 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate Training Data for Occupancy Map Prediction in Automated Driving Using Evidence Theory
May 17, 2024



Automated driving fundamentally requires knowledge about the surrounding geometry of the scene. Modern approaches use only captured images to predict occupancy maps that represent the geometry. Training these approaches requires accurate data that may be acquired with the help of LiDAR scanners. We show that the techniques used for current benchmarks and training datasets to convert LiDAR scans into occupancy grid maps yield very low quality, and subsequently present a novel approach using evidence theory that yields more accurate reconstructions. We demonstrate that these are superior by a large margin, both qualitatively and quantitatively, and that we additionally obtain meaningful uncertainty estimates. When converting the occupancy maps back to depth estimates and comparing them with the raw LiDAR measurements, our method yields a MAE improvement of 30% to 52% on nuScenes and 53% on Waymo over other occupancy ground-truth data. Finally, we use the improved occupancy maps to train a state-of-the-art occupancy prediction method and demonstrate that it improves the MAE by 25% on nuScenes.
latentSplat: Autoencoding Variational Gaussians for Fast Generalizable 3D Reconstruction
Mar 24, 2024We present latentSplat, a method to predict semantic Gaussians in a 3D latent space that can be splatted and decoded by a light-weight generative 2D architecture. Existing methods for generalizable 3D reconstruction either do not enable fast inference of high resolution novel views due to slow volume rendering, or are limited to interpolation of close input views, even in simpler settings with a single central object, where 360-degree generalization is possible. In this work, we combine a regression-based approach with a generative model, moving towards both of these capabilities within the same method, trained purely on readily available real video data. The core of our method are variational 3D Gaussians, a representation that efficiently encodes varying uncertainty within a latent space consisting of 3D feature Gaussians. From these Gaussians, specific instances can be sampled and rendered via efficient Gaussian splatting and a fast, generative decoder network. We show that latentSplat outperforms previous works in reconstruction quality and generalization, while being fast and scalable to high-resolution data.
Recent Trends in 3D Reconstruction of General Non-Rigid Scenes
Mar 22, 2024Reconstructing models of the real world, including 3D geometry, appearance, and motion of real scenes, is essential for computer graphics and computer vision. It enables the synthesizing of photorealistic novel views, useful for the movie industry and AR/VR applications. It also facilitates the content creation necessary in computer games and AR/VR by avoiding laborious manual design processes. Further, such models are fundamental for intelligent computing systems that need to interpret real-world scenes and actions to act and interact safely with the human world. Notably, the world surrounding us is dynamic, and reconstructing models of dynamic, non-rigidly moving scenes is a severely underconstrained and challenging problem. This state-of-the-art report (STAR) offers the reader a comprehensive summary of state-of-the-art techniques with monocular and multi-view inputs such as data from RGB and RGB-D sensors, among others, conveying an understanding of different approaches, their potential applications, and promising further research directions. The report covers 3D reconstruction of general non-rigid scenes and further addresses the techniques for scene decomposition, editing and controlling, and generalizable and generative modeling. More specifically, we first review the common and fundamental concepts necessary to understand and navigate the field and then discuss the state-of-the-art techniques by reviewing recent approaches that use traditional and machine-learning-based neural representations, including a discussion on the newly enabled applications. The STAR is concluded with a discussion of the remaining limitations and open challenges.
Quantum-Hybrid Stereo Matching With Nonlinear Regularization and Spatial Pyramids
Dec 26, 2023



Quantum visual computing is advancing rapidly. This paper presents a new formulation for stereo matching with nonlinear regularizers and spatial pyramids on quantum annealers as a maximum a posteriori inference problem that minimizes the energy of a Markov Random Field. Our approach is hybrid (i.e., quantum-classical) and is compatible with modern D-Wave quantum annealers, i.e., it includes a quadratic unconstrained binary optimization (QUBO) objective. Previous quantum annealing techniques for stereo matching are limited to using linear regularizers, and thus, they do not exploit the fundamental advantages of the quantum computing paradigm in solving combinatorial optimization problems. In contrast, our method utilizes the full potential of quantum annealing for stereo matching, as nonlinear regularizers create optimization problems which are NP-hard. On the Middlebury benchmark, we achieve an improved root mean squared accuracy over the previous state of the art in quantum stereo matching of 2% and 22.5% when using different solvers.
