 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSceneGraphNet: Neural Message Passing for 3D Indoor Scene Augmentation
Jul 25, 2019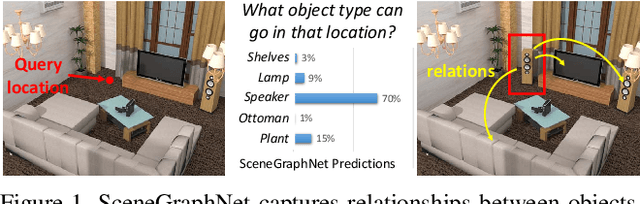
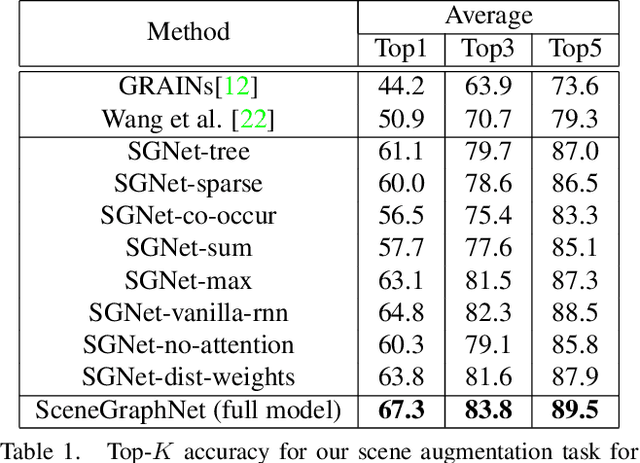

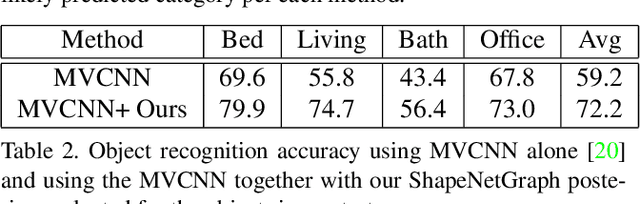
In this paper we propose a neural message passing approach to augment an input 3D indoor scene with new objects matching their surroundings. Given an input, potentially incomplete, 3D scene and a query location, our method predicts a probability distribution over object types that fit well in that location. Our distribution is predicted though passing learned messages in a dense graph whose nodes represent objects in the input scene and edges represent spatial and structural relationships. By weighting messages through an attention mechanism, our method learns to focus on the most relevant surrounding scene context to predict new scene objects. We found that our method significantly outperforms state-of-the-art approaches in terms of correctly predicting objects missing in a scene based on our experiments in the SUNCG dataset. We also demonstrate other applications of our method, including context-based 3D object recognition and iterative scene generation.
Learning Material-Aware Local Descriptors for 3D Shapes
Oct 20, 2018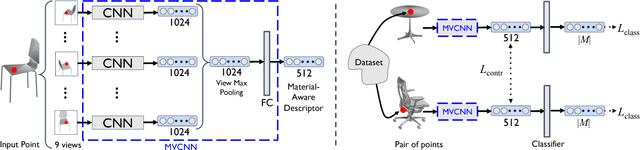
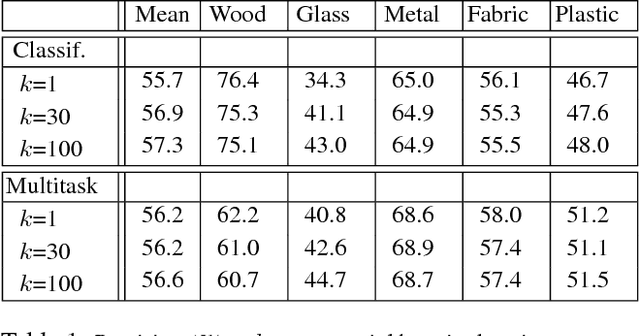
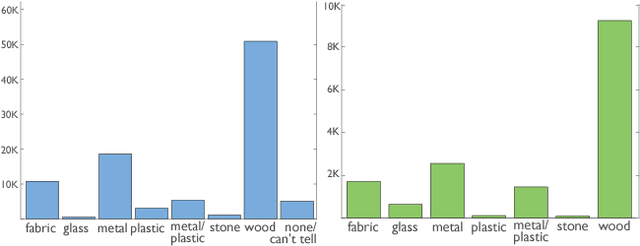
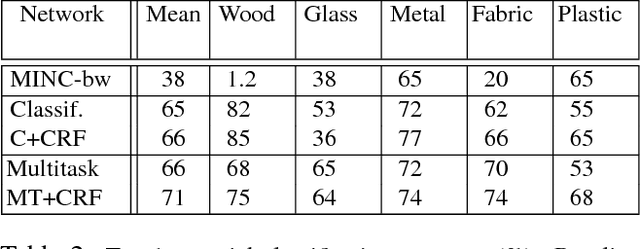
Material understanding is critical for design, geometric modeling, and analysis of functional objects. We enable material-aware 3D shape analysis by employing a projective convolutional neural network architecture to learn material- aware descriptors from view-based representations of 3D points for point-wise material classification or material- aware retrieval. Unfortunately, only a small fraction of shapes in 3D repositories are labeled with physical mate- rials, posing a challenge for learning methods. To address this challenge, we crowdsource a dataset of 3080 3D shapes with part-wise material labels. We focus on furniture models which exhibit interesting structure and material variabil- ity. In addition, we also contribute a