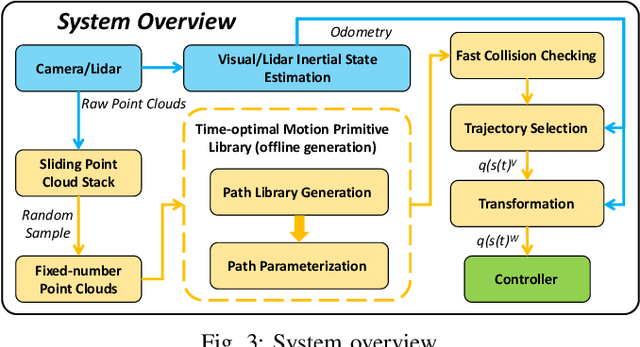
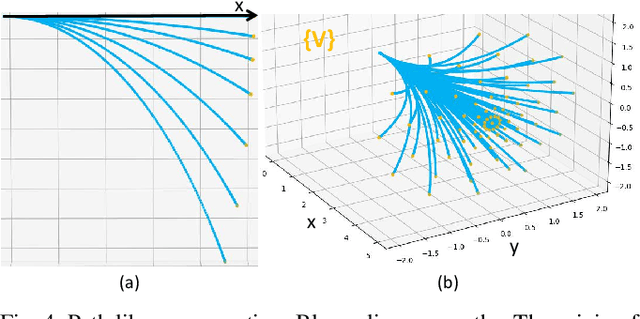
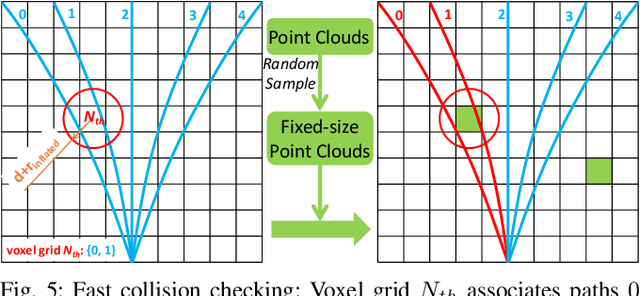
It is a significant requirement for a quadrotor trajectory planner to simultaneously guarantee trajectory quality and system lightweight. Many researchers focus on this problem, but there's still a gap between their performance and our common wish. In this paper, we propose an ultra lightweight quadrotor planner with time-optimal primitives. Firstly, a novel motion primitive library is proposed to generate time-optimal and dynamical feasible trajectories offline. Secondly, we propose a fast collision checking method with a deterministic time consumption, independent of the sampling resolution of the primitives. Finally, we select the minimum cost trajectory to execute among the safe primitives based on user-defined requirements. The propsed transformation relation between the local trajectories ensures the smoothness of the global trajectory. The planner reduces unnecessary online computing power consumption as much as possible, while ensuring a high-quality trajectory. Benchmark comparisons show that our method can generate the shortest flight time and distance of trajectory with the lowest computation overload. Challenging real-world experiments validate the robustness of our method.
Sce2DriveX: A Generalized MLLM Framework for Scene-to-Drive Learning
Feb 19, 2025



End-to-end autonomous driving, which directly maps raw sensor inputs to low-level vehicle controls, is an important part of Embodied AI. Despite successes in applying Multimodal Large Language Models (MLLMs) for high-level traffic scene semantic understanding, it remains challenging to effectively translate these conceptual semantics understandings into low-level motion control commands and achieve generalization and consensus in cross-scene driving. We introduce Sce2DriveX, a human-like driving chain-of-thought (CoT) reasoning MLLM framework. Sce2DriveX utilizes multimodal joint learning from local scene videos and global BEV maps to deeply understand long-range spatiotemporal relationships and road topology, enhancing its comprehensive perception and reasoning capabilities in 3D dynamic/static scenes and achieving driving generalization across scenes. Building on this, it reconstructs the implicit cognitive chain inherent in human driving, covering scene understanding, meta-action reasoning, behavior interpretation analysis, motion planning and control, thereby further bridging the gap between autonomous driving and human thought processes. To elevate model performance, we have developed the first extensive Visual Question Answering (VQA) driving instruction dataset tailored for 3D spatial understanding and long-axis task reasoning. Extensive experiments demonstrate that Sce2DriveX achieves state-of-the-art performance from scene understanding to end-to-end driving, as well as robust generalization on the CARLA Bench2Drive benchmark.
Contact-Aware Motion Planning Among Movable Objects
Feb 05, 2025Most existing methods for motion planning of mobile robots involve generating collision-free trajectories. However, these methods focusing solely on contact avoidance may limit the robots' locomotion and can not be applied to tasks where contact is inevitable or intentional. To address these issues, we propose a novel contact-aware motion planning (CAMP) paradigm for robotic systems. Our approach incorporates contact between robots and movable objects as complementarity constraints in optimization-based trajectory planning. By leveraging augmented Lagrangian methods (ALMs), we efficiently solve the optimization problem with complementarity constraints, producing spatial-temporal optimal trajectories of the robots. Simulations demonstrate that, compared to the state-of-the-art method, our proposed CAMP method expands the reachable space of mobile robots, resulting in a significant improvement in the success rate of two types of fundamental tasks: navigation among movable objects (NAMO) and rearrangement of movable objects (RAMO). Real-world experiments show that the trajectories generated by our proposed method are feasible and quickly deployed in different tasks.
Safe and Agile Transportation of Cable-Suspended Payload via Multiple Aerial Robots
Jan 25, 2025



