 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAGS: Color-Adaptive Volumetric Video Streaming with Dynamic 3D Gaussian Splatting
May 10, 2026Volumetric video (VV) streaming enables real-time, immersive access to remote 3D environments, powering telepresence, ecological monitoring, and robotic teleoperation. These applications turn VV streaming into a real-time interface to remote physical environments, imposing new system-level demands for photorealistic scene representation, low-latency interaction, and robust performance under heterogeneous networks. 3D Gaussian Splatting (3DGS) has been widely used for real-time photorealistic rendering, offering superior visual quality and rendering performance, but it faces challenges due to bandwidth consumption. Furthermore, as the foundation of adaptive VV streaming, existing Levels of Detail (LoD) methods based on density are not well-suited to Gaussian representations, leading to visible gaps and severe quality degradation. Recent studies have also explored attribute compression techniques to reduce bandwidth consumption. Our preliminary studies reveal that aggressive attribute compression primarily causes color distortion, which can be effectively corrected in the rendered image using a reference image. Motivated by these findings, we propose a novel Color-Adaptive scheme for adaptive VV streaming that uses vector quantization (VQ) to establish LoDs and correct color distortions with low-resolution reference images. We further present CAGS, an adaptive VV streaming system compatible with diverse Gaussian representations, which integrates the Color-Adaptive scheme by rendering reference images on the streaming server and performing color restoration on the client. Extensive experiments on our prototype system demonstrate that CAGS outperforms the existing adaptive streaming systems in PSNR by 5$\sim$20 dB under fluctuating bandwidth, operates significantly faster than existing scalable Gaussian compression methods, and generalizes across different Gaussian representations.
* SIGGRAPH 2026 Conference Paper. Code is available at https://github.com/yindaheng98/ColorAdaptiveGaussianSplatting
The Curse and Blessing of Mean Bias in FP4-Quantized LLM Training
Mar 11, 2026Large language models trained on natural language exhibit pronounced anisotropy: a small number of directions concentrate disproportionate energy, while the remaining dimensions form a broad semantic tail. In low-bit training regimes, this geometry becomes numerically unstable. Because blockwise quantization scales are determined by extreme elementwise magnitudes, dominant directions stretch the dynamic range, compressing long-tail semantic variation into narrow numerical bins. We show that this instability is primarily driven by a coherent rank-one mean bias, which constitutes the dominant component of spectral anisotropy in LLM representations. This mean component emerges systematically across layers and training stages and accounts for the majority of extreme activation magnitudes, making it the principal driver of dynamic-range inflation under low precision. Crucially, because the dominant instability is rank-one, it can be eliminated through a simple source-level mean-subtraction operation. This bias-centric conditioning recovers most of the stability benefits of SVD-based spectral methods while requiring only reduction operations and standard quantization kernels. Empirical results on FP4 (W4A4G4) training show that mean removal substantially narrows the loss gap to BF16 and restores downstream performance, providing a hardware-efficient path to stable low-bit LLM training.
Multi-Head Attention as a Source of Catastrophic Forgetting in MoE Transformers
Feb 13, 2026Mixture-of-Experts (MoE) architectures are often considered a natural fit for continual learning because sparse routing should localize updates and reduce interference, yet MoE Transformers still forget substantially even with sparse, well-balanced expert utilization. We attribute this gap to a pre-routing bottleneck: multi-head attention concatenates head-specific signals into a single post-attention router input, forcing routing to act on co-occurring feature compositions rather than separable head channels. We show that this router input simultaneously encodes multiple separately decodable semantic and structural factors with uneven head support, and that different feature compositions induce weakly aligned parameter-gradient directions; as a result, routing maps many distinct compositions to the same route. We quantify this collision effect via a route-wise effective composition number $N_{eff}$ and find that higher $N_{eff}$ is associated with larger old-task loss increases after continual training. Motivated by these findings, we propose MH-MoE, which performs head-wise routing over sub-representations to increase routing granularity and reduce composition collisions. On TRACE with Qwen3-0.6B/8B, MH-MoE effectively mitigates forgetting, reducing BWT on Qwen3-0.6B from 11.2% (LoRAMoE) to 4.5%.
