 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHULFSynth : An INR based Super-Resolution and Ultra Low-Field MRI Synthesis via Contrast factor estimation
Nov 18, 2025We present an unsupervised single image bidirectional Magnetic Resonance Image (MRI) synthesizer that synthesizes an Ultra-Low Field (ULF) like image from a High-Field (HF) magnitude image and vice-versa. Unlike existing MRI synthesis models, our approach is inspired by the physics that drives contrast changes between HF and ULF MRIs. Our forward model simulates a HF to ULF transformation by estimating the tissue-type Signal-to-Noise ratio (SNR) values based on target contrast values. For the Super-Resolution task, we used an Implicit Neural Representation (INR) network to synthesize HF image by simultaneously predicting tissue-type segmentations and image intensity without observed HF data. The proposed method is evaluated using synthetic ULF-like data from generated from standard 3T T$_1$-weighted images for qualitative assessments and paired 3T-64mT T$_1$-weighted images for validation experiments. WM-GM contrast improved by 52% in synthetic ULF-like images and 37% in 64mT images. Sensitivity experiments demonstrated the robustness of our forward model to variations in target contrast, noise and initial seeding.
How Should We Evaluate Uncertainty in Accelerated MRI Reconstruction?
Mar 13, 2025Reconstructing accelerated MRI is an ill-posed problem. Machine learning has recently shown great promise at this task, but current approaches to quantifying uncertainty focus on measuring the variability in pixelwise intensity variation. Although these provide interpretable maps, they lack structural understanding and they do not have a clear relationship to how the data will be analysed subsequently. In this paper, we propose a new approach to evaluating reconstruction variability based on apparent anatomical changes in the reconstruction, which is more tightly related to common downstream tasks. We use image registration and segmentation to evaluate several common MRI reconstruction approaches, where uncertainty is measured via ensembling, for accelerated imaging. We demonstrate the intrinsic variability in reconstructed images and show that models with high scores on often used quality metrics such as SSIM and PSNR, can nonetheless display high levels of variance and bias in anatomical measures.
The Robust Semantic Segmentation UNCV2023 Challenge Results
Sep 27, 2023



This paper outlines the winning solutions employed in addressing the MUAD uncertainty quantification challenge held at ICCV 2023. The challenge was centered around semantic segmentation in urban environments, with a particular focus on natural adversarial scenarios. The report presents the results of 19 submitted entries, with numerous techniques drawing inspiration from cutting-edge uncertainty quantification methodologies presented at prominent conferences in the fields of computer vision and machine learning and journals over the past few years. Within this document, the challenge is introduced, shedding light on its purpose and objectives, which primarily revolved around enhancing the robustness of semantic segmentation in urban scenes under varying natural adversarial conditions. The report then delves into the top-performing solutions. Moreover, the document aims to provide a comprehensive overview of the diverse solutions deployed by all participants. By doing so, it seeks to offer readers a deeper insight into the array of strategies that can be leveraged to effectively handle the inherent uncertainties associated with autonomous driving and semantic segmentation, especially within urban environments.
MusIAC: An extensible generative framework for Music Infilling Applications with multi-level Control
Feb 11, 2022
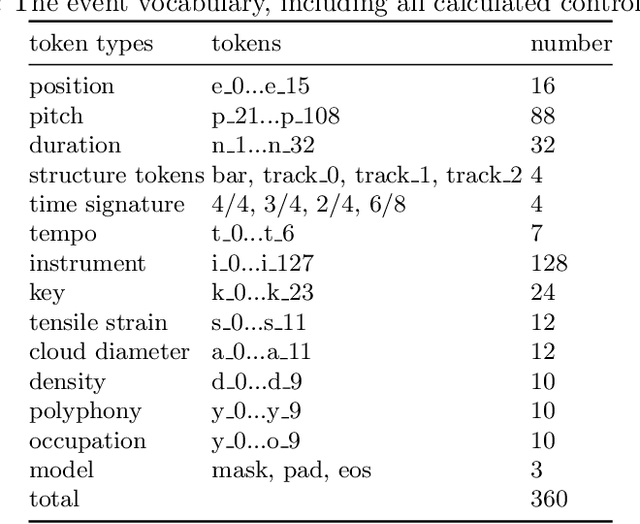


