 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrAda: Few-Shot Visual Adaptation for Text-Prompted Segmentation
May 19, 2026Segmenting images is critical for visual understanding but demands extensive pixel-level annotations. Foundational models have enabled new paradigms for predicting new classes guided by textual prompts, without annotations from the target domain. Yet, on specialized target domains, far from the original pre-training, their performance degrades. We study the errors of existing methods under such domain-shift, finding that misclassification rather than mask generation is the main culprit. To address this, we introduce the novel problem of Few-Shot Visual Adaptation for text-prompted Segmentation. This kind of adaptation has been largely studied for image classification, but it remains unexplored for segmentation. We tackle this task with Prototype Adaptation (PrAda), a novel, parameter-efficient method that adapts a frozen text-prompted segmentation model. Our approach learns class-specific prototypes by combining fine-grained pixel features and high-level transformer representations, which are then fused with the original text-based predictions through a learned importance factor. This preserves the model's zero-shot potential while enabling strong adaptation to new domains. Experiments across semantic, instance, and panoptic segmentation on five benchmarks demonstrate that PrAda yields significant improvements over state-of-the-art and proposed baselines.
Show or Tell? A Benchmark To Evaluate Visual and Textual Prompts in Semantic Segmentation
May 06, 2025Prompt engineering has shown remarkable success with large language models, yet its systematic exploration in computer vision remains limited. In semantic segmentation, both textual and visual prompts offer distinct advantages: textual prompts through open-vocabulary methods allow segmentation of arbitrary categories, while visual reference prompts provide intuitive reference examples. However, existing benchmarks evaluate these modalities in isolation, without direct comparison under identical conditions. We present Show or Tell (SoT), a novel benchmark specifically designed to evaluate both visual and textual prompts for semantic segmentation across 14 datasets spanning 7 diverse domains (common scenes, urban, food, waste, parts, tools, and land-cover). We evaluate 5 open-vocabulary methods and 4 visual reference prompt approaches, adapting the latter to handle multi-class segmentation through a confidence-based mask merging strategy. Our extensive experiments reveal that open-vocabulary methods excel with common concepts easily described by text but struggle with complex domains like tools, while visual reference prompt methods achieve good average results but exhibit high variability depending on the input prompt. Through comprehensive quantitative and qualitative analysis, we identify the strengths and weaknesses of both prompting modalities, providing valuable insights to guide future research in vision foundation models for segmentation tasks.
The revenge of BiSeNet: Efficient Multi-Task Image Segmentation
Apr 15, 2024Recent advancements in image segmentation have focused on enhancing the efficiency of the models to meet the demands of real-time applications, especially on edge devices. However, existing research has primarily concentrated on single-task settings, especially on semantic segmentation, leading to redundant efforts and specialized architectures for different tasks. To address this limitation, we propose a novel architecture for efficient multi-task image segmentation, capable of handling various segmentation tasks without sacrificing efficiency or accuracy. We introduce BiSeNetFormer, that leverages the efficiency of two-stream semantic segmentation architectures and it extends them into a mask classification framework. Our approach maintains the efficient spatial and context paths to capture detailed and semantic information, respectively, while leveraging an efficient transformed-based segmentation head that computes the binary masks and class probabilities. By seamlessly supporting multiple tasks, namely semantic and panoptic segmentation, BiSeNetFormer offers a versatile solution for multi-task segmentation. We evaluate our approach on popular datasets, Cityscapes and ADE20K, demonstrating impressive inference speeds while maintaining competitive accuracy compared to state-of-the-art architectures. Our results indicate that BiSeNetFormer represents a significant advancement towards fast, efficient, and multi-task segmentation networks, bridging the gap between model efficiency and task adaptability.
