 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbarrassingly Simple Binary Representation Learning
Aug 26, 2019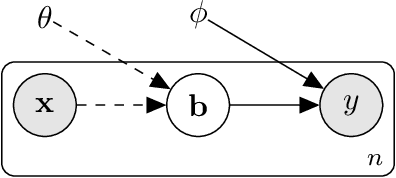

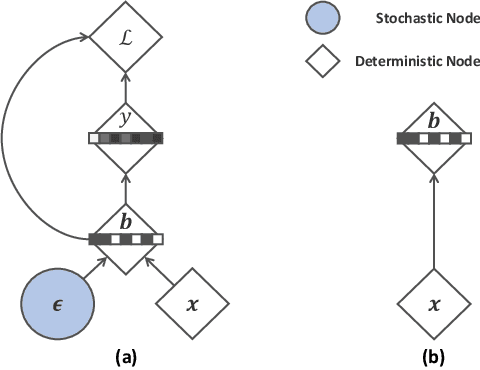
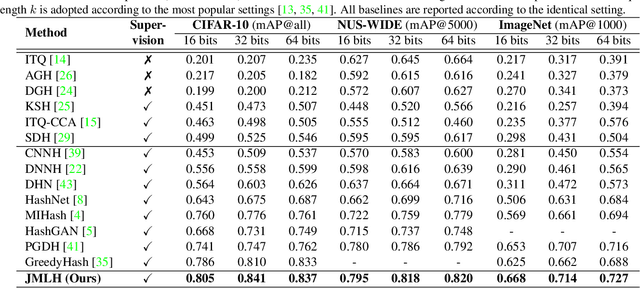
Recent binary representation learning models usually require sophisticated binary optimization, similarity measure or even generative models as auxiliaries. However, one may wonder whether these non-trivial components are needed to formulate practical and effective hashing models. In this paper, we answer the above question by proposing an embarrassingly simple approach to binary representation learning. With a simple classification objective, our model only incorporates two additional fully-connected layers onto the top of an arbitrary backbone network, whilst complying with the binary constraints during training. The proposed model lower-bounds the Information Bottleneck (IB) between data samples and their semantics, and can be related to many recent `learning to hash' paradigms. We show that, when properly designed, even such a simple network can generate effective binary codes, by fully exploring data semantics without any held-out alternating updating steps or auxiliary models. Experiments are conducted on conventional large-scale benchmarks, i.e., CIFAR-10, NUS-WIDE, and ImageNet, where the proposed simple model outperforms the state-of-the-art methods.
NLH: A Blind Pixel-level Non-local Method for Real-world Image Denoising
Aug 04, 2019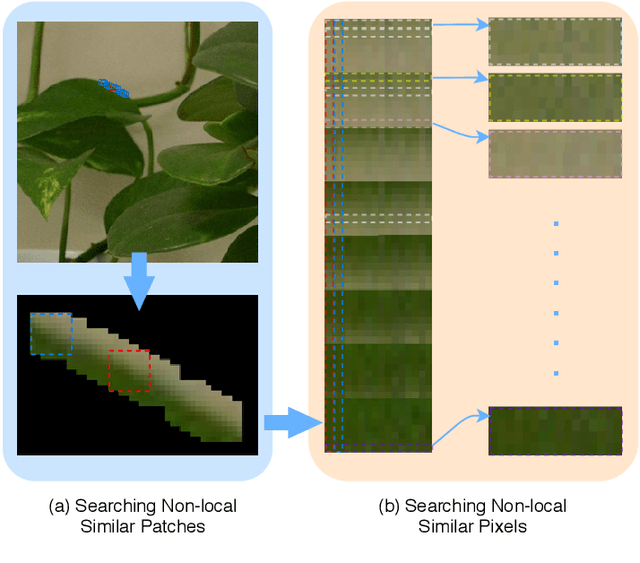
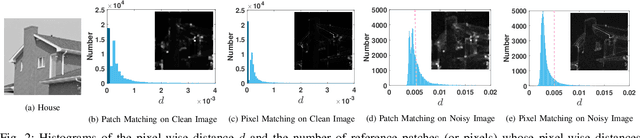
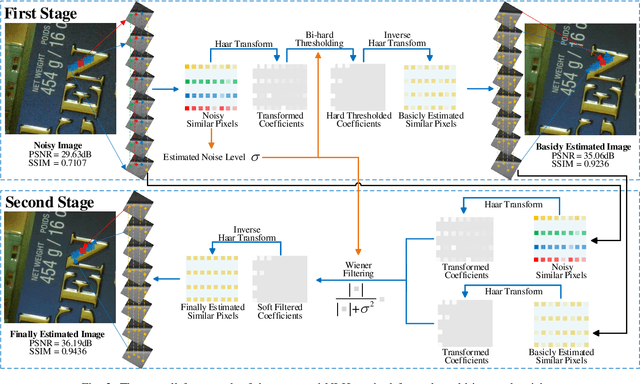

Non-local self similarity (NSS) is a powerful prior of natural images for image denoising. Most of existing denoising methods employ similar patches, which is a patch-level NSS prior. In this paper, we take one step forward by introducing a pixel-level NSS prior, i.e., searching similar pixels across a non-local region. This is motivated by the fact that finding closely similar pixels is more feasible than similar patches in natural images, which can be used to enhance image denoising performance. With the introduced pixel-level NSS prior, we propose an accurate noise level estimation method, and then develop a blind image denoising method based on the lifting Haar transform and Wiener filtering techniques. Experiments on benchmark datasets demonstrate that, the proposed method achieves much better performance than state-of-the-art methods on real-world image denoising. The code will be released.