Neural Point Cloud Diffusion for Disentangled 3D Shape and Appearance Generation
Dec 21, 2023Controllable generation of 3D assets is important for many practical applications like content creation in movies, games and engineering, as well as in AR/VR. Recently, diffusion models have shown remarkable results in generation quality of 3D objects. However, none of the existing models enable disentangled generation to control the shape and appearance separately. For the first time, we present a suitable representation for 3D diffusion models to enable such disentanglement by introducing a hybrid point cloud and neural radiance field approach. We model a diffusion process over point positions jointly with a high-dimensional feature space for a local density and radiance decoder. While the point positions represent the coarse shape of the object, the point features allow modeling the geometry and appearance details. This disentanglement enables us to sample both independently and therefore to control both separately. Our approach sets a new state of the art in generation compared to previous disentanglement-capable methods by reduced FID scores of 30-90% and is on-par with other non disentanglement-capable state-of-the art methods.
Neural Parametric Gaussians for Monocular Non-Rigid Object Reconstruction
Dec 02, 2023Reconstructing dynamic objects from monocular videos is a severely underconstrained and challenging problem, and recent work has approached it in various directions. However, owing to the ill-posed nature of this problem, there has been no solution that can provide consistent, high-quality novel views from camera positions that are significantly different from the training views. In this work, we introduce Neural Parametric Gaussians (NPGs) to take on this challenge by imposing a two-stage approach: first, we fit a low-rank neural deformation model, which then is used as regularization for non-rigid reconstruction in the second stage. The first stage learns the object's deformations such that it preserves consistency in novel views. The second stage obtains high reconstruction quality by optimizing 3D Gaussians that are driven by the coarse model. To this end, we introduce a local 3D Gaussian representation, where temporally shared Gaussians are anchored in and deformed by local oriented volumes. The resulting combined model can be rendered as radiance fields, resulting in high-quality photo-realistic reconstructions of the non-rigidly deforming objects, maintaining 3D consistency across novel views. We demonstrate that NPGs achieve superior results compared to previous works, especially in challenging scenarios with few multi-view cues.
SimNP: Learning Self-Similarity Priors Between Neural Points
Sep 07, 2023Existing neural field representations for 3D object reconstruction either (1) utilize object-level representations, but suffer from low-quality details due to conditioning on a global latent code, or (2) are able to perfectly reconstruct the observations, but fail to utilize object-level prior knowledge to infer unobserved regions. We present SimNP, a method to learn category-level self-similarities, which combines the advantages of both worlds by connecting neural point radiance fields with a category-level self-similarity representation. Our contribution is two-fold. (1) We design the first neural point representation on a category level by utilizing the concept of coherent point clouds. The resulting neural point radiance fields store a high level of detail for locally supported object regions. (2) We learn how information is shared between neural points in an unconstrained and unsupervised fashion, which allows to derive unobserved regions of an object during the reconstruction process from given observations. We show that SimNP is able to outperform previous methods in reconstructing symmetric unseen object regions, surpassing methods that build upon category-level or pixel-aligned radiance fields, while providing semantic correspondences between instances