SD-MoE: Spectral Decomposition for Effective Expert Specialization
Feb 13, 2026Mixture-of-Experts (MoE) architectures scale Large Language Models via expert specialization induced by conditional computation. In practice, however, expert specialization often fails: some experts become functionally similar, while others functioning as de facto shared experts, limiting the effective capacity and model performance. In this work, we analysis from a spectral perspective on parameter and gradient spaces, uncover that (1) experts share highly overlapping dominant spectral components in their parameters, (2) dominant gradient subspaces are strongly aligned across experts, driven by ubiquitous low-rank structure in human corpus, and (3) gating mechanisms preferentially route inputs along these dominant directions, further limiting specialization. To address this, we propose Spectral-Decoupled MoE (SD-MoE), which decomposes both parameter and gradient in the spectral space. SD-MoE improves performance across downstream tasks, enables effective expert specialization, incurring minimal additional computation, and can be seamlessly integrated into a wide range of existing MoE architectures, including Qwen and DeepSeek.
Dispelling the Curse of Singularities in Neural Network Optimizations
Feb 01, 2026This work investigates the optimization instability of deep neural networks from a less-explored yet insightful perspective: the emergence and amplification of singularities in the parametric space. Our analysis reveals that parametric singularities inevitably grow with gradient updates and further intensify alignment with representations, leading to increased singularities in the representation space. We show that the gradient Frobenius norms are bounded by the top singular values of the weight matrices, and as training progresses, the mutually reinforcing growth of weight and representation singularities, termed the curse of singularities, relaxes these bounds, escalating the risk of sharp loss explosions. To counter this, we propose Parametric Singularity Smoothing (PSS), a lightweight, flexible, and effective method for smoothing the singular spectra of weight matrices. Extensive experiments across diverse datasets, architectures, and optimizers demonstrate that PSS mitigates instability, restores trainability even after failure, and improves both training efficiency and generalization.
Otter: Mitigating Background Distractions of Wide-Angle Few-Shot Action Recognition with Enhanced RWKV
Nov 11, 2025Wide-angle videos in few-shot action recognition (FSAR) effectively express actions within specific scenarios. However, without a global understanding of both subjects and background, recognizing actions in such samples remains challenging because of the background distractions. Receptance Weighted Key Value (RWKV), which learns interaction between various dimensions, shows promise for global modeling. While directly applying RWKV to wide-angle FSAR may fail to highlight subjects due to excessive background information. Additionally, temporal relation degraded by frames with similar backgrounds is difficult to reconstruct, further impacting performance. Therefore, we design the CompOund SegmenTation and Temporal REconstructing RWKV (Otter). Specifically, the Compound Segmentation Module~(CSM) is devised to segment and emphasize key patches in each frame, effectively highlighting subjects against background information. The Temporal Reconstruction Module (TRM) is incorporated into the temporal-enhanced prototype construction to enable bidirectional scanning, allowing better reconstruct temporal relation. Furthermore, a regular prototype is combined with the temporal-enhanced prototype to simultaneously enhance subject emphasis and temporal modeling, improving wide-angle FSAR performance. Extensive experiments on benchmarks such as SSv2, Kinetics, UCF101, and HMDB51 demonstrate that Otter achieves state-of-the-art performance. Extra evaluation on the VideoBadminton dataset further validates the superiority of Otter in wide-angle FSAR.
Manta: Enhancing Mamba for Few-Shot Action Recognition of Long Sub-Sequence
Dec 10, 2024



In few-shot action recognition~(FSAR), long sub-sequences of video naturally express entire actions more effectively. However, the computational complexity of mainstream Transformer-based methods limits their application. Recent Mamba demonstrates efficiency in modeling long sequences, but directly applying Mamba to FSAR overlooks the importance of local feature modeling and alignment. Moreover, long sub-sequences within the same class accumulate intra-class variance, which adversely impacts FSAR performance. To solve these challenges, we propose a \underline{\textbf{M}}atryoshka M\underline{\textbf{A}}mba and Co\underline{\textbf{N}}tras\underline{\textbf{T}}ive Le\underline{\textbf{A}}rning framework~(\textbf{Manta}). Firstly, the Matryoshka Mamba introduces multiple Inner Modules to enhance local feature representation, rather than directly modeling global features. An Outer Module captures dependencies of timeline between these local features for implicit temporal alignment. Secondly, a hybrid contrastive learning paradigm, combining both supervised and unsupervised methods, is designed to mitigate the negative effects of intra-class variance accumulation. The Matryoshka Mamba and the hybrid contrastive learning paradigm operate in parallel branches within Manta, enhancing Mamba for FSAR of long sub-sequence. Manta achieves new state-of-the-art performance on prominent benchmarks, including SSv2, Kinetics, UCF101, and HMDB51. Extensive empirical studies prove that Manta significantly improves FSAR of long sub-sequence from multiple perspectives. The code is released at https://github.com/wenbohuang1002/Manta.