Transporting a heavy payload using multiple aerial robots (MARs) is an efficient manner to extend the load capacity of a single aerial robot. However, existing schemes for the multiple aerial robots transportation system (MARTS) still lack the capability to generate a collision-free and dynamically feasible trajectory in real-time and further track an agile trajectory especially when there are no sensors available to measure the states of payload and cable. Therefore, they are limited to low-agility transportation in simple environments. To bridge the gap, we propose complete planning and control schemes for the MARTS, achieving safe and agile aerial transportation (SAAT) of a cable-suspended payload in complex environments. Flatness maps for the aerial robot considering the complete kinematical constraint and the dynamical coupling between each aerial robot and payload are derived. To improve the responsiveness for the generation of the safe, dynamically feasible, and agile trajectory in complex environments, a real-time spatio-temporal trajectory planning scheme is proposed for the MARTS. Besides, we break away from the reliance on the state measurement for both the payload and cable, as well as the closed-loop control for the payload, and propose a fully distributed control scheme to track the agile trajectory that is robust against imprecise payload mass and non-point mass payload. The proposed schemes are extensively validated through benchmark comparisons, ablation studies, and simulations. Finally, extensive real-world experiments are conducted on a MARTS integrated by three aerial robots with onboard computers and sensors. The result validates the efficiency and robustness of our proposed schemes for SAAT in complex environments.
Towards Aligned Data Forgetting via Twin Machine Unlearning
Jan 15, 2025Modern privacy regulations have spurred the evolution of machine unlearning, a technique enabling a trained model to efficiently forget specific training data. In prior unlearning methods, the concept of "data forgetting" is often interpreted and implemented as achieving zero classification accuracy on such data. Nevertheless, the authentic aim of machine unlearning is to achieve alignment between the unlearned model and the gold model, i.e., encouraging them to have identical classification accuracy. On the other hand, the gold model often exhibits non-zero classification accuracy due to its generalization ability. To achieve aligned data forgetting, we propose a Twin Machine Unlearning (TMU) approach, where a twin unlearning problem is defined corresponding to the original unlearning problem. Consequently, the generalization-label predictor trained on the twin problem can be transferred to the original problem, facilitating aligned data forgetting. Comprehensive empirical experiments illustrate that our approach significantly enhances the alignment between the unlearned model and the gold model.
Cooperative Aerial Robot Inspection Challenge: A Benchmark for Heterogeneous Multi-UAV Planning and Lessons Learned
Jan 14, 2025



We propose the Cooperative Aerial Robot Inspection Challenge (CARIC), a simulation-based benchmark for motion planning algorithms in heterogeneous multi-UAV systems. CARIC features UAV teams with complementary sensors, realistic constraints, and evaluation metrics prioritizing inspection quality and efficiency. It offers a ready-to-use perception-control software stack and diverse scenarios to support the development and evaluation of task allocation and motion planning algorithms. Competitions using CARIC were held at IEEE CDC 2023 and the IROS 2024 Workshop on Multi-Robot Perception and Navigation, attracting innovative solutions from research teams worldwide. This paper examines the top three teams from CDC 2023, analyzing their exploration, inspection, and task allocation strategies while drawing insights into their performance across scenarios. The results highlight the task's complexity and suggest promising directions for future research in cooperative multi-UAV systems.
Are GNNs Effective for Multimodal Fault Diagnosis in Microservice Systems?
Jan 06, 2025