We present a novel music generation framework for music infilling, with a user friendly interface. Infilling refers to the task of generating musical sections given the surrounding multi-track music. The proposed transformer-based framework is extensible for new control tokens as the added music control tokens such as tonal tension per bar and track polyphony level in this work. We explore the effects of including several musically meaningful control tokens, and evaluate the results using objective metrics related to pitch and rhythm. Our results demonstrate that adding additional control tokens helps to generate music with stronger stylistic similarities to the original music. It also provides the user with more control to change properties like the music texture and tonal tension in each bar compared to previous research which only provided control for track density. We present the model in a Google Colab notebook to enable interactive generation.
The GAN that Warped: Semantic Attribute Editing with Unpaired Data
Nov 30, 2018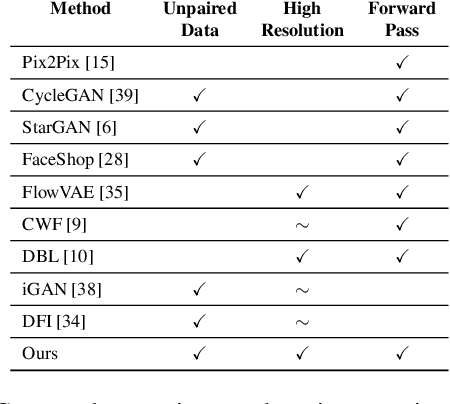
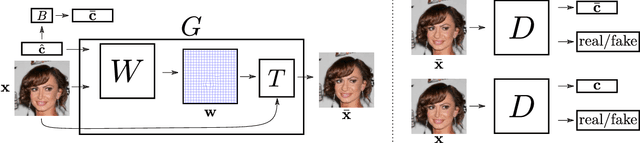
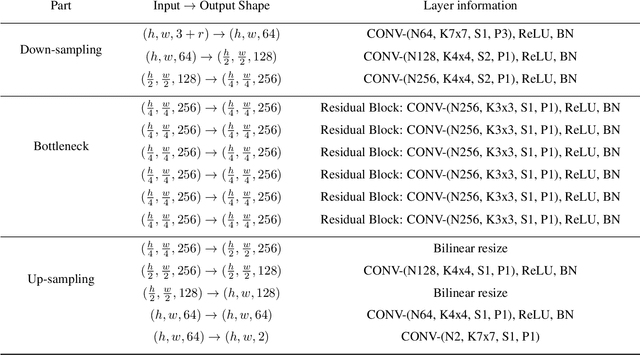

Deep neural networks have recently been used to edit images with great success. However, they are often limited by only being able to work at a restricted range of resolutions. They are also so flexible that semantic face edits can often result in an unwanted loss of identity. This work proposes a model that learns how to perform semantic image edits through the application of smooth warp fields. This warp field can be efficiently predicted at a reasonably low resolution and then resampled and applied at arbitrary resolutions. Previous approaches that attempted to use warping for semantic edits required paired data, that is example images of the same object with different semantic characteristics. In contrast, we employ recent advances in Generative Adversarial Networks that allow our model to be effectively trained with unpaired data. We demonstrate the efficacy of our method for editing face images at very high resolutions (4k images) with an efficient single forward pass of a deep network at a lower resolution. We illustrate how the extent of our edits can be trivially reduced or exaggerated by scaling the predicted warp field, and we also show that our edits are substantially better at maintaining the subject's identity.
Training VAEs Under Structured Residuals
Jul 31, 2018


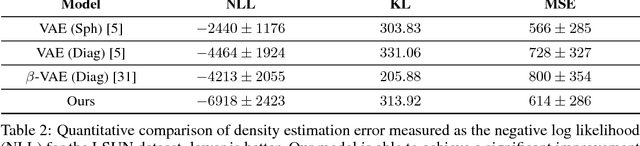
Variational auto-encoders (VAEs) are a popular and powerful deep generative model. Previous works on VAEs have assumed a factorized likelihood model, whereby the output uncertainty of each pixel is assumed to be independent. This approximation is clearly limited as demonstrated by observing a residual image from a VAE reconstruction, which often possess a high level of structure. This paper demonstrates a novel scheme to incorporate a structured Gaussian likelihood prediction network within the VAE that allows the residual correlations to be modeled. Our novel architecture, with minimal increase in complexity, incorporates the covariance matrix prediction within the VAE. We also propose a new mechanism for allowing structured uncertainty on color images. Furthermore, we provide a scheme for effectively training this model, and include some suggestions for improving performance in terms of efficiency or modeling longer range correlations.
Structured Uncertainty Prediction Networks
Mar 23, 2018
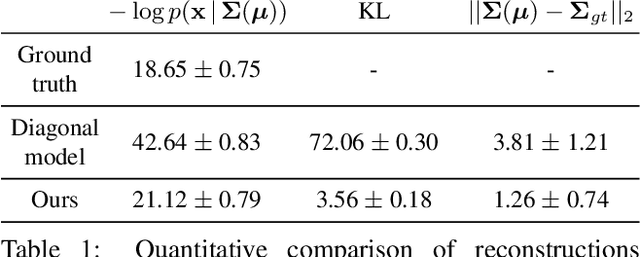
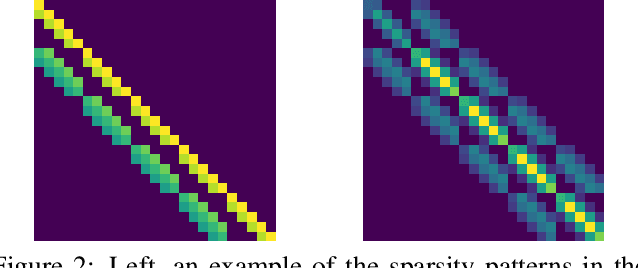

This paper is the first work to propose a network to predict a structured uncertainty distribution for a synthesized image. Previous approaches have been mostly limited to predicting diagonal covariance matrices. Our novel model learns to predict a full Gaussian covariance matrix for each reconstruction, which permits efficient sampling and likelihood evaluation. We demonstrate that our model can accurately reconstruct ground truth correlated residual distributions for synthetic datasets and generate plausible high frequency samples for real face images. We also illustrate the use of these predicted covariances for structure preserving image denoising.