high-quality expert- labeled benchmark of 115 shapes from Herman-Miller and IKEA for evaluation. We further apply a mesh-aware con- ditional random field, which incorporates rotational and reflective symmetries, to smooth our local material predic- tions across neighboring surface patches. We demonstrate the effectiveness of our learned descriptors for automatic texturing, material-aware retrieval, and physical simulation. The dataset and code will be publicly available.
Deep Part Induction from Articulated Object Pairs
Sep 19, 2018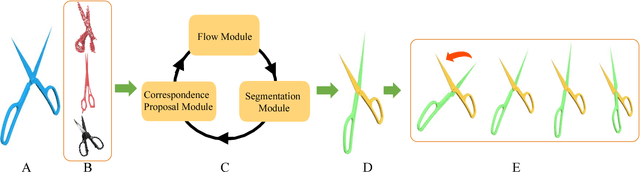
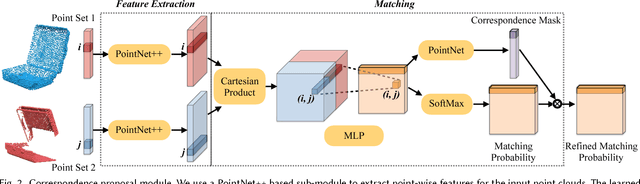
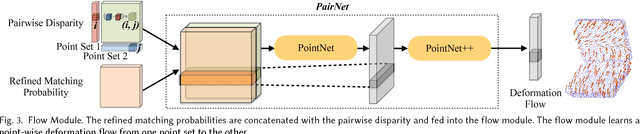
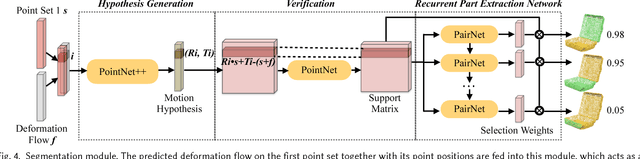
Object functionality is often expressed through part articulation -- as when the two rigid parts of a scissor pivot against each other to perform the cutting function. Such articulations are often similar across objects within the same functional category. In this paper, we explore how the observation of different articulation states provides evidence for part structure and motion of 3D objects. Our method takes as input a pair of unsegmented shapes representing two different articulation states of two functionally related objects, and induces their common parts along with their underlying rigid motion. This is a challenging setting, as we assume no prior shape structure, no prior shape category information, no consistent shape orientation, the articulation states may belong to objects of different geometry, plus we allow inputs to be noisy and partial scans, or point clouds lifted from RGB images. Our method learns a neural network architecture with three modules that respectively propose correspondences, estimate 3D deformation flows, and perform segmentation. To achieve optimal performance, our architecture alternates between correspondence, deformation flow, and segmentation prediction iteratively in an ICP-like fashion. Our results demonstrate that our method significantly outperforms state-of-the-art techniques in the task of discovering articulated parts of objects. In addition, our part induction is object-class agnostic and successfully generalizes to new and unseen objects.
