 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedMVP: Federated Multi-modal Visual Prompt Tuning for Vision-Language Models
Apr 29, 2025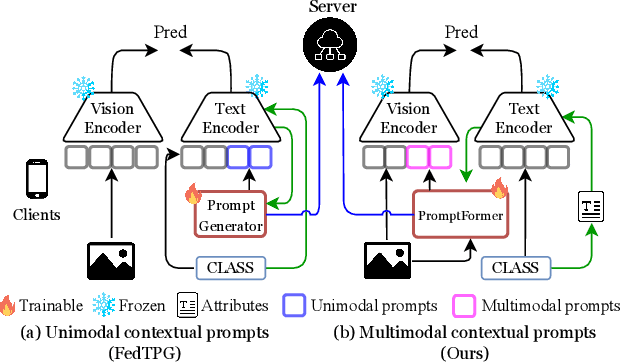
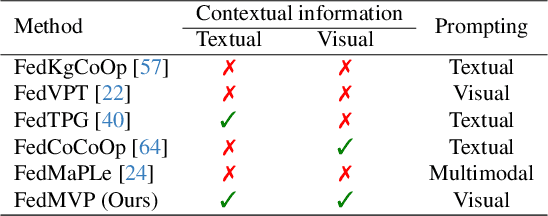
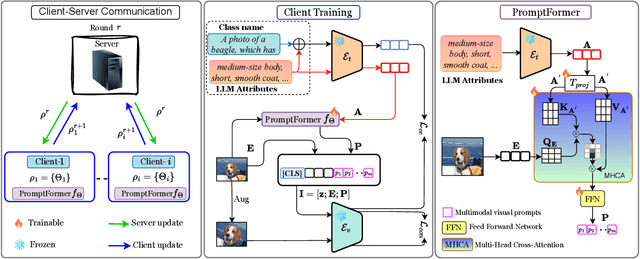
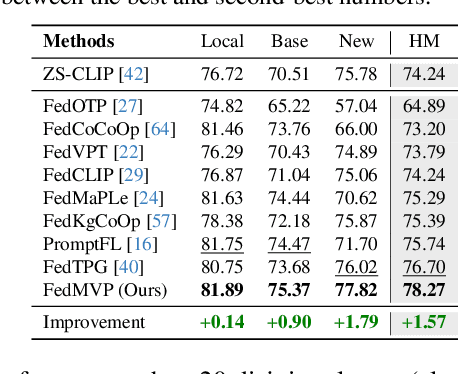
Textual prompt tuning adapts Vision-Language Models (e.g., CLIP) in federated learning by tuning lightweight input tokens (or prompts) on local client data, while keeping network weights frozen. Post training, only the prompts are shared by the clients with the central server for aggregation. However, textual prompt tuning often struggles with overfitting to known concepts and may be overly reliant on memorized text features, limiting its adaptability to unseen concepts. To address this limitation, we propose Federated Multimodal Visual Prompt Tuning (FedMVP) that conditions the prompts on comprehensive contextual information -- image-conditioned features and textual attribute features of a class -- that is multimodal in nature. At the core of FedMVP is a PromptFormer module that synergistically aligns textual and visual features through cross-attention, enabling richer contexual integration. The dynamically generated multimodal visual prompts are then input to the frozen vision encoder of CLIP, and trained with a combination of CLIP similarity loss and a consistency loss. Extensive evaluation on 20 datasets spanning three generalization settings demonstrates that FedMVP not only preserves performance on in-distribution classes and domains, but also displays higher generalizability to unseen classes and domains when compared to state-of-the-art methods. Codes will be released upon acceptance.
On Large Multimodal Models as Open-World Image Classifiers
Mar 27, 2025



Traditional image classification requires a predefined list of semantic categories. In contrast, Large Multimodal Models (LMMs) can sidestep this requirement by classifying images directly using natural language (e.g., answering the prompt "What is the main object in the image?"). Despite this remarkable capability, most existing studies on LMM classification performance are surprisingly limited in scope, often assuming a closed-world setting with a predefined set of categories. In this work, we address this gap by thoroughly evaluating LMM classification performance in a truly open-world setting. We first formalize the task and introduce an evaluation protocol, defining various metrics to assess the alignment between predicted and ground truth classes. We then evaluate 13 models across 10 benchmarks, encompassing prototypical, non-prototypical, fine-grained, and very fine-grained classes, demonstrating the challenges LMMs face in this task. Further analyses based on the proposed metrics reveal the types of errors LMMs make, highlighting challenges related to granularity and fine-grained capabilities, showing how tailored prompting and reasoning can alleviate them.
Training-Free Personalization via Retrieval and Reasoning on Fingerprints
Mar 24, 2025



