 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMathChat: Benchmarking Mathematical Reasoning and Instruction Following in Multi-Turn Interactions
May 29, 2024



Large language models (LLMs) have demonstrated impressive capabilities in mathematical problem solving, particularly in single turn question answering formats. However, real world scenarios often involve mathematical question answering that requires multi turn or interactive information exchanges, and the performance of LLMs on these tasks is still underexplored. This paper introduces MathChat, a comprehensive benchmark specifically designed to evaluate LLMs across a broader spectrum of mathematical tasks. These tasks are structured to assess the models' abilities in multiturn interactions and open ended generation. We evaluate the performance of various SOTA LLMs on the MathChat benchmark, and we observe that while these models excel in single turn question answering, they significantly underperform in more complex scenarios that require sustained reasoning and dialogue understanding. To address the above limitations of existing LLMs when faced with multiturn and open ended tasks, we develop MathChat sync, a synthetic dialogue based math dataset for LLM finetuning, focusing on improving models' interaction and instruction following capabilities in conversations. Experimental results emphasize the need for training LLMs with diverse, conversational instruction tuning datasets like MathChatsync. We believe this work outlines one promising direction for improving the multiturn mathematical reasoning abilities of LLMs, thus pushing forward the development of LLMs that are more adept at interactive mathematical problem solving and real world applications.
Toward Self-Improvement of LLMs via Imagination, Searching, and Criticizing
Apr 18, 2024



Despite the impressive capabilities of Large Language Models (LLMs) on various tasks, they still struggle with scenarios that involves complex reasoning and planning. Recent work proposed advanced prompting techniques and the necessity of fine-tuning with high-quality data to augment LLMs' reasoning abilities. However, these approaches are inherently constrained by data availability and quality. In light of this, self-correction and self-learning emerge as viable solutions, employing strategies that allow LLMs to refine their outputs and learn from self-assessed rewards. Yet, the efficacy of LLMs in self-refining its response, particularly in complex reasoning and planning task, remains dubious. In this paper, we introduce AlphaLLM for the self-improvements of LLMs, which integrates Monte Carlo Tree Search (MCTS) with LLMs to establish a self-improving loop, thereby enhancing the capabilities of LLMs without additional annotations. Drawing inspiration from the success of AlphaGo, AlphaLLM addresses the unique challenges of combining MCTS with LLM for self-improvement, including data scarcity, the vastness search spaces of language tasks, and the subjective nature of feedback in language tasks. AlphaLLM is comprised of prompt synthesis component, an efficient MCTS approach tailored for language tasks, and a trio of critic models for precise feedback. Our experimental results in mathematical reasoning tasks demonstrate that AlphaLLM significantly enhances the performance of LLMs without additional annotations, showing the potential for self-improvement in LLMs.
Entropy Guided Extrapolative Decoding to Improve Factuality in Large Language Models
Apr 14, 2024



Large language models (LLMs) exhibit impressive natural language capabilities but suffer from hallucination -- generating content ungrounded in the realities of training data. Recent work has focused on decoding techniques to improve factuality during inference by leveraging LLMs' hierarchical representation of factual knowledge, manipulating the predicted distributions at inference time. Current state-of-the-art approaches refine decoding by contrasting early-exit distributions from a lower layer with the final layer to exploit information related to factuality within the model forward procedure. However, such methods often assume the final layer is the most reliable and the lower layer selection process depends on it. In this work, we first propose extrapolation of critical token probabilities beyond the last layer for more accurate contrasting. We additionally employ layer-wise entropy-guided lower layer selection, decoupling the selection process from the final layer. Experiments demonstrate strong performance - surpassing state-of-the-art on multiple different datasets by large margins. Analyses show different kinds of prompts respond to different selection strategies.
Polarity Calibration for Opinion Summarization
Apr 02, 2024