SPLATNet: Sparse Lattice Networks for Point Cloud Processing
May 09, 2018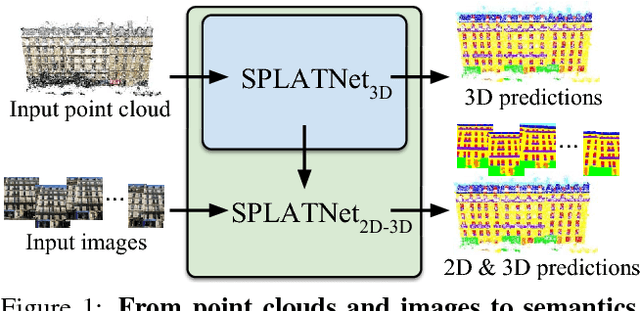
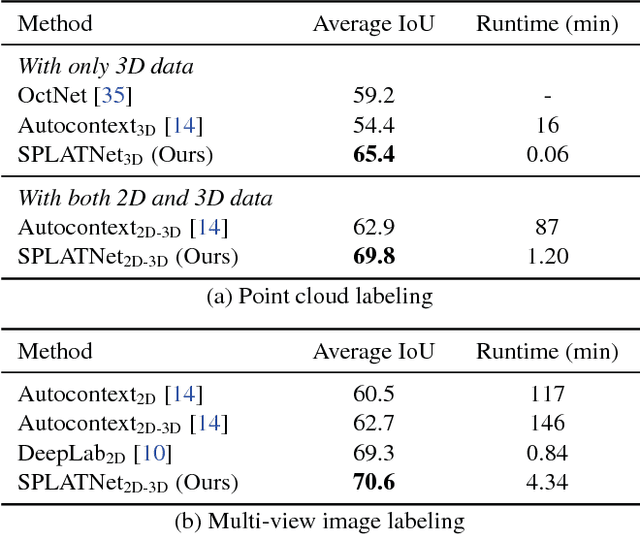
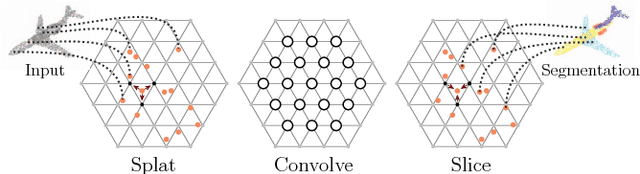
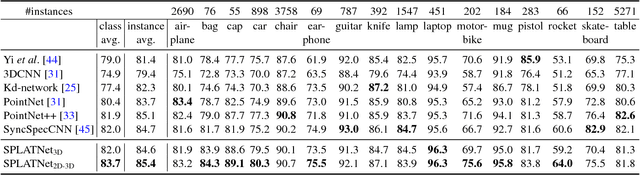
We present a network architecture for processing point clouds that directly operates on a collection of points represented as a sparse set of samples in a high-dimensional lattice. Naively applying convolutions on this lattice scales poorly, both in terms of memory and computational cost, as the size of the lattice increases. Instead, our network uses sparse bilateral convolutional layers as building blocks. These layers maintain efficiency by using indexing structures to apply convolutions only on occupied parts of the lattice, and allow flexible specifications of the lattice structure enabling hierarchical and spatially-aware feature learning, as well as joint 2D-3D reasoning. Both point-based and image-based representations can be easily incorporated in a network with such layers and the resulting model can be trained in an end-to-end manner. We present results on 3D segmentation tasks where our approach outperforms existing state-of-the-art techniques.
CSGNet: Neural Shape Parser for Constructive Solid Geometry
Mar 31, 2018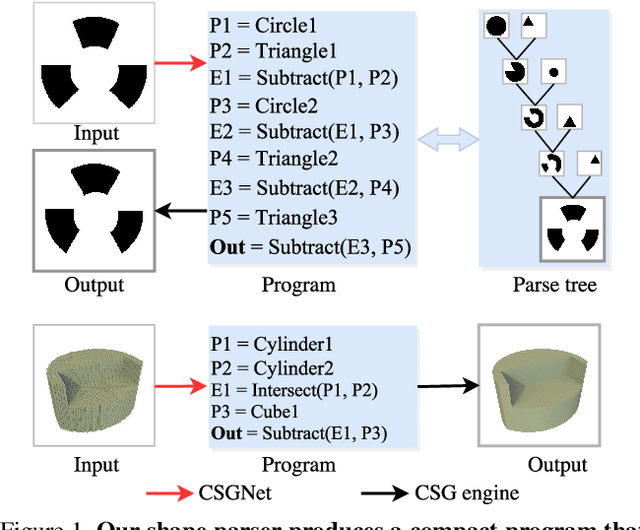
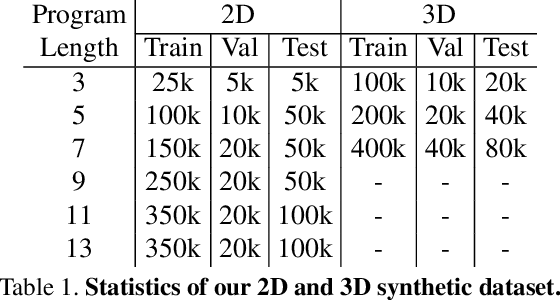
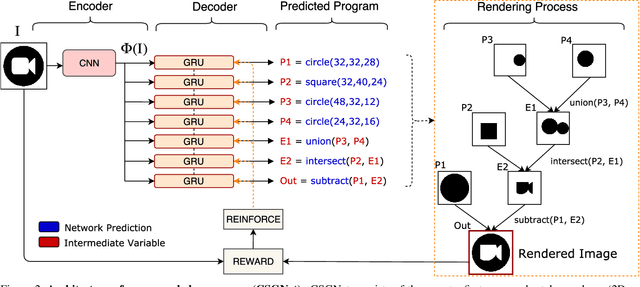
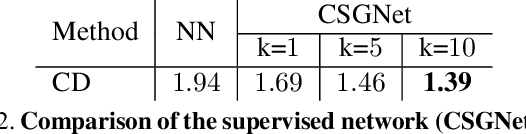
We present a neural architecture that takes as input a 2D or 3D shape and outputs a program that generates the shape. The instructions in our program are based on constructive solid geometry principles, i.e., a set of boolean operations on shape primitives defined recursively. Bottom-up techniques for this shape parsing