 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVCVTS: Multi-speaker Video-to-Speech synthesis via cross-modal knowledge transfer from voice conversion
Paper and Code
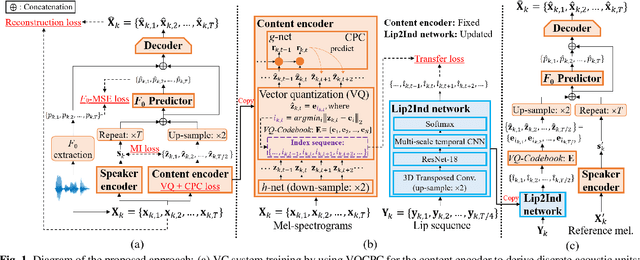
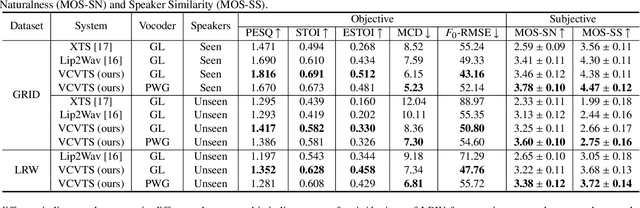
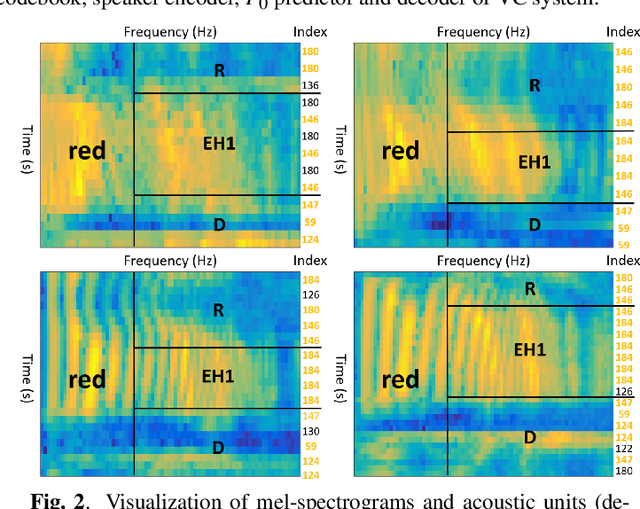
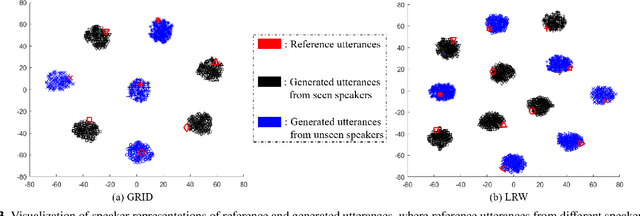
Though significant progress has been made for speaker-dependent Video-to-Speech (VTS) synthesis, little attention is devoted to multi-speaker VTS that can map silent video to speech, while allowing flexible control of speaker identity, all in a single system. This paper proposes a novel multi-speaker VTS system based on cross-modal knowledge transfer from voice conversion (VC), where vector quantization with contrastive predictive coding (VQCPC) is used for the content encoder of VC to derive discrete phoneme-like acoustic units, which are transferred to a Lip-to-Index (Lip2Ind) network to infer the index sequence of acoustic units. The Lip2Ind network can then substitute the content encoder of VC to form a multi-speaker VTS system to convert silent video to acoustic units for reconstructing accurate spoken content. The VTS system also inherits the advantages of VC by using a speaker encoder to produce speaker representations to effectively control the speaker identity of generated speech. Extensive evaluations verify the effectiveness of proposed approach, which can be applied in both constrained vocabulary and open vocabulary conditions, achieving state-of-the-art performance in generating high-quality speech with high naturalness, intelligibility and speaker similarity. Our demo page is released here: https://wendison.github.io/VCVTS-demo/