Opinion summarization is automatically generating summaries from a variety of subjective information, such as product reviews or political opinions. The challenge of opinions summarization lies in presenting divergent or even conflicting opinions. We conduct an analysis of previous summarization models, which reveals their inclination to amplify the polarity bias, emphasizing the majority opinions while ignoring the minority opinions. To address this issue and make the summarizer express both sides of opinions, we introduce the concept of polarity calibration, which aims to align the polarity of output summary with that of input text. Specifically, we develop a reinforcement training approach for polarity calibration. This approach feeds the polarity distance between output summary and input text as reward into the summarizer, and also balance polarity calibration with content preservation and language naturality. We evaluate our Polarity Calibration model (PoCa) on two types of opinions summarization tasks: summarizing product reviews and political opinions articles. Automatic and human evaluation demonstrate that our approach can mitigate the polarity mismatch between output summary and input text, as well as maintain the content semantic and language quality.
Conceptual and Unbiased Reasoning in Language Models
Mar 30, 2024Conceptual reasoning, the ability to reason in abstract and high-level perspectives, is key to generalization in human cognition. However, limited study has been done on large language models' capability to perform conceptual reasoning. In this work, we bridge this gap and propose a novel conceptualization framework that forces models to perform conceptual reasoning on abstract questions and generate solutions in a verifiable symbolic space. Using this framework as an analytical tool, we show that existing large language models fall short on conceptual reasoning, dropping 9% to 28% on various benchmarks compared to direct inference methods. We then discuss how models can improve since high-level abstract reasoning is key to unbiased and generalizable decision-making. We propose two techniques to add trustworthy induction signals by generating familiar questions with similar underlying reasoning paths and asking models to perform self-refinement. Experiments show that our proposed techniques improve models' conceptual reasoning performance by 8% to 11%, achieving a more robust reasoning system that relies less on inductive biases.
Self-Consistency Boosts Calibration for Math Reasoning
Mar 14, 2024Calibration, which establishes the correlation between accuracy and model confidence, is important for LLM development. We design three off-the-shelf calibration methods based on self-consistency (Wang et al., 2022) for math reasoning tasks. Evaluation on two popular benchmarks (GSM8K and MathQA) using strong open-source LLMs (Mistral and LLaMA2), our methods better bridge model confidence and accuracy than existing methods based on p(True) (Kadavath et al., 2022) or logit (Kadavath et al., 2022).
A Knowledge Plug-and-Play Test Bed for Open-domain Dialogue Generation
Mar 06, 2024



Knowledge-based, open-domain dialogue generation aims to build chit-chat systems that talk to humans using mined support knowledge. Many types and sources of knowledge have previously been shown to be useful as support knowledge. Even in the era of large language models, response generation grounded in knowledge retrieved from additional up-to-date sources remains a practically important approach. While prior work using single-source knowledge has shown a clear positive correlation between the performances of knowledge selection and response generation, there are no existing multi-source datasets for evaluating support knowledge retrieval. Further, prior work has assumed that the knowledge sources available at test time are the same as during training. This unrealistic assumption unnecessarily handicaps models, as new knowledge sources can become available after a model is trained. In this paper, we present a high-quality benchmark named multi-source Wizard of Wikipedia (Ms.WoW) for evaluating multi-source dialogue knowledge selection and response generation. Unlike existing datasets, it contains clean support knowledge, grounded at the utterance level and partitioned into multiple knowledge sources. We further propose a new challenge, dialogue knowledge plug-and-play, which aims to test an already trained dialogue model on using new support knowledge from previously unseen sources in a zero-shot fashion.
Can Large Language Models do Analytical Reasoning?
Mar 06, 2024

