 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavigating the Rashomon Effect: How Personalization Can Help Adjust Interpretable Machine Learning Models to Individual Users
May 11, 2025The Rashomon effect describes the observation that in machine learning (ML) multiple models often achieve similar predictive performance while explaining the underlying relationships in different ways. This observation holds even for intrinsically interpretable models, such as Generalized Additive Models (GAMs), which offer users valuable insights into the model's behavior. Given the existence of multiple GAM configurations with similar predictive performance, a natural question is whether we can personalize these configurations based on users' needs for interpretability. In our study, we developed an approach to personalize models based on contextual bandits. In an online experiment with 108 users in a personalized treatment and a non-personalized control group, we found that personalization led to individualized rather than one-size-fits-all configurations. Despite these individual adjustments, the interpretability remained high across both groups, with users reporting a strong understanding of the models. Our research offers initial insights into the potential for personalizing interpretable ML.
Diffusion for Out-of-Distribution Detection on Road Scenes and Beyond
Jul 22, 2024



In recent years, research on out-of-distribution (OoD) detection for semantic segmentation has mainly focused on road scenes -- a domain with a constrained amount of semantic diversity. In this work, we challenge this constraint and extend the domain of this task to general natural images. To this end, we introduce: 1. the ADE-OoD benchmark, which is based on the ADE20k dataset and includes images from diverse domains with a high semantic diversity, and 2. a novel approach that uses Diffusion score matching for OoD detection (DOoD) and is robust to the increased semantic diversity. ADE-OoD features indoor and outdoor images, defines 150 semantic categories as in-distribution, and contains a variety of OoD objects. For DOoD, we train a diffusion model with an MLP architecture on semantic in-distribution embeddings and build on the score matching interpretation to compute pixel-wise OoD scores at inference time. On common road scene OoD benchmarks, DOoD performs on par or better than the state of the art, without using outliers for training or making assumptions about the data domain. On ADE-OoD, DOoD outperforms previous approaches, but leaves much room for future improvements.
Neural Point Cloud Diffusion for Disentangled 3D Shape and Appearance Generation
Dec 21, 2023Controllable generation of 3D assets is important for many practical applications like content creation in movies, games and engineering, as well as in AR/VR. Recently, diffusion models have shown remarkable results in generation quality of 3D objects. However, none of the existing models enable disentangled generation to control the shape and appearance separately. For the first time, we present a suitable representation for 3D diffusion models to enable such disentanglement by introducing a hybrid point cloud and neural radiance field approach. We model a diffusion process over point positions jointly with a high-dimensional feature space for a local density and radiance decoder. While the point positions represent the coarse shape of the object, the point features allow modeling the geometry and appearance details. This disentanglement enables us to sample both independently and therefore to control both separately. Our approach sets a new state of the art in generation compared to previous disentanglement-capable methods by reduced FID scores of 30-90% and is on-par with other non disentanglement-capable state-of-the art methods.
SF2SE3: Clustering Scene Flow into SE-Motions via Proposal and Selection
Sep 26, 2022
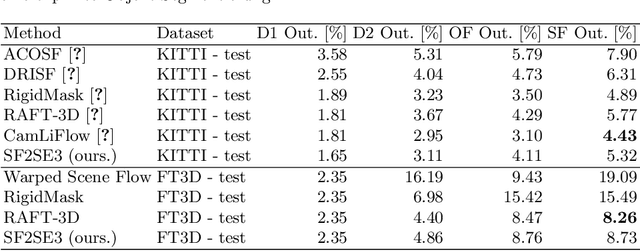

