 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosmos 3: Omnimodal World Models for Physical AI
Jun 01, 2026We introduce Cosmos 3, a family of omnimodal world models designed to jointly process and generate language, image, video, audio, and action sequences within a unified mixture-of-transformers architecture. By supporting highly flexible input-output configurations, Cosmos 3 seamlessly unifies critical modalities for Physical AI -- effectively subsuming vision-language models, video generators, world simulators, and world-action models into a single framework. Our evaluation demonstrates that Cosmos 3 establishes a new state-of-the-art across a diverse suite of understanding and generation tasks, demonstrating omnimodal world models as scalable, general-purpose backbones for embodied agents. Our post-trained Cosmos 3 models were ranked as the best open-source Text-to-Image and Image-to-Video models by Artificial Analysis, and the best policy model by RoboArena at the time the technical report was written. To accelerate open research and deployment in Physical AI, we make our code, model checkpoints, curated synthetic datasets, and evaluation benchmark available under the Linux Foundation's OpenMDW-1.1 https://openmdw.ai/license/1-1/ License at https://github.com/nvidia/cosmos}{github.com/nvidia/cosmos and https://huggingface.co/collections/nvidia/cosmos3 . The project website is available at https://research.nvidia.com/labs/cosmos-lab/cosmos3 .
Towards Generalizable Robotic Manipulation in Dynamic Environments
Mar 16, 2026Vision-Language-Action (VLA) models excel in static manipulation but struggle in dynamic environments with moving targets. This performance gap primarily stems from a scarcity of dynamic manipulation datasets and the reliance of mainstream VLAs on single-frame observations, restricting their spatiotemporal reasoning capabilities. To address this, we introduce DOMINO, a large-scale dataset and benchmark for generalizable dynamic manipulation, featuring 35 tasks with hierarchical complexities, over 110K expert trajectories, and a multi-dimensional evaluation suite. Through comprehensive experiments, we systematically evaluate existing VLAs on dynamic tasks, explore effective training strategies for dynamic awareness, and validate the generalizability of dynamic data. Furthermore, we propose PUMA, a dynamics-aware VLA architecture. By integrating scene-centric historical optical flow and specialized world queries to implicitly forecast object-centric future states, PUMA couples history-aware perception with short-horizon prediction. Results demonstrate that PUMA achieves state-of-the-art performance, yielding a 6.3% absolute improvement in success rate over baselines. Moreover, we show that training on dynamic data fosters robust spatiotemporal representations that transfer to static tasks. All code and data are available at https://github.com/H-EmbodVis/DOMINO.
3D-Generalist: Self-Improving Vision-Language-Action Models for Crafting 3D Worlds
Jul 09, 2025Despite large-scale pretraining endowing models with language and vision reasoning capabilities, improving their spatial reasoning capability remains challenging due to the lack of data grounded in the 3D world. While it is possible for humans to manually create immersive and interactive worlds through 3D graphics, as seen in applications such as VR, gaming, and robotics, this process remains highly labor-intensive. In this paper, we propose a scalable method for generating high-quality 3D environments that can serve as training data for foundation models. We recast 3D environment building as a sequential decision-making problem, employing Vision-Language-Models (VLMs) as policies that output actions to jointly craft a 3D environment's layout, materials, lighting, and assets. Our proposed framework, 3D-Generalist, trains VLMs to generate more prompt-aligned 3D environments via self-improvement fine-tuning. We demonstrate the effectiveness of 3D-Generalist and the proposed training strategy in generating simulation-ready 3D environments. Furthermore, we demonstrate its quality and scalability in synthetic data generation by pretraining a vision foundation model on the generated data. After fine-tuning the pre-trained model on downstream tasks, we show that it surpasses models pre-trained on meticulously human-crafted synthetic data and approaches results achieved with real data orders of magnitude larger.
The 7th AI City Challenge
Apr 15, 2023



The AI City Challenge's seventh edition emphasizes two domains at the intersection of computer vision and artificial intelligence - retail business and Intelligent Traffic Systems (ITS) - that have considerable untapped potential. The 2023 challenge had five tracks, which drew a record-breaking number of participation requests from 508 teams across 46 countries. Track 1 was a brand new track that focused on multi-target multi-camera (MTMC) people tracking, where teams trained and evaluated using both real and highly realistic synthetic data. Track 2 centered around natural-language-based vehicle track retrieval. Track 3 required teams to classify driver actions in naturalistic driving analysis. Track 4 aimed to develop an automated checkout system for retail stores using a single view camera. Track 5, another new addition, tasked teams with detecting violations of the helmet rule for motorcyclists. Two leader boards were released for submissions based on different methods: a public leader board for the contest where external private data wasn't allowed and a general leader board for all results submitted. The participating teams' top performances established strong baselines and even outperformed the state-of-the-art in the proposed challenge tracks.