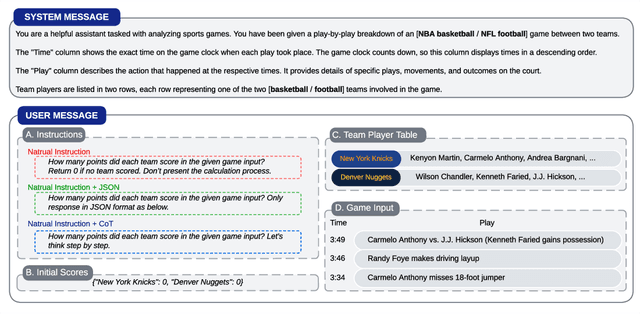
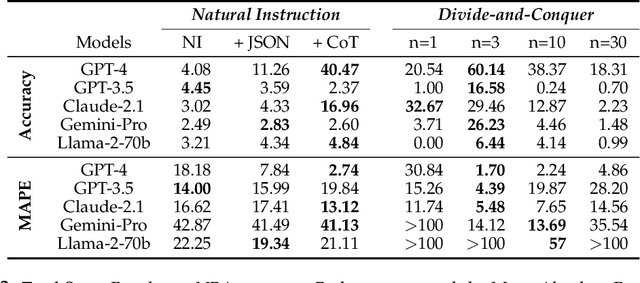
This paper explores the cutting-edge Large Language Model with analytical reasoning on sports. Our analytical reasoning embodies the tasks of letting large language models count how many points each team scores in a quarter in the NBA and NFL games. Our major discoveries are in two folds. Firstly, we find among all the models we employed, GPT-4 stands out in effectiveness, followed by Claude-2.1, with GPT-3.5, Gemini-Pro, and Llama-2-70b lagging behind. Specifically, we compare three different prompting techniques and a divide-and-conquer approach, we find that the latter was the most effective. Our divide-and-conquer approach breaks down play-by-play data into smaller, more manageable segments, solves each piece individually, and then aggregates them together. Besides the divide-and-conquer approach, we also explore the Chain of Thought (CoT) strategy, which markedly improves outcomes for certain models, notably GPT-4 and Claude-2.1, with their accuracy rates increasing significantly. However, the CoT strategy has negligible or even detrimental effects on the performance of other models like GPT-3.5 and Gemini-Pro. Secondly, to our surprise, we observe that most models, including GPT-4, struggle to accurately count the total scores for NBA quarters despite showing strong performance in counting NFL quarter scores. This leads us to further investigate the factors that impact the complexity of analytical reasoning tasks with extensive experiments, through which we conclude that task complexity depends on the length of context, the information density, and the presence of related information. Our research provides valuable insights into the complexity of analytical reasoning tasks and potential directions for developing future large language models.
Collaborative decoding of critical tokens for boosting factuality of large language models
Feb 28, 2024The most common training pipeline for large language models includes pretraining, finetuning and aligning phases, with their respective resulting models, such as the pretrained model and the finetuned model. Finetuned and aligned models show improved abilities of instruction following and safe generation, however their abilities to stay factual about the world are impacted by the finetuning process. Furthermore, the common practice of using sampling during generation also increases chances of hallucination. In this work, we introduce a collaborative decoding framework to harness the high factuality within pretrained models through the concept of critical tokens. We first design a critical token classifier to decide which model to use for the next token, and subsequently generates the next token using different decoding strategies. Experiments with different models and datasets show that our decoding framework is able to reduce model hallucination significantly, showcasing the importance of the collaborative decoding framework.
Fact-and-Reflection (FaR) Improves Confidence Calibration of Large Language Models
Feb 27, 2024For a LLM to be trustworthy, its confidence level should be well-calibrated with its actual performance. While it is now common sense that LLM performances are greatly impacted by prompts, the confidence calibration in prompting LLMs has yet to be thoroughly explored. In this paper, we explore how different prompting strategies influence LLM confidence calibration and how it could be improved. We conduct extensive experiments on six prompting methods in the question-answering context and we observe that, while these methods help improve the expected LLM calibration, they also trigger LLMs to be over-confident when responding to some instances. Inspired by human cognition, we propose Fact-and-Reflection (FaR) prompting, which improves the LLM calibration in two steps. First, FaR elicits the known "facts" that are relevant to the input prompt from the LLM. And then it asks the model to "reflect" over them to generate the final answer. Experiments show that FaR prompting achieves significantly better calibration; it lowers the Expected Calibration Error by 23.5% on our multi-purpose QA tasks. Notably, FaR prompting even elicits the capability of verbally expressing concerns in less confident scenarios, which helps trigger retrieval augmentation for solving these harder instances.