Label Information Enhanced Fraud Detection against Low Homophily in Graphs
Feb 21, 2023



Node classification is a substantial problem in graph-based fraud detection. Many existing works adopt Graph Neural Networks (GNNs) to enhance fraud detectors. While promising, currently most GNN-based fraud detectors fail to generalize to the low homophily setting. Besides, label utilization has been proved to be significant factor for node classification problem. But we find they are less effective in fraud detection tasks due to the low homophily in graphs. In this work, we propose GAGA, a novel Group AGgregation enhanced TrAnsformer, to tackle the above challenges. Specifically, the group aggregation provides a portable method to cope with the low homophily issue. Such an aggregation explicitly integrates the label information to generate distinguishable neighborhood information. Along with group aggregation, an attempt towards end-to-end trainable group encoding is proposed which augments the original feature space with the class labels. Meanwhile, we devise two additional learnable encodings to recognize the structural and relational context. Then, we combine the group aggregation and the learnable encodings into a Transformer encoder to capture the semantic information. Experimental results clearly show that GAGA outperforms other competitive graph-based fraud detectors by up to 24.39% on two trending public datasets and a real-world industrial dataset from Anonymous. Even more, the group aggregation is demonstrated to outperform other label utilization methods (e.g., C&S, BoT/UniMP) in the low homophily setting.
Contextual-Bandit Based Personalized Recommendation with Time-Varying User Interests
Feb 29, 2020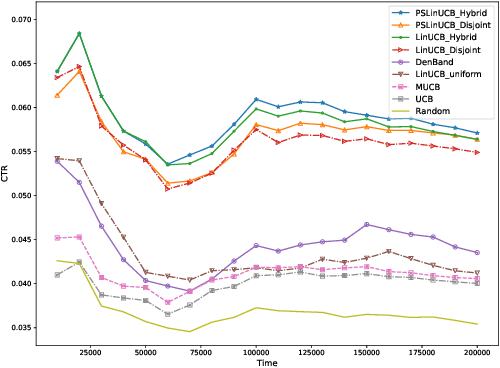
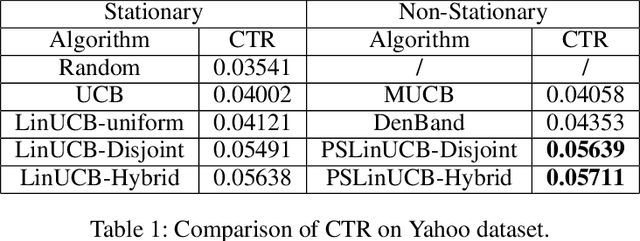
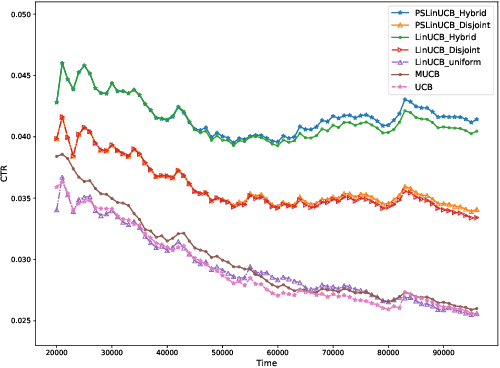
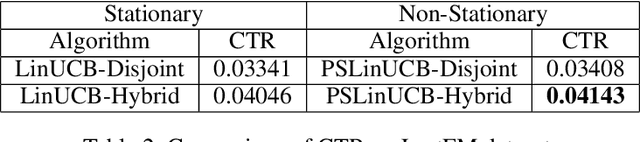
A contextual bandit problem is studied in a highly non-stationary environment, which is ubiquitous in various recommender systems due to the time-varying interests of users. Two models with disjoint and hybrid payoffs are considered to characterize the phenomenon that users' preferences towards different items vary differently over time. In the disjoint payoff model, the reward of playing an arm is determined by an arm-specific preference vector, which is piecewise-stationary with asynchronous and distinct changes across different arms. An efficient learning algorithm that is adaptive to abrupt reward changes is proposed and theoretical regret analysis is provided to show that a sublinear scaling of regret in the time length $T$ is achieved. The algorithm is further extended to a more general setting with hybrid payoffs where the reward of playing an arm is determined by both an arm-specific preference vector and a joint coefficient vector shared by all arms. Empirical experiments are conducted on real-world datasets to verify the advantages of the proposed learning algorithms against baseline ones in both settings.