Noisy-As-Clean: Learning Unsupervised Denoising from the Corrupted Image
Jul 04, 2019
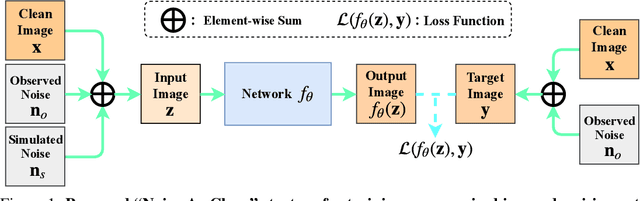
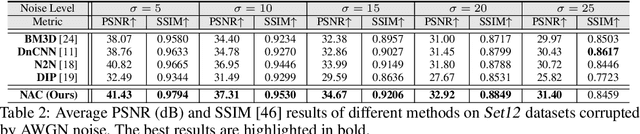
In the past few years, supervised networks have achieved promising performance on image denoising. These methods learn image priors and synthetic noise statistics from plenty pairs of noisy and clean images. Recently, several unsupervised denoising networks are proposed only using external noisy images for training. However, the networks learned from external data inherently suffer from the domain gap dilemma, i.e., the image priors and noise statistics are very different between the training data and the corrupted test images. This dilemma becomes more clear when dealing with the signal dependent realistic noise in real photographs. In this work, we provide a statistically useful conclusion: it is possible to learn an unsupervised network only with the corrupted image, approximating the optimal parameters of a supervised network learned with pairs of noisy and clean images. This is achieved by proposing a "Noisy-As-Clean" strategy: taking the corrupted image as "clean" target and the simulated noisy images (based on the corrupted image) as inputs. Extensive experiments show that the unsupervised denoising networks learned with our "Noisy-As-Clean" strategy surprisingly outperforms previous supervised networks on removing several typical synthetic noise and realistic noise. The code will be publicly released.
STAR: A Structure and Texture Aware Retinex Model
Jun 30, 2019



Retinex theory is developed mainly to decompose an image into the illumination and reflectance components by analyzing local image derivatives. In this theory, larger derivatives are attributed to the changes in piece-wise constant reflectance, while smaller derivatives are emerged in the smooth illumination. In this paper, we propose to utilize the exponentiated derivatives (with an exponent $\gamma$) of an observed image to generate a structure map when being amplified with $\gamma>1$ and a texture map when being shrank with $\gamma<1$. To this end, we design exponential filters for the local derivatives, and present their capability on extracting accurate structure and texture maps, influenced by the choices of exponents $\gamma$ on the local derivatives. The extracted structure and texture maps are employed to regularize the illumination and reflectance components in Retinex decomposition. A novel Structure and Texture Aware Retinex (STAR) model is further proposed for illumination and reflectance decomposition of a single image. We solve the STAR model in an alternating minimization manner. Each sub-problem is transformed into a vectorized least squares regression with closed-form solution. Comprehensive experiments demonstrate that, the proposed STAR model produce better quantitative and qualitative performance than previous competing methods, on illumination and reflectance estimation, low-light image enhancement, and color correction. The code will be publicly released.