task rely on primitive detection and are inherently slow since the search space over possible primitive combinations is large. In contrast, our model uses a recurrent neural network that parses the input shape in a top-down manner, which is significantly faster and yields a compact and easy-to-interpret sequence of modeling instructions. Our model is also more effective as a shape detector compared to existing state-of-the-art detection techniques. We finally demonstrate that our network can be trained on novel datasets without ground-truth program annotations through policy gradient techniques.
3D Shape Segmentation with Projective Convolutional Networks
Nov 13, 2017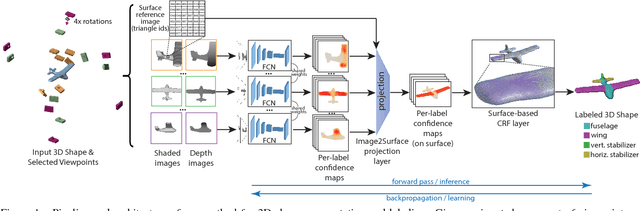

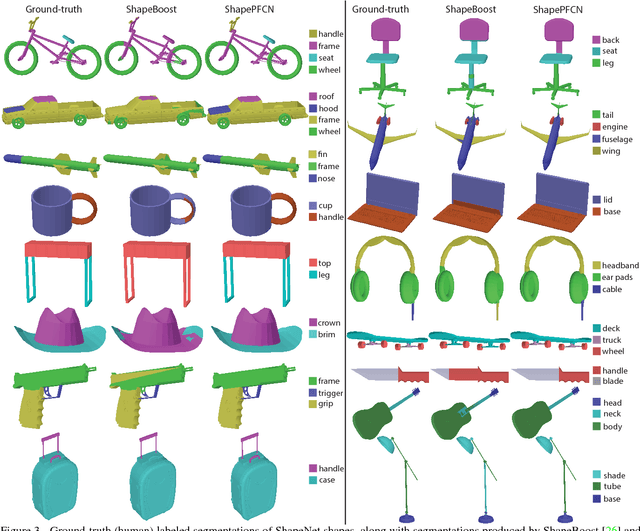
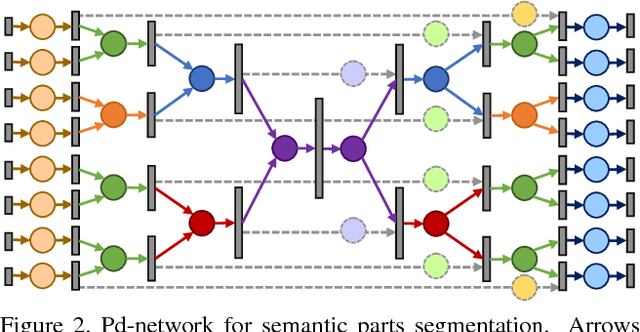
This paper introduces a deep architecture for segmenting 3D objects into their labeled semantic parts. Our architecture combines image-based Fully Convolutional Networks (FCNs) and surface-based Conditional Random Fields (CRFs) to yield coherent segmentations of 3D shapes. The image-based FCNs are used for efficient view-based reasoning about 3D object parts. Through a special projection layer, FCN outputs are effectively aggregated across multiple views and scales, then are projected onto the 3D object surfaces. Finally, a surface-based CRF combines the projected outputs with geometric consistency cues to yield coherent segmentations. The whole architecture (multi-view FCNs and CRF) is trained end-to-end. Our approach significantly outperforms the existing state-of-the-art methods in the currently largest segmentation benchmark (ShapeNet). Finally, we demonstrate promising segmentation results on noisy 3D shapes acquired from consumer-grade depth cameras.