Vision Language Models (VLMs) have lead to major improvements in multimodal reasoning, yet they still struggle to understand user-specific concepts. Existing personalization methods address this limitation but heavily rely on training procedures, that can be either costly or unpleasant to individual users. We depart from existing work, and for the first time explore the training-free setting in the context of personalization. We propose a novel method, Retrieval and Reasoning for Personalization (R2P), leveraging internal knowledge of VLMs. First, we leverage VLMs to extract the concept fingerprint, i.e., key attributes uniquely defining the concept within its semantic class. When a query arrives, the most similar fingerprints are retrieved and scored via chain-of-thought-reasoning. To reduce the risk of hallucinations, the scores are validated through cross-modal verification at the attribute level: in case of a discrepancy between the scores, R2P refines the concept association via pairwise multimodal matching, where the retrieved fingerprints and their images are directly compared with the query. We validate R2P on two publicly available benchmarks and a newly introduced dataset, Personal Concepts with Visual Ambiguity (PerVA), for concept identification highlighting challenges in visual ambiguity. R2P consistently outperforms state-of-the-art approaches on various downstream tasks across all benchmarks. Code will be available upon acceptance.
Compositional Caching for Training-free Open-vocabulary Attribute Detection
Mar 24, 2025Attribute detection is crucial for many computer vision tasks, as it enables systems to describe properties such as color, texture, and material. Current approaches often rely on labor-intensive annotation processes which are inherently limited: objects can be described at an arbitrary level of detail (e.g., color vs. color shades), leading to ambiguities when the annotators are not instructed carefully. Furthermore, they operate within a predefined set of attributes, reducing scalability and adaptability to unforeseen downstream applications. We present Compositional Caching (ComCa), a training-free method for open-vocabulary attribute detection that overcomes these constraints. ComCa requires only the list of target attributes and objects as input, using them to populate an auxiliary cache of images by leveraging web-scale databases and Large Language Models to determine attribute-object compatibility. To account for the compositional nature of attributes, cache images receive soft attribute labels. Those are aggregated at inference time based on the similarity between the input and cache images, refining the predictions of underlying Vision-Language Models (VLMs). Importantly, our approach is model-agnostic, compatible with various VLMs. Experiments on public datasets demonstrate that ComCa significantly outperforms zero-shot and cache-based baselines, competing with recent training-based methods, proving that a carefully designed training-free approach can successfully address open-vocabulary attribute detection.
Not Only Text: Exploring Compositionality of Visual Representations in Vision-Language Models
Mar 21, 2025Vision-Language Models (VLMs) learn a shared feature space for text and images, enabling the comparison of inputs of different modalities. While prior works demonstrated that VLMs organize natural language representations into regular structures encoding composite meanings, it remains unclear if compositional patterns also emerge in the visual embedding space. In this work, we investigate compositionality in the image domain, where the analysis of compositional properties is challenged by noise and sparsity of visual data. We address these problems and propose a framework, called Geodesically Decomposable Embeddings (GDE), that approximates image representations with geometry-aware compositional structures in the latent space. We demonstrate that visual embeddings of pre-trained VLMs exhibit a compositional arrangement, and evaluate the effectiveness of this property in the tasks of compositional classification and group robustness. GDE achieves stronger performance in compositional classification compared to its counterpart method that assumes linear geometry of the latent space. Notably, it is particularly effective for group robustness, where we achieve higher results than task-specific solutions. Our results indicate that VLMs can automatically develop a human-like form of compositional reasoning in the visual domain, making their underlying processes more interpretable. Code is available at https://github.com/BerasiDavide/vlm_image_compositionality.
Rethinking Few-Shot Adaptation of Vision-Language Models in Two Stages
Mar 14, 2025



An old-school recipe for training a classifier is to (i) learn a good feature extractor and (ii) optimize a linear layer atop. When only a handful of samples are available per category, as in Few-Shot Adaptation (FSA), data are insufficient to fit a large number of parameters, rendering the above impractical. This is especially true with large pre-trained Vision-Language Models (VLMs), which motivated successful research at the intersection of Parameter-Efficient Fine-tuning (PEFT) and FSA. In this work, we start by analyzing the learning dynamics of PEFT techniques when trained on few-shot data from only a subset of categories, referred to as the ``base'' classes. We show that such dynamics naturally splits into two distinct phases: (i) task-level feature extraction and (ii) specialization to the available concepts. To accommodate this dynamic, we then depart from prompt- or adapter-based methods and tackle FSA differently. Specifically, given a fixed computational budget, we split it to (i) learn a task-specific feature extractor via PEFT and (ii) train a linear classifier on top. We call this scheme Two-Stage Few-Shot Adaptation (2SFS). Differently from established methods, our scheme enables a novel form of selective inference at a category level, i.e., at test time, only novel categories are embedded by the adapted text encoder, while embeddings of base categories are available within the classifier. Results with fixed hyperparameters across two settings, three backbones, and eleven datasets, show that 2SFS matches or surpasses the state-of-the-art, while established methods degrade significantly across settings.
Group-robust Machine Unlearning
Mar 12, 2025