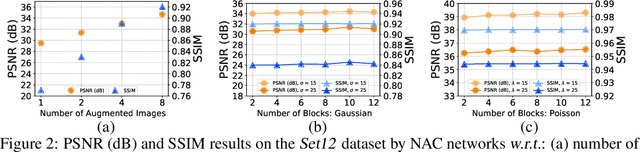
Towards Document Image Quality Assessment: A Text Line Based Framework and A Synthetic Text Line Image Dataset
Jun 05, 2019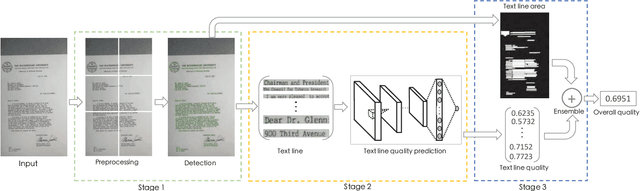
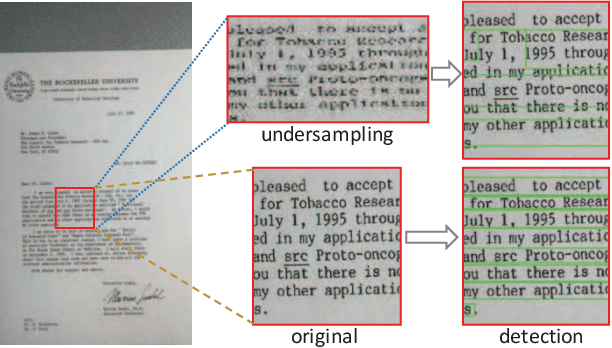

Since the low quality of document images will greatly undermine the chances of success in automatic text recognition and analysis, it is necessary to assess the quality of document images uploaded in online business process, so as to reject those images of low quality. In this paper, we attempt to achieve document image quality assessment and our contributions are twofold. Firstly, since document image quality assessment is more interested in text, we propose a text line based framework to estimate document image quality, which is composed of three stages: text line detection, text line quality prediction, and overall quality assessment. Text line detection aims to find potential text lines with a detector. In the text line quality prediction stage, the quality score is computed for each text line with a CNN-based prediction model. The overall quality of document images is finally assessed with the ensemble of all text line quality. Secondly, to train the prediction model, a large-scale dataset, comprising 52,094 text line images, is synthesized with diverse attributes. For each text line image, a quality label is computed with a piece-wise function. To demonstrate the effectiveness of the proposed framework, comprehensive experiments are evaluated on two popular document image quality assessment benchmarks. Our framework significantly outperforms the state-of-the-art methods by large margins on the large and complicated dataset.
iSAID: A Large-scale Dataset for Instance Segmentation in Aerial Images
May 30, 2019
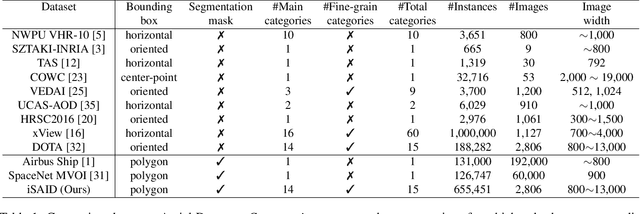
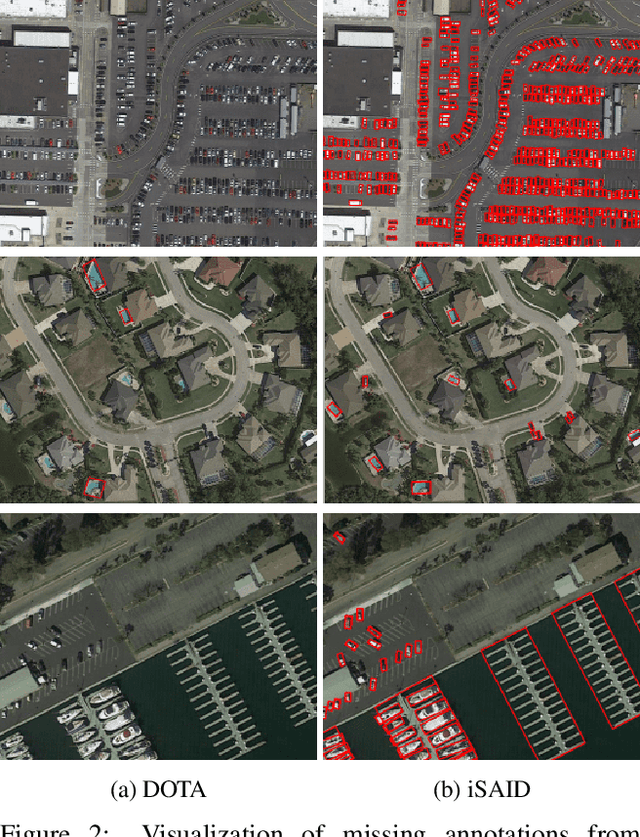
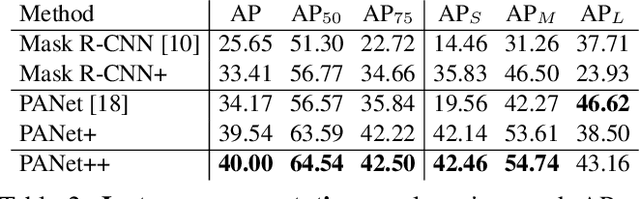