Fault diagnosis in microservice systems has increasingly embraced multimodal observation data for a holistic and multifaceted view of the system, with Graph Neural Networks (GNNs) commonly employed to model complex service dependencies. However, despite the intuitive appeal, there remains a lack of compelling justification for the adoption of GNNs, as no direct evidence supports their necessity or effectiveness. To critically evaluate the current use of GNNs, we propose DiagMLP, a simple topology-agnostic baseline as a substitute for GNNs in fault diagnosis frameworks. Through experiments on five public datasets, we surprisingly find that DiagMLP performs competitively with and even outperforms GNN-based methods in fault diagnosis tasks, indicating that the current paradigm of using GNNs to model service dependencies has not yet demonstrated a tangible contribution. We further discuss potential reasons for this observation and advocate shifting the focus from solely pursuing novel model designs to developing challenging datasets, standardizing preprocessing protocols, and critically evaluating the utility of advanced deep learning modules.
Enhanced MRI Representation via Cross-series Masking
Dec 10, 2024



Magnetic resonance imaging (MRI) is indispensable for diagnosing and planning treatment in various medical conditions due to its ability to produce multi-series images that reveal different tissue characteristics. However, integrating these diverse series to form a coherent analysis presents significant challenges, such as differing spatial resolutions and contrast patterns meanwhile requiring extensive annotated data, which is scarce in clinical practice. Due to these issues, we introduce a novel Cross-Series Masking (CSM) Strategy for effectively learning MRI representation in a self-supervised manner. Specifically, CSM commences by randomly sampling a subset of regions and series, which are then strategically masked. In the training process, the cross-series representation is learned by utilizing the unmasked data to reconstruct the masked portions. This process not only integrates information across different series but also facilitates the ability to model both intra-series and inter-series correlations and complementarities. With the learned representation, the downstream tasks like segmentation and classification are also enhanced. Taking brain tissue segmentation, breast tumor benign/malignant classification, and prostate cancer diagnosis as examples, our method achieves state-of-the-art performance on both public and in-house datasets.
NebulaFL: Effective Asynchronous Federated Learning for JointCloud Computing
Dec 06, 2024With advancements in AI infrastructure and Trusted Execution Environment (TEE) technology, Federated Learning as a Service (FLaaS) through JointCloud Computing (JCC) is promising to break through the resource constraints caused by heterogeneous edge devices in the traditional Federated Learning (FL) paradigm. Specifically, with the protection from TEE, data owners can achieve efficient model training with high-performance AI services in the cloud. By providing additional FL services, cloud service providers can achieve collaborative learning among data owners. However, FLaaS still faces three challenges, i.e., i) low training performance caused by heterogeneous data among data owners, ii) high communication overhead among different clouds (i.e., data centers), and iii) lack of efficient resource scheduling strategies to balance training time and cost. To address these challenges, this paper presents a novel asynchronous FL approach named NebulaFL for collaborative model training among multiple clouds. To address data heterogeneity issues, NebulaFL adopts a version control-based asynchronous FL training scheme in each data center to balance training time among data owners. To reduce communication overhead, NebulaFL adopts a decentralized model rotation mechanism to achieve effective knowledge sharing among data centers. To balance training time and cost, NebulaFL integrates a reward-guided strategy for data owners selection and resource scheduling. The experimental results demonstrate that, compared to the state-of-the-art FL methods, NebulaFL can achieve up to 5.71\% accuracy improvement. In addition, NebulaFL can reduce up to 50% communication overhead and 61.94% costs under a target accuracy.
AI-Generated Image Quality Assessment Based on Task-Specific Prompt and Multi-Granularity Similarity
Nov 25, 2024



Recently, AI-generated images (AIGIs) created by given prompts (initial prompts) have garnered widespread attention. Nevertheless, due to technical nonproficiency, they often suffer from poor perception quality and Text-to-Image misalignment. Therefore, assessing the perception quality and alignment quality of AIGIs is crucial to improving the generative model's performance. Existing assessment methods overly rely on the initial prompts in the task prompt design and use the same prompts to guide both perceptual and alignment quality evaluation, overlooking the distinctions between the two tasks. To address this limitation, we propose a novel quality assessment method for AIGIs named TSP-MGS, which designs task-specific prompts and measures multi-granularity similarity between AIGIs and the prompts. Specifically, task-specific prompts are first constructed to describe perception and alignment quality degrees separately, and the initial prompt is introduced for detailed quality perception. Then, the coarse-grained similarity between AIGIs and task-specific prompts is calculated, which facilitates holistic quality awareness. In addition, to improve the understanding of AIGI details, the fine-grained similarity between the image and the initial prompt is measured. Finally, precise quality prediction is acquired by integrating the multi-granularity similarities. Experiments on the commonly used AGIQA-1K and AGIQA-3K benchmarks demonstrate the superiority of the proposed TSP-MGS.