Large-Scale 3D Shape Reconstruction and Segmentation from ShapeNet Core55
Oct 27, 2017
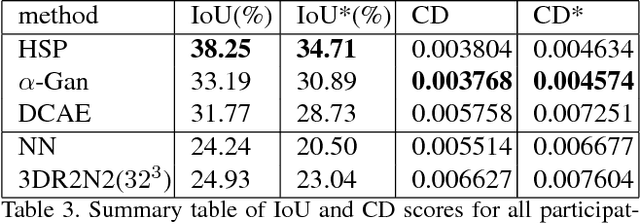
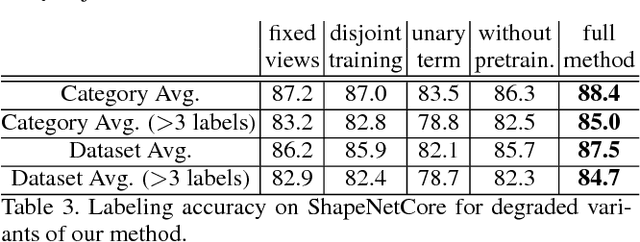
We introduce a large-scale 3D shape understanding benchmark using data and annotation from ShapeNet 3D object database. The benchmark consists of two tasks: part-level segmentation of 3D shapes and 3D reconstruction from single view images. Ten teams have participated in the challenge and the best performing teams have outperformed state-of-the-art approaches on both tasks. A few novel deep learning architectures have been proposed on various 3D representations on both tasks. We report the techniques used by each team and the corresponding performances. In addition, we summarize the major discoveries from the reported results and possible trends for the future work in the field.
3D Shape Reconstruction from Sketches via Multi-view Convolutional Networks
Sep 29, 2017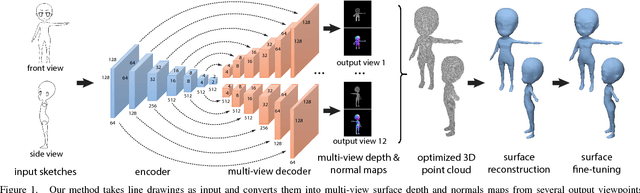

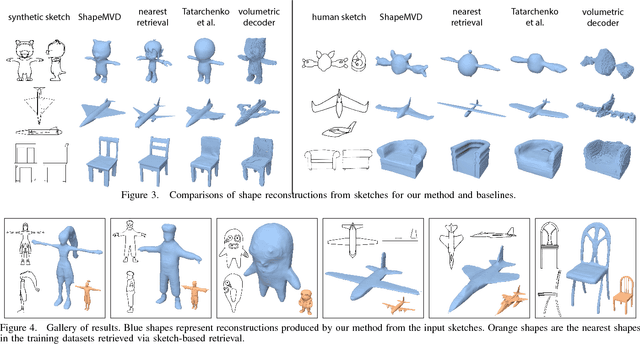
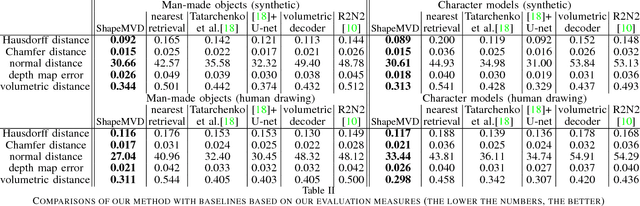
We propose a method for reconstructing 3D shapes from 2D sketches in the form of line drawings. Our method takes as input a single sketch, or multiple sketches, and outputs a dense point cloud representing a 3D reconstruction of the input sketch(es). The point cloud is then converted into a polygon mesh. At the heart of our method lies a deep, encoder-decoder network. The encoder converts the sketch into a compact representation encoding shape information. The decoder converts this representation into depth and normal maps capturing the underlying surface from several output viewpoints. The multi-view maps are then consolidated into a 3D point cloud by solving an optimization problem that fuses depth and normals across all viewpoints. Based on our experiments, compared to other methods, such as volumetric networks, our architecture offers several advantages, including more faithful reconstruction, higher output surface resolution, better preservation of topology and shape structure.