Existing Earth Vision datasets are either suitable for semantic segmentation or object detection. In this work, we introduce the first benchmark dataset for instance segmentation in aerial imagery that combines instance-level object detection and pixel-level segmentation tasks. In comparison to instance segmentation in natural scenes, aerial images present unique challenges e.g., a huge number of instances per image, large object-scale variations and abundant tiny objects. Our large-scale and densely annotated Instance Segmentation in Aerial Images Dataset (iSAID) comes with 655,451 object instances for 15 categories across 2,806 high-resolution images. Such precise per-pixel annotations for each instance ensure accurate localization that is essential for detailed scene analysis. Compared to existing small-scale aerial image based instance segmentation datasets, iSAID contains 15$\times$ the number of object categories and 5$\times$ the number of instances. We benchmark our dataset using two popular instance segmentation approaches for natural images, namely Mask R-CNN and PANet. In our experiments we show that direct application of off-the-shelf Mask R-CNN and PANet on aerial images provide suboptimal instance segmentation results, thus requiring specialized solutions from the research community.
Dynamically Visual Disambiguation of Keyword-based Image Search
May 27, 2019
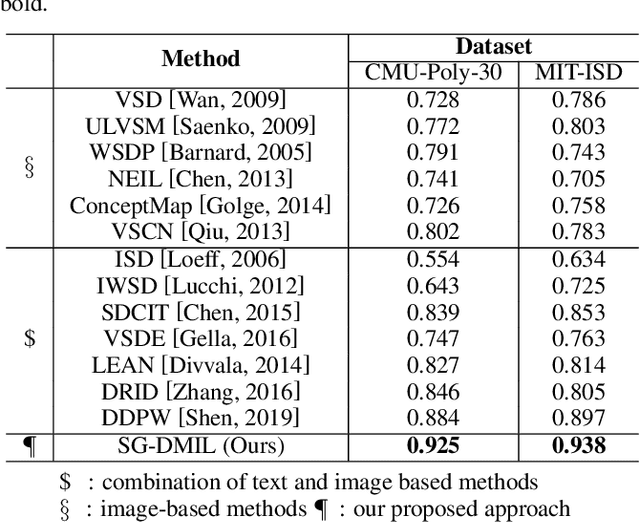
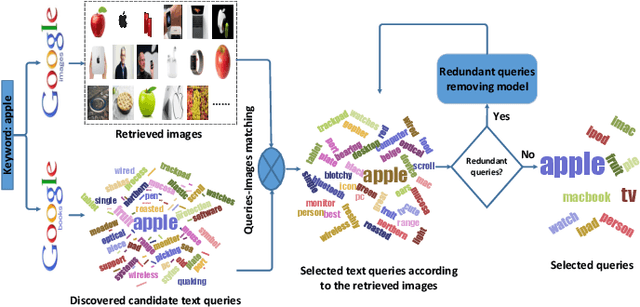
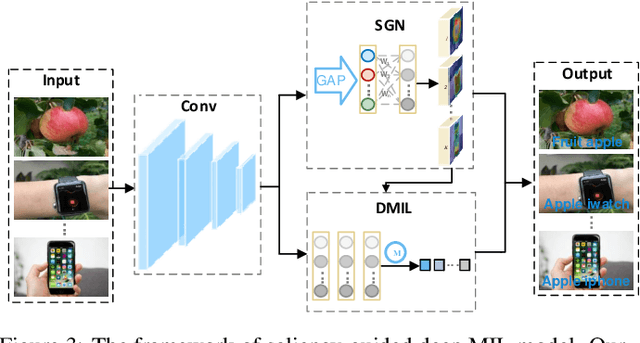
Due to the high cost of manual annotation, learning directly from the web has attracted broad attention. One issue that limits their performance is the problem of visual polysemy. To address this issue, we present an adaptive multi-model framework that resolves polysemy by visual disambiguation. Compared to existing methods, the primary advantage of our approach lies in that our approach can adapt to the dynamic changes in the search results. Our proposed framework consists of two major steps: we first discover and dynamically select the text queries according to the image search results, then we employ the proposed saliency-guided deep multi-instance learning network to remove outliers and learn classification models for visual disambiguation. Extensive experiments demonstrate the superiority of our proposed approach.