Recurrent Video Restoration Transformer with Guided Deformable Attention
Jun 05, 2022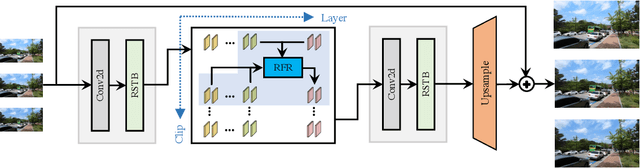
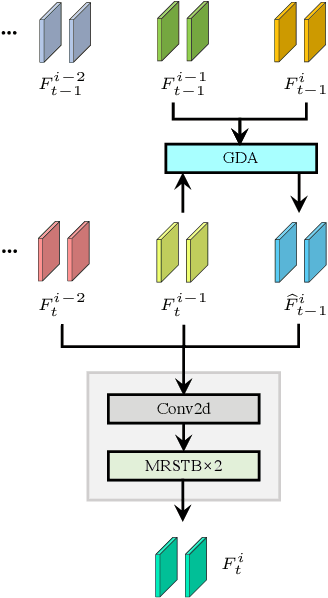
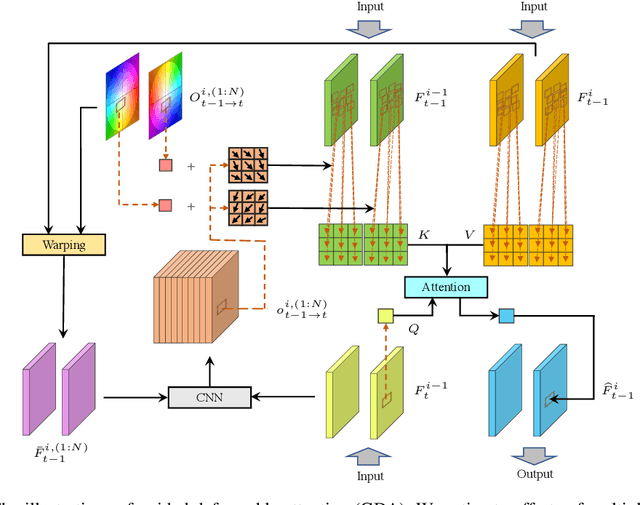
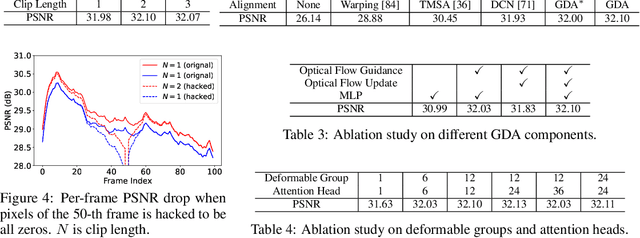
Video restoration aims at restoring multiple high-quality frames from multiple low-quality frames. Existing video restoration methods generally fall into two extreme cases, i.e., they either restore all frames in parallel or restore the video frame by frame in a recurrent way, which would result in different merits and drawbacks. Typically, the former has the advantage of temporal information fusion. However, it suffers from large model size and intensive memory consumption; the latter has a relatively small model size as it shares parameters across frames; however, it lacks long-range dependency modeling ability and parallelizability. In this paper, we attempt to integrate the advantages of the two cases by proposing a recurrent video restoration transformer, namely RVRT. RVRT processes local neighboring frames in parallel within a globally recurrent framework which can achieve a good trade-off between model size, effectiveness, and efficiency. Specifically, RVRT divides the video into multiple clips and uses the previously inferred clip feature to estimate the subsequent clip feature. Within each clip, different frame features are jointly updated with implicit feature aggregation. Across different clips, the guided deformable attention is designed for clip-to-clip alignment, which predicts multiple relevant locations from the whole inferred clip and aggregates their features by the attention mechanism. Extensive experiments on video super-resolution, deblurring, and denoising show that the proposed RVRT achieves state-of-the-art performance on benchmark datasets with balanced model size, testing memory and runtime.
ERF: Explicit Radiance Field Reconstruction From Scratch
Feb 28, 2022

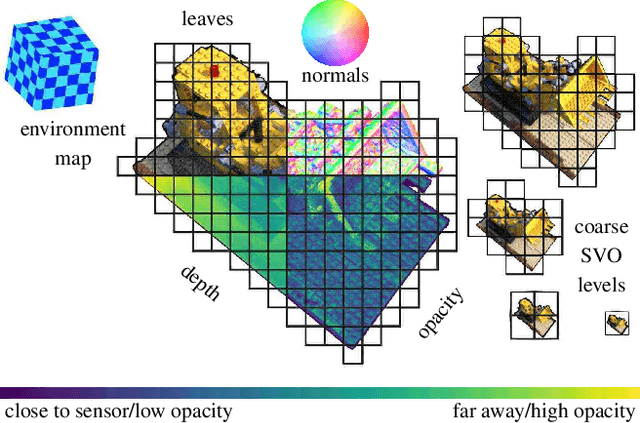
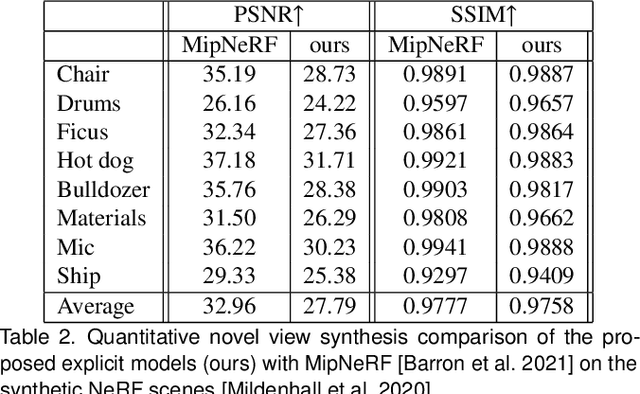
We propose a novel explicit dense 3D reconstruction approach that processes a set of images of a scene with sensor poses and calibrations and estimates a photo-real digital model. One of the key innovations is that the underlying volumetric representation is completely explicit in contrast to neural network-based (implicit) alternatives. We encode scenes explicitly using clear and understandable mappings of optimization variables to scene geometry and their outgoing surface radiance. We represent them using hierarchical volumetric fields stored in a sparse voxel octree. Robustly reconstructing such a volumetric scene model with millions of unknown variables from registered scene images only is a highly non-convex and complex optimization problem. To this end, we employ stochastic gradient descent (Adam) which is steered by an inverse differentiable renderer. We demonstrate that our method can reconstruct models of high quality that are comparable to state-of-the-art implicit methods. Importantly, we do not use a sequential reconstruction pipeline where individual steps suffer from incomplete or unreliable information from previous stages, but start our optimizations from uniformed initial solutions with scene geometry and radiance that is far off from the ground truth. We show that our method is general and practical. It does not require a highly controlled lab setup for capturing, but allows for reconstructing scenes with a vast variety of objects, including challenging ones, such as outdoor plants or furry toys. Finally, our reconstructed scene models are versatile thanks to their explicit design. They can be edited interactively which is computationally too costly for implicit alternatives.