PEM: Prototype-based Efficient MaskFormer for Image Segmentation
Mar 01, 2024



Recent transformer-based architectures have shown impressive results in the field of image segmentation. Thanks to their flexibility, they obtain outstanding performance in multiple segmentation tasks, such as semantic and panoptic, under a single unified framework. To achieve such impressive performance, these architectures employ intensive operations and require substantial computational resources, which are often not available, especially on edge devices. To fill this gap, we propose Prototype-based Efficient MaskFormer (PEM), an efficient transformer-based architecture that can operate in multiple segmentation tasks. PEM proposes a novel prototype-based cross-attention which leverages the redundancy of visual features to restrict the computation and improve the efficiency without harming the performance. In addition, PEM introduces an efficient multi-scale feature pyramid network, capable of extracting features that have high semantic content in an efficient way, thanks to the combination of deformable convolutions and context-based self-modulation. We benchmark the proposed PEM architecture on two tasks, semantic and panoptic segmentation, evaluated on two different datasets, Cityscapes and ADE20K. PEM demonstrates outstanding performance on every task and dataset, outperforming task-specific architectures while being comparable and even better than computationally-expensive baselines.
Cross-Domain Transfer Learning with CoRTe: Consistent and Reliable Transfer from Black-Box to Lightweight Segmentation Model
Feb 20, 2024Many practical applications require training of semantic segmentation models on unlabelled datasets and their execution on low-resource hardware. Distillation from a trained source model may represent a solution for the first but does not account for the different distribution of the training data. Unsupervised domain adaptation (UDA) techniques claim to solve the domain shift, but in most cases assume the availability of the source data or an accessible white-box source model, which in practical applications are often unavailable for commercial and/or safety reasons. In this paper, we investigate a more challenging setting in which a lightweight model has to be trained on a target unlabelled dataset for semantic segmentation, under the assumption that we have access only to black-box source model predictions. Our method, named CoRTe, consists of (i) a pseudo-labelling function that extracts reliable knowledge from the black-box source model using its relative confidence, (ii) a pseudo label refinement method to retain and enhance the novel information learned by the student model on the target data, and (iii) a consistent training of the model using the extracted pseudo labels. We benchmark CoRTe on two synthetic-to-real settings, demonstrating remarkable results when using black-box models to transfer knowledge on lightweight models for a target data distribution.
The Robust Semantic Segmentation UNCV2023 Challenge Results
Sep 27, 2023



This paper outlines the winning solutions employed in addressing the MUAD uncertainty quantification challenge held at ICCV 2023. The challenge was centered around semantic segmentation in urban environments, with a particular focus on natural adversarial scenarios. The report presents the results of 19 submitted entries, with numerous techniques drawing inspiration from cutting-edge uncertainty quantification methodologies presented at prominent conferences in the fields of computer vision and machine learning and journals over the past few years. Within this document, the challenge is introduced, shedding light on its purpose and objectives, which primarily revolved around enhancing the robustness of semantic segmentation in urban scenes under varying natural adversarial conditions. The report then delves into the top-performing solutions. Moreover, the document aims to provide a comprehensive overview of the diverse solutions deployed by all participants. By doing so, it seeks to offer readers a deeper insight into the array of strategies that can be leveraged to effectively handle the inherent uncertainties associated with autonomous driving and semantic segmentation, especially within urban environments.
Mask2Anomaly: Mask Transformer for Universal Open-set Segmentation
Sep 12, 2023Segmenting unknown or anomalous object instances is a critical task in autonomous driving applications, and it is approached traditionally as a per-pixel classification problem. However, reasoning individually about each pixel without considering their contextual semantics results in high uncertainty around the objects' boundaries and numerous false positives. We propose a paradigm change by shifting from a per-pixel classification to a mask classification. Our mask-based method, Mask2Anomaly, demonstrates the feasibility of integrating a mask-classification architecture to jointly address anomaly segmentation, open-set semantic segmentation, and open-set panoptic segmentation. Mask2Anomaly includes several technical novelties that are designed to improve the detection of anomalies/unknown objects: i) a global masked attention module to focus individually on the foreground and background regions; ii) a mask contrastive learning that maximizes the margin between an anomaly and known classes; iii) a mask refinement solution to reduce false positives; and iv) a novel approach to mine unknown instances based on the mask-architecture properties. By comprehensive qualitative and qualitative evaluation, we show Mask2Anomaly achieves new state-of-the-art results across the benchmarks of anomaly segmentation, open-set semantic segmentation, and open-set panoptic segmentation.