Machine unlearning is an emerging paradigm to remove the influence of specific training data (i.e., the forget set) from a model while preserving its knowledge of the rest of the data (i.e., the retain set). Previous approaches assume the forget data to be uniformly distributed from all training datapoints. However, if the data to unlearn is dominant in one group, we empirically show that performance for this group degrades, leading to fairness issues. This work tackles the overlooked problem of non-uniformly distributed forget sets, which we call group-robust machine unlearning, by presenting a simple, effective strategy that mitigates the performance loss in dominant groups via sample distribution reweighting. Moreover, we present MIU (Mutual Information-aware Machine Unlearning), the first approach for group robustness in approximate machine unlearning. MIU minimizes the mutual information between model features and group information, achieving unlearning while reducing performance degradation in the dominant group of the forget set. Additionally, MIU exploits sample distribution reweighting and mutual information calibration with the original model to preserve group robustness. We conduct experiments on three datasets and show that MIU outperforms standard methods, achieving unlearning without compromising model robustness. Source code available at https://github.com/tdemin16/group-robust_machine_unlearning.
One VLM to Keep it Learning: Generation and Balancing for Data-free Continual Visual Question Answering
Nov 04, 2024



Vision-Language Models (VLMs) have shown significant promise in Visual Question Answering (VQA) tasks by leveraging web-scale multimodal datasets. However, these models often struggle with continual learning due to catastrophic forgetting when adapting to new tasks. As an effective remedy to mitigate catastrophic forgetting, rehearsal strategy uses the data of past tasks upon learning new task. However, such strategy incurs the need of storing past data, which might not be feasible due to hardware constraints or privacy concerns. In this work, we propose the first data-free method that leverages the language generation capability of a VLM, instead of relying on external models, to produce pseudo-rehearsal data for addressing continual VQA. Our proposal, named as GaB, generates pseudo-rehearsal data by posing previous task questions on new task data. Yet, despite being effective, the distribution of generated questions skews towards the most frequently posed questions due to the limited and task-specific training data. To mitigate this issue, we introduce a pseudo-rehearsal balancing module that aligns the generated data towards the ground-truth data distribution using either the question meta-statistics or an unsupervised clustering method. We evaluate our proposed method on two recent benchmarks, \ie VQACL-VQAv2 and CLOVE-function benchmarks. GaB outperforms all the data-free baselines with substantial improvement in maintaining VQA performance across evolving tasks, while being on-par with methods with access to the past data.
Retrieval-enriched zero-shot image classification in low-resource domains
Nov 01, 2024



Low-resource domains, characterized by scarce data and annotations, present significant challenges for language and visual understanding tasks, with the latter much under-explored in the literature. Recent advancements in Vision-Language Models (VLM) have shown promising results in high-resource domains but fall short in low-resource concepts that are under-represented (e.g. only a handful of images per category) in the pre-training set. We tackle the challenging task of zero-shot low-resource image classification from a novel perspective. By leveraging a retrieval-based strategy, we achieve this in a training-free fashion. Specifically, our method, named CoRE (Combination of Retrieval Enrichment), enriches the representation of both query images and class prototypes by retrieving relevant textual information from large web-crawled databases. This retrieval-based enrichment significantly boosts classification performance by incorporating the broader contextual information relevant to the specific class. We validate our method on a newly established benchmark covering diverse low-resource domains, including medical imaging, rare plants, and circuits. Our experiments demonstrate that CORE outperforms existing state-of-the-art methods that rely on synthetic data generation and model fine-tuning.
Organizing Unstructured Image Collections using Natural Language
Oct 07, 2024



Organizing unstructured visual data into semantic clusters is a key challenge in computer vision. Traditional deep clustering (DC) approaches focus on a single partition of data, while multiple clustering (MC) methods address this limitation by uncovering distinct clustering solutions. The rise of large language models (LLMs) and multimodal LLMs (MLLMs) has enhanced MC by allowing users to define clustering criteria in natural language. However, manually specifying criteria for large datasets is impractical. In this work, we introduce the task Semantic Multiple Clustering (SMC) that aims to automatically discover clustering criteria from large image collections, uncovering interpretable substructures without requiring human input. Our framework, Text Driven Semantic Multiple Clustering (TeDeSC), uses text as a proxy to concurrently reason over large image collections, discover partitioning criteria, expressed in natural language, and reveal semantic substructures. To evaluate TeDeSC, we introduce the COCO-4c and Food-4c benchmarks, each containing four grouping criteria and ground-truth annotations. We apply TeDeSC to various applications, such as discovering biases and analyzing social media image popularity, demonstrating its utility as a tool for automatically organizing image collections and revealing novel insights.