NinjaDesc: Content-Concealing Visual Descriptors via Adversarial Learning
Dec 23, 2021
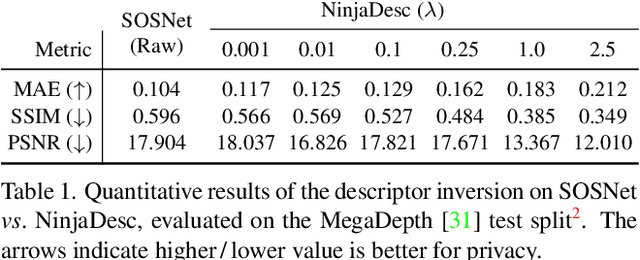
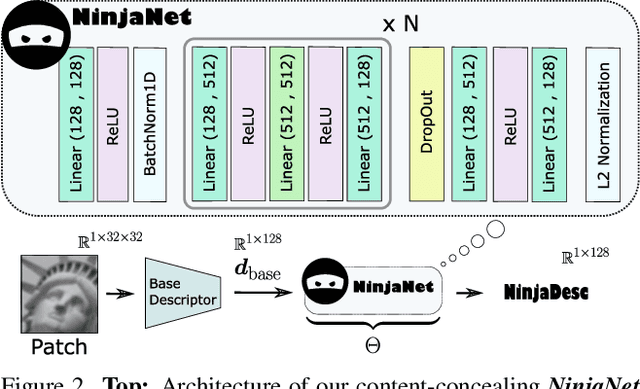
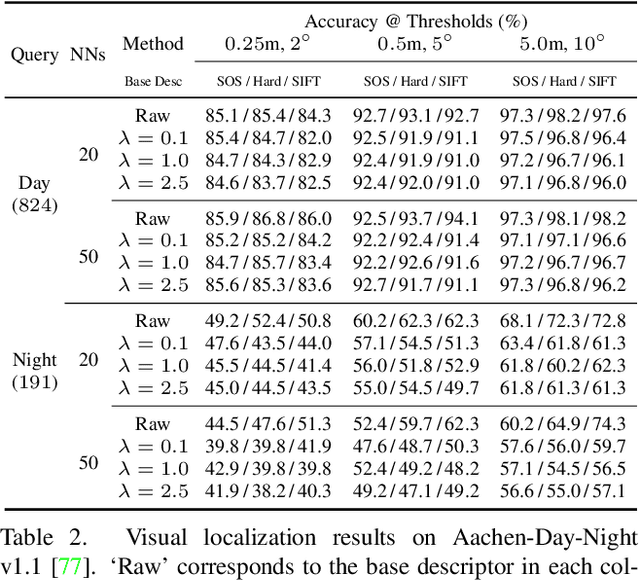
In the light of recent analyses on privacy-concerning scene revelation from visual descriptors, we develop descriptors that conceal the input image content. In particular, we propose an adversarial learning framework for training visual descriptors that prevent image reconstruction, while maintaining the matching accuracy. We let a feature encoding network and image reconstruction network compete with each other, such that the feature encoder tries to impede the image reconstruction with its generated descriptors, while the reconstructor tries to recover the input image from the descriptors. The experimental results demonstrate that the visual descriptors obtained with our method significantly deteriorate the image reconstruction quality with minimal impact on correspondence matching and camera localization performance.