The 6th AI City Challenge
Apr 21, 2022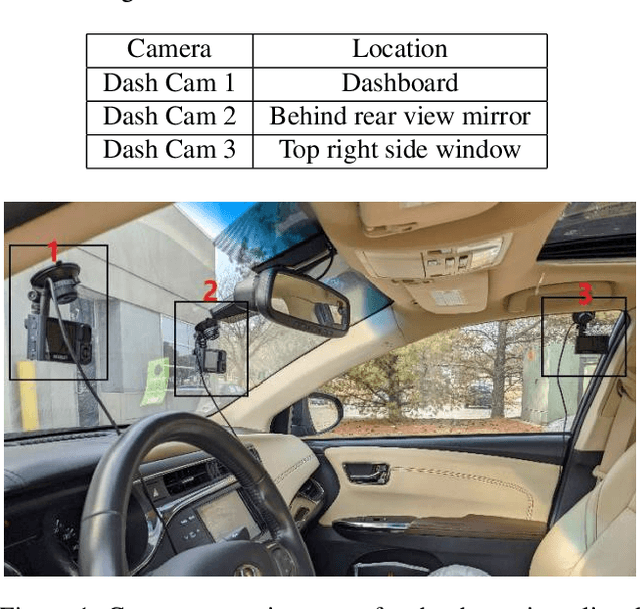
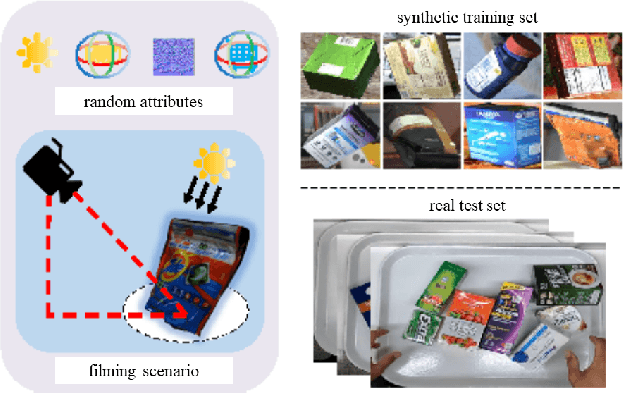
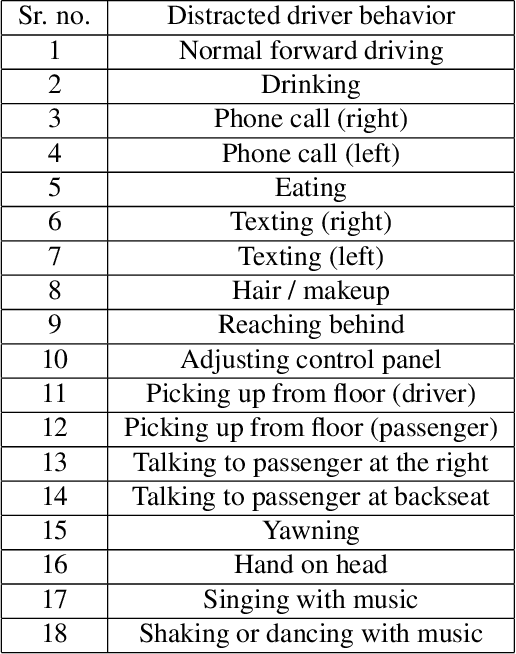
The 6th edition of the AI City Challenge specifically focuses on problems in two domains where there is tremendous unlocked potential at the intersection of computer vision and artificial intelligence: Intelligent Traffic Systems (ITS), and brick and mortar retail businesses. The four challenge tracks of the 2022 AI City Challenge received participation requests from 254 teams across 27 countries. Track 1 addressed city-scale multi-target multi-camera (MTMC) vehicle tracking. Track 2 addressed natural-language-based vehicle track retrieval. Track 3 was a brand new track for naturalistic driving analysis, where the data were captured by several cameras mounted inside the vehicle focusing on driver safety, and the task was to classify driver actions. Track 4 was another new track aiming to achieve retail store automated checkout using only a single view camera. We released two leader boards for submissions based on different methods, including a public leader board for the contest, where no use of external data is allowed, and a general leader board for all submitted results. The top performance of participating teams established strong baselines and even outperformed the state-of-the-art in the proposed challenge tracks.