Iterative Normalization: Beyond Standardization towards Efficient Whitening
Apr 06, 2019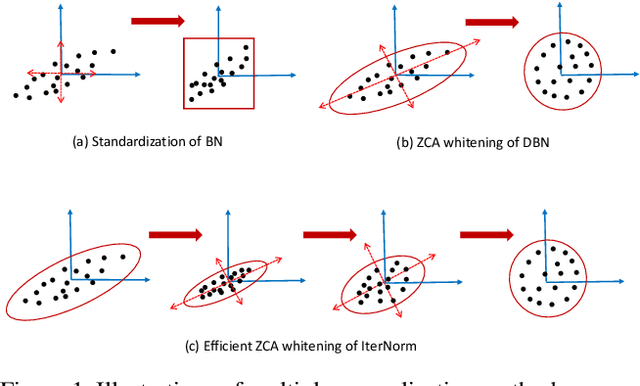
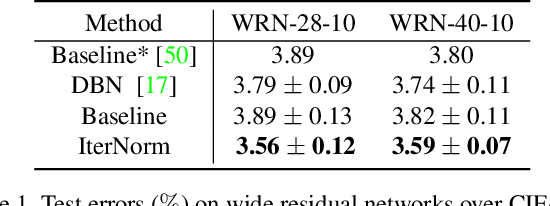
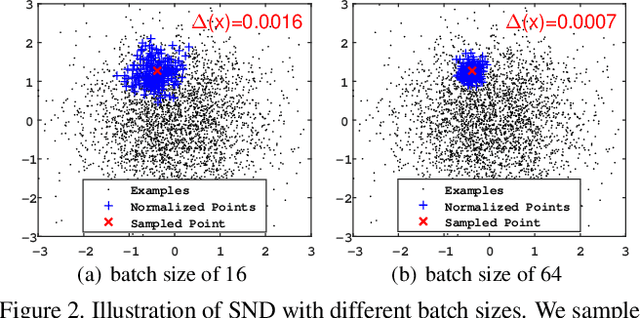
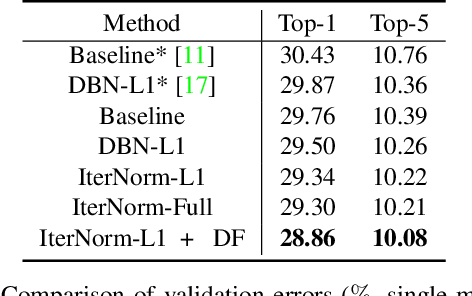
Batch Normalization (BN) is ubiquitously employed for accelerating neural network training and improving the generalization capability by performing standardization within mini-batches. Decorrelated Batch Normalization (DBN) further boosts the above effectiveness by whitening. However, DBN relies heavily on either a large batch size, or eigen-decomposition that suffers from poor efficiency on GPUs. We propose Iterative Normalization (IterNorm), which employs Newton's iterations for much more efficient whitening, while simultaneously avoiding the eigen-decomposition. Furthermore, we develop a comprehensive study to show IterNorm has better trade-off between optimization and generalization, with theoretical and experimental support. To this end, we exclusively introduce Stochastic Normalization Disturbance (SND), which measures the inherent stochastic uncertainty of samples when applied to normalization operations. With the support of SND, we provide natural explanations to several phenomena from the perspective of optimization, e.g., why group-wise whitening of DBN generally outperforms full-whitening and why the accuracy of BN degenerates with reduced batch sizes. We demonstrate the consistently improved performance of IterNorm with extensive experiments on CIFAR-10 and ImageNet over BN and DBN.