High-Resolution Shape Completion Using Deep Neural Networks for Global Structure and Local Geometry Inference
Sep 22, 2017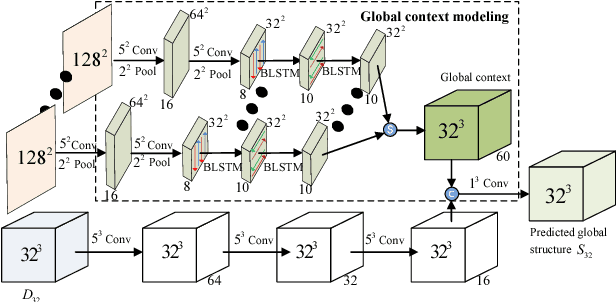


We propose a data-driven method for recovering miss-ing parts of 3D shapes. Our method is based on a new deep learning architecture consisting of two sub-networks: a global structure inference network and a local geometry refinement network. The global structure inference network incorporates a long short-term memorized context fusion module (LSTM-CF) that infers the global structure of the shape based on multi-view depth information provided as part of the input. It also includes a 3D fully convolutional (3DFCN) module that further enriches the global structure representation according to volumetric information in the input. Under the guidance of the global structure network, the local geometry refinement network takes as input lo-cal 3D patches around missing regions, and progressively produces a high-resolution, complete surface through a volumetric encoder-decoder architecture. Our method jointly trains the global structure inference and local geometry refinement networks in an end-to-end manner. We perform qualitative and quantitative evaluations on six object categories, demonstrating that our method outperforms existing state-of-the-art work on shape completion.
Learning Local Shape Descriptors from Part Correspondences With Multi-view Convolutional Networks
Sep 05, 2017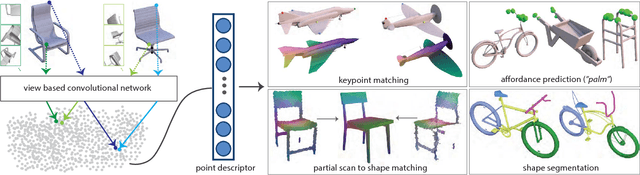
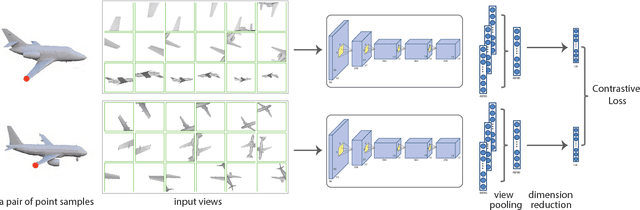
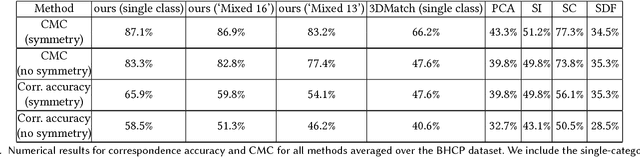

We present a new local descriptor for 3D shapes, directly applicable to a wide range of shape analysis problems such as point correspondences, semantic segmentation, affordance prediction, and shape-to-scan matching. The descriptor is produced by a convolutional network that is trained to embed geometrically and semantically similar points close to one another in descriptor space. The network processes surface neighborhoods around points on a shape that are captured at multiple scales by a succession of progressively zoomed out views, taken from carefully selected camera positions. We leverage two extremely large sources of data to train our network. First, since our network processes rendered views in the form of 2D images, we repurpose architectures pre-trained on massive image datasets. Second, we automatically generate a synthetic dense point correspondence dataset by non-rigid alignment of corresponding shape parts in a large collection of segmented 3D models. As a result of these design choices, our network effectively encodes multi-scale local context and fine-grained surface detail. Our network can be trained to produce either category-specific descriptors or more generic descriptors by learning from multiple shape categories. Once trained, at test time, the network extracts local descriptors for shapes without requiring any part segmentation as input. Our method can produce effective local descriptors even for shapes whose category is unknown or different from the ones used while training. We demonstrate through several experiments that our learned local descriptors are more discriminative compared to state of the art alternatives, and are effective in a variety of shape analysis applications.