Unmasking Anomalies in Road-Scene Segmentation
Jul 25, 2023



Anomaly segmentation is a critical task for driving applications, and it is approached traditionally as a per-pixel classification problem. However, reasoning individually about each pixel without considering their contextual semantics results in high uncertainty around the objects' boundaries and numerous false positives. We propose a paradigm change by shifting from a per-pixel classification to a mask classification. Our mask-based method, Mask2Anomaly, demonstrates the feasibility of integrating an anomaly detection method in a mask-classification architecture. Mask2Anomaly includes several technical novelties that are designed to improve the detection of anomalies in masks: i) a global masked attention module to focus individually on the foreground and background regions; ii) a mask contrastive learning that maximizes the margin between an anomaly and known classes; and iii) a mask refinement solution to reduce false positives. Mask2Anomaly achieves new state-of-the-art results across a range of benchmarks, both in the per-pixel and component-level evaluations. In particular, Mask2Anomaly reduces the average false positives rate by 60% wrt the previous state-of-the-art. Github page: https://github.com/shyam671/Mask2Anomaly-Unmasking-Anomalies-in-Road-Scene-Segmentation.
CoMFormer: Continual Learning in Semantic and Panoptic Segmentation
Nov 25, 2022Continual learning for segmentation has recently seen increasing interest. However, all previous works focus on narrow semantic segmentation and disregard panoptic segmentation, an important task with real-world impacts. %a In this paper, we present the first continual learning model capable of operating on both semantic and panoptic segmentation. Inspired by recent transformer approaches that consider segmentation as a mask-classification problem, we design CoMFormer. Our method carefully exploits the properties of transformer architectures to learn new classes over time. Specifically, we propose a novel adaptive distillation loss along with a mask-based pseudo-labeling technique to effectively prevent forgetting. To evaluate our approach, we introduce a novel continual panoptic segmentation benchmark on the challenging ADE20K dataset. Our CoMFormer outperforms all the existing baselines by forgetting less old classes but also learning more effectively new classes. In addition, we also report an extensive evaluation in the large-scale continual semantic segmentation scenario showing that CoMFormer also significantly outperforms state-of-the-art methods.
Detecting the unknown in Object Detection
Aug 24, 2022
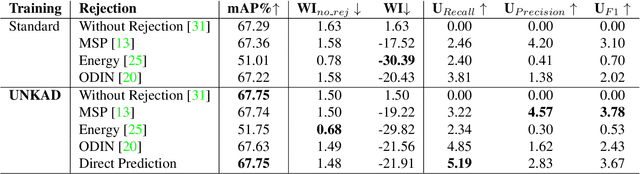

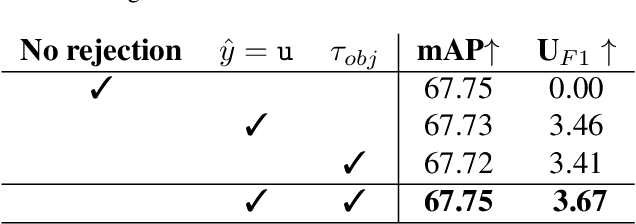
Object detection methods have witnessed impressive improvements in the last years thanks to the design of novel neural network architectures and the availability of large scale datasets. However, current methods have a significant limitation: they are able to detect only the classes observed during training time, that are only a subset of all the classes that a detector may encounter in the real world. Furthermore, the presence of unknown classes is often not considered at training time, resulting in methods not even able to detect that an unknown object is present in the image. In this work, we address the problem of detecting unknown objects, known as open-set object detection. We propose a novel training strategy, called UNKAD, able to predict unknown objects without requiring any annotation of them, exploiting non annotated objects that are already present in the background of training images. In particular, exploiting the four-steps training strategy of Faster R-CNN, UNKAD first identifies and pseudo-labels unknown objects and then uses the pseudo-annotations to train an additional unknown class. While UNKAD can directly detect unknown objects, we further combine it with previous unknown detection techniques, showing that it improves their performance at no costs.