Highly-Economized Multi-View Binary Compression for Scalable Image Clustering
Sep 17, 2018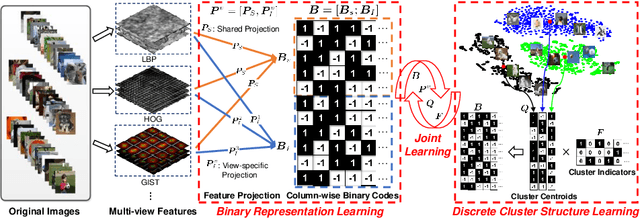
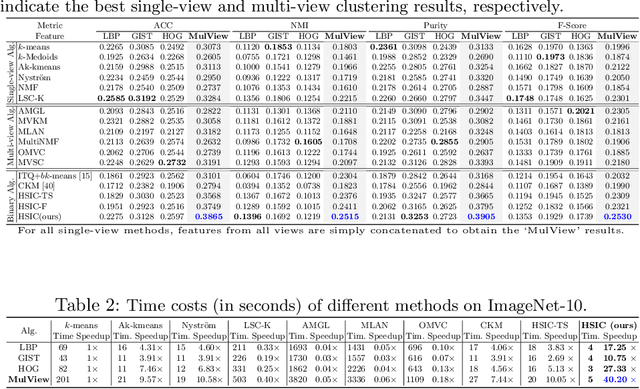
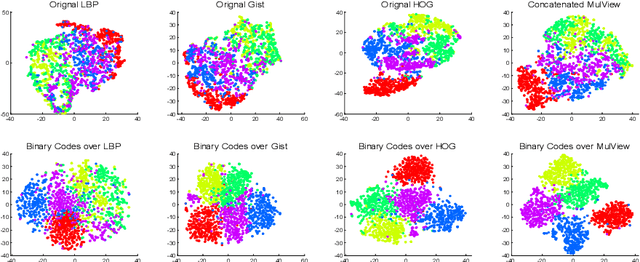
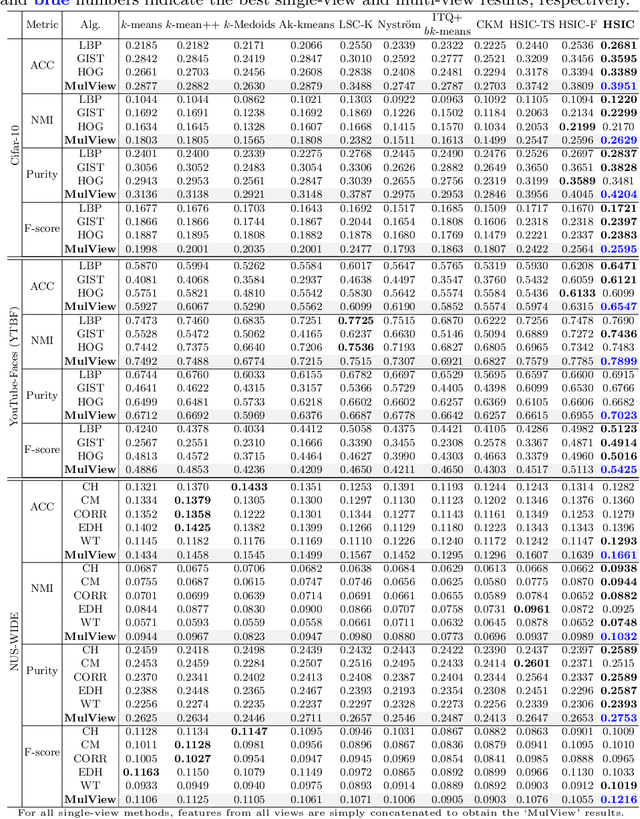
How to economically cluster large-scale multi-view images is a long-standing problem in computer vision. To tackle this challenge, we introduce a novel approach named Highly-economized Scalable Image Clustering (HSIC) that radically surpasses conventional image clustering methods via binary compression. We intuitively unify the binary representation learning and efficient binary cluster structure learning into a joint framework. In particular, common binary representations are learned by exploiting both sharable and individual information across multiple views to capture their underlying correlations. Meanwhile, cluster assignment with robust binary centroids is also performed via effective discrete optimization under L21-norm constraint. By this means, heavy continuous-valued Euclidean distance computations can be successfully reduced by efficient binary XOR operations during the clustering procedure. To our best knowledge, HSIC is the first binary clustering work specifically designed for scalable multi-view image clustering. Extensive experimental results on four large-scale image datasets show that HSIC consistently outperforms the state-of-the-art approaches, whilst significantly reducing computational time and memory footprint.