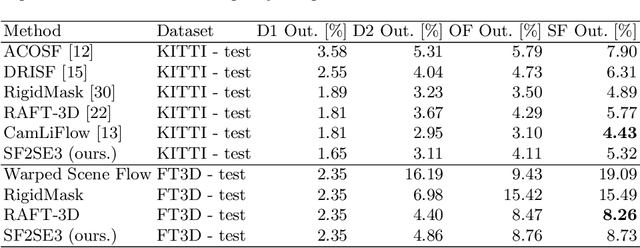
We propose SF2SE3, a novel approach to estimate scene dynamics in form of a segmentation into independently moving rigid objects and their SE(3)-motions. SF2SE3 operates on two consecutive stereo or RGB-D images. First, noisy scene flow is obtained by application of existing optical flow and depth estimation algorithms. SF2SE3 then iteratively (1) samples pixel sets to compute SE(3)-motion proposals, and (2) selects the best SE(3)-motion proposal with respect to a maximum coverage formulation. Finally, objects are formed by assigning pixels uniquely to the selected SE(3)-motions based on consistency with the input scene flow and spatial proximity. The main novelties are a more informed strategy for the sampling of motion proposals and a maximum coverage formulation for the proposal selection. We conduct evaluations on multiple datasets regarding application of SF2SE3 for scene flow estimation, object segmentation and visual odometry. SF2SE3 performs on par with the state of the art for scene flow estimation and is more accurate for segmentation and odometry.
A Benchmark and a Baseline for Robust Multi-view Depth Estimation
Sep 13, 2022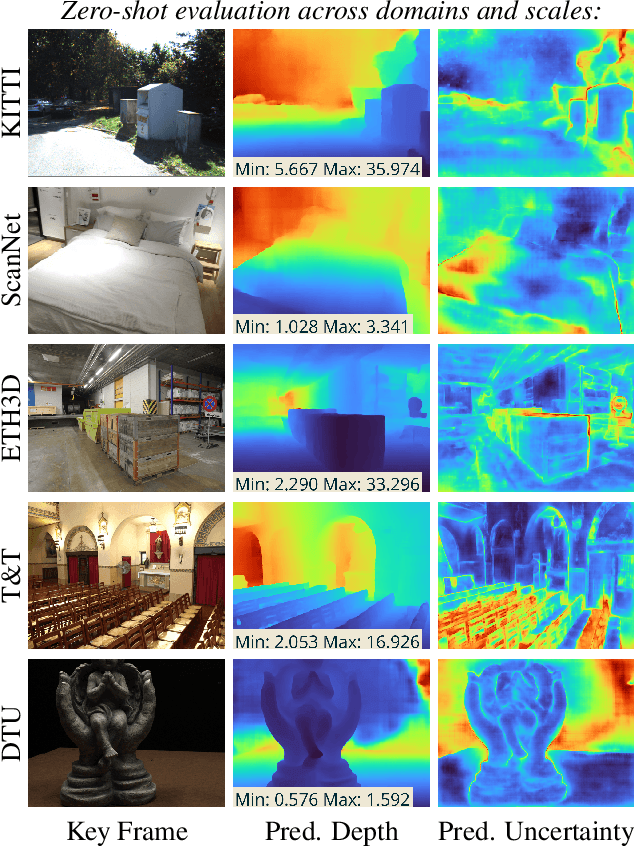
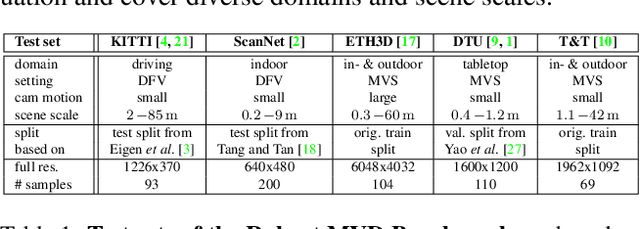
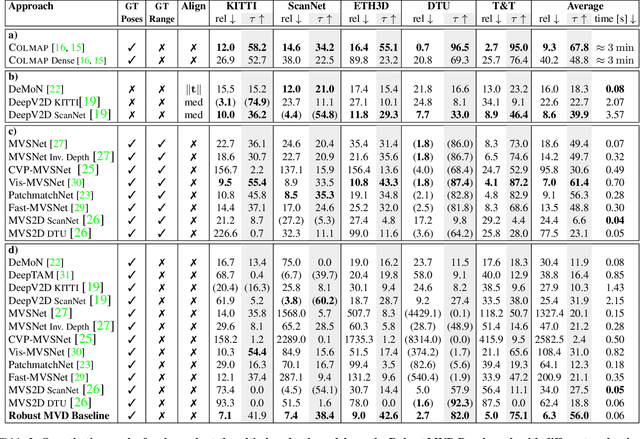
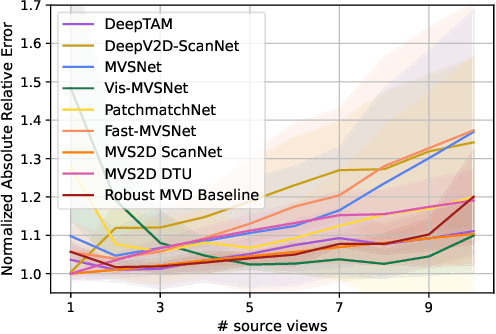
Recent deep learning approaches for multi-view depth estimation are employed either in a depth-from-video or a multi-view stereo setting. Despite different settings, these approaches are technically similar: they correlate multiple source views with a keyview to estimate a depth map for the keyview. In this work, we introduce the Robust Multi-View Depth Benchmark that is built upon a set of public datasets and allows evaluation in both settings on data from different domains. We evaluate recent approaches and find imbalanced performances across domains. Further, we consider a third setting, where camera poses are available and the objective is to estimate the corresponding depth maps with their correct scale. We show that recent approaches do not generalize across datasets in this setting. This is because their cost volume output runs out of distribution. To resolve this, we present the Robust MVD Baseline model for multi-view depth estimation, which is built upon existing components but employs a novel scale augmentation procedure. It can be applied for robust multi-view depth estimation, independent of the target data. We provide code for the proposed benchmark and baseline model at https://github.com/lmb-freiburg/robustmvd.
Semi-Supervised Disparity Estimation with Deep Feature Reconstruction
Jun 01, 2021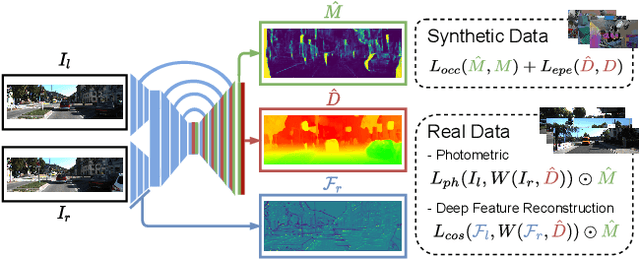
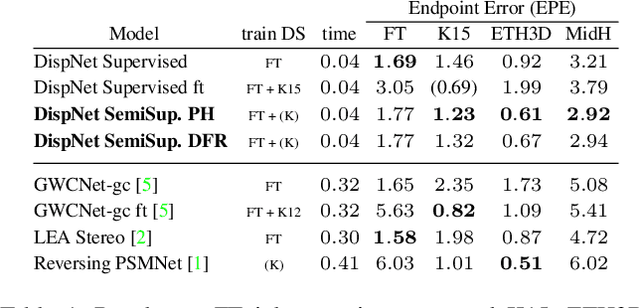

Despite the success of deep learning in disparity estimation, the domain generalization gap remains an issue. We propose a semi-supervised pipeline that successfully adapts DispNet to a real-world domain by joint supervised training on labeled synthetic data and self-supervised training on unlabeled real data. Furthermore, accounting for the limitations of the widely-used photometric loss, we analyze the impact of deep feature reconstruction as a promising supervisory signal for disparity estimation.