Baidu Apollo Auto-Calibration System - An Industry-Level Data-Driven and Learning based Vehicle Longitude Dynamic Calibrating Algorithm
Aug 30, 2018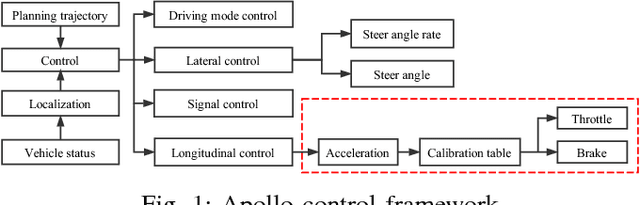
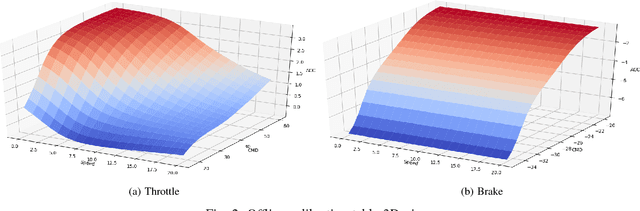
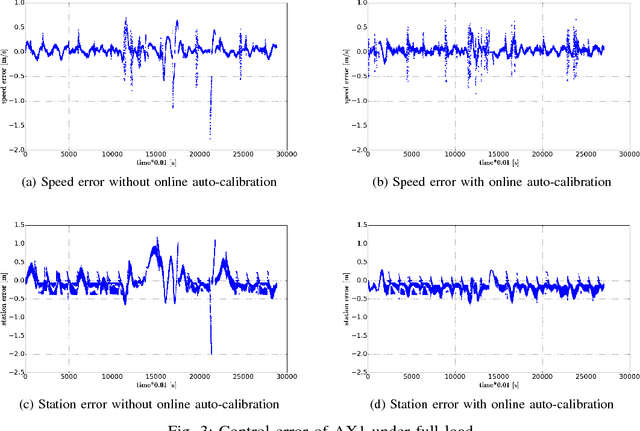
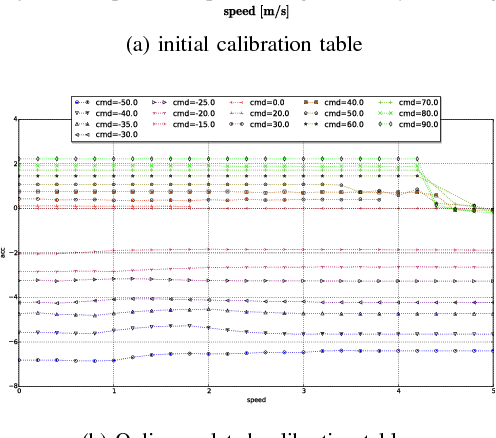
For any autonomous driving vehicle, control module determines its road performance and safety, i.e. its precision and stability should stay within a carefully-designed range. Nonetheless, control algorithms require vehicle dynamics (such as longitudinal dynamics) as inputs, which, unfortunately, are obscure to calibrate in real time. As a result, to achieve reasonable performance, most, if not all, research-oriented autonomous vehicles do manual calibrations in a one-by-one fashion. Since manual calibration is not sustainable once entering into mass production stage for industrial purposes, we here introduce a machine-learning based auto-calibration system for autonomous driving vehicles. In this paper, we will show how we build a data-driven longitudinal calibration procedure using machine learning techniques. We first generated offline calibration tables from human driving data. The offline table serves as an initial guess for later uses and it only needs twenty-minutes data collection and process. We then used an online-learning algorithm to appropriately update the initial table (the offline table) based on real-time performance analysis. This longitudinal auto-calibration system has been deployed to more than one hundred Baidu Apollo self-driving vehicles (including hybrid family vehicles and electronic delivery-only vehicles) since April 2018. By August 27, 2018, it had been tested for more than two thousands hours, ten thousands kilometers (6,213 miles) and yet proven to be effective.