 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeRAG: BOOSTING LLM Time Series Forecasting via Retrieval-Augmented Generation
Dec 21, 2024


Although the rise of large language models (LLMs) has introduced new opportunities for time series forecasting, existing LLM-based solutions require excessive training and exhibit limited transferability. In view of these challenges, we propose TimeRAG, a framework that incorporates Retrieval-Augmented Generation (RAG) into time series forecasting LLMs, which constructs a time series knowledge base from historical sequences, retrieves reference sequences from the knowledge base that exhibit similar patterns to the query sequence measured by Dynamic Time Warping (DTW), and combines these reference sequences and the prediction query as a textual prompt to the time series forecasting LLM. Experiments on datasets from various domains show that the integration of RAG improved the prediction accuracy of the original model by 2.97% on average.
Towards Generalist Robot Policies: What Matters in Building Vision-Language-Action Models
Dec 18, 2024
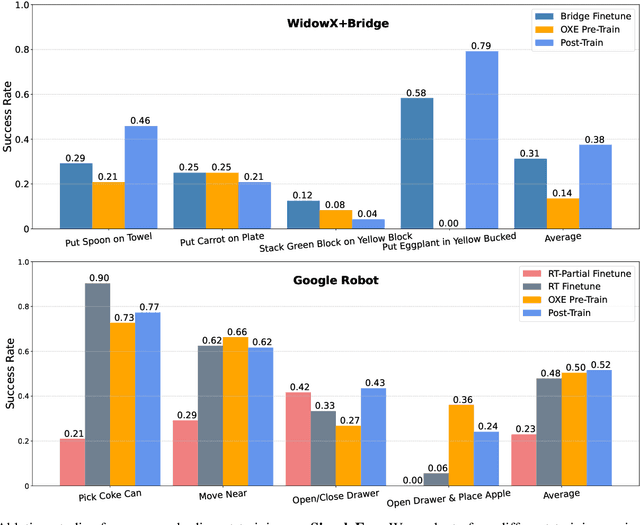

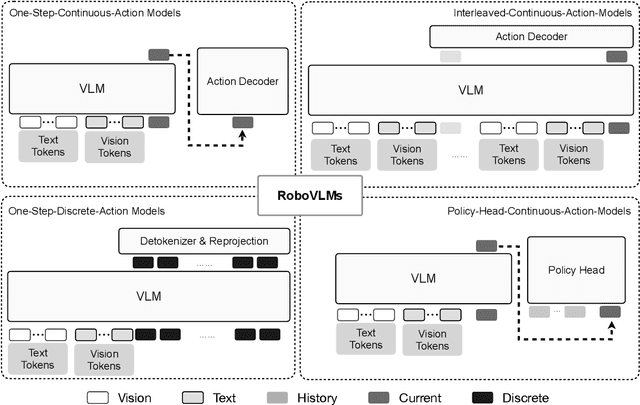
Foundation Vision Language Models (VLMs) exhibit strong capabilities in multi-modal representation learning, comprehension, and reasoning. By injecting action components into the VLMs, Vision-Language-Action Models (VLAs) can be naturally formed and also show promising performance. Existing work has demonstrated the effectiveness and generalization of VLAs in multiple scenarios and tasks. Nevertheless, the transfer from VLMs to VLAs is not trivial since existing VLAs differ in their backbones, action-prediction formulations, data distributions, and training recipes. This leads to a missing piece for a systematic understanding of the design choices of VLAs. In this work, we disclose the key factors that significantly influence the performance of VLA and focus on answering three essential design choices: which backbone to select, how to formulate the VLA architectures, and when to add cross-embodiment data. The obtained results convince us firmly to explain why we need VLA and develop a new family of VLAs, RoboVLMs, which require very few manual designs and achieve a new state-of-the-art performance in three simulation tasks and real-world experiments. Through our extensive experiments, which include over 8 VLM backbones, 4 policy architectures, and over 600 distinct designed experiments, we provide a detailed guidebook for the future design of VLAs. In addition to the study, the highly flexible RoboVLMs framework, which supports easy integrations of new VLMs and free combinations of various design choices, is made public to facilitate future research. We open-source all details, including codes, models, datasets, and toolkits, along with detailed training and evaluation recipes at: robovlms.github.io.
SIDE: Socially Informed Drought Estimation Toward Understanding Societal Impact Dynamics of Environmental Crisis
Dec 17, 2024



Drought has become a critical global threat with significant societal impact. Existing drought monitoring solutions primarily focus on assessing drought severity using quantitative measurements, overlooking the diverse societal impact of drought from human-centric perspectives. Motivated by the collective intelligence on social media and the computational power of AI, this paper studies a novel problem of socially informed AI-driven drought estimation that aims to leverage social and news media information to jointly estimate drought severity and its societal impact. Two technical challenges exist: 1) How to model the implicit temporal dynamics of drought societal impact. 2) How to capture the social-physical interdependence between the physical drought condition and its societal impact. To address these challenges, we develop SIDE, a socially informed AI-driven drought estimation framework that explicitly quantifies the societal impact of drought and effectively models the social-physical interdependency for joint severity-impact estimation. Experiments on real-world datasets from California and Texas demonstrate SIDE's superior performance compared to state-of-the-art baselines in accurately estimating drought severity and its societal impact. SIDE offers valuable insights for developing human-centric drought mitigation strategies to foster sustainable and resilient communities.
Exploring Enhanced Contextual Information for Video-Level Object Tracking
Dec 15, 2024



Contextual information at the video level has become increasingly crucial for visual object tracking. However, existing methods typically use only a few tokens to convey this information, which can lead to information loss and limit their ability to fully capture the context. To address this issue, we propose a new video-level visual object tracking framework called MCITrack. It leverages Mamba's hidden states to continuously record and transmit extensive contextual information throughout the video stream, resulting in more robust object tracking. The core component of MCITrack is the Contextual Information Fusion module, which consists of the mamba layer and the cross-attention layer. The mamba layer stores historical contextual information, while the cross-attention layer integrates this information into the current visual features of each backbone block. This module enhances the model's ability to capture and utilize contextual information at multiple levels through deep integration with the backbone. Experiments demonstrate that MCITrack achieves competitive performance across numerous benchmarks. For instance, it gets 76.6% AUC on LaSOT and 80.0% AO on GOT-10k, establishing a new state-of-the-art performance. Code and models are available at https://github.com/kangben258/MCITrack.
Controlling the Latent Diffusion Model for Generative Image Shadow Removal via Residual Generation
Dec 03, 2024Large-scale generative models have achieved remarkable advancements in various visual tasks, yet their application to shadow removal in images remains challenging. These models often generate diverse, realistic details without adequate focus on fidelity, failing to meet the crucial requirements of shadow removal, which necessitates precise preservation of image content. In contrast to prior approaches that aimed to regenerate shadow-free images from scratch, this paper utilizes diffusion models to generate and refine image residuals. This strategy fully uses the inherent detailed information within shadowed images, resulting in a more efficient and faithful reconstruction of shadow-free content. Additionally, to revent the accumulation of errors during the generation process, a crosstimestep self-enhancement training strategy is proposed. This strategy leverages the network itself to augment the training data, not only increasing the volume of data but also enabling the network to dynamically correct its generation trajectory, ensuring a more accurate and robust output. In addition, to address the loss of original details in the process of image encoding and decoding of large generative models, a content-preserved encoder-decoder structure is designed with a control mechanism and multi-scale skip connections to achieve high-fidelity shadow-free image reconstruction. Experimental results demonstrate that the proposed method can reproduce high-quality results based on a large latent diffusion prior and faithfully preserve the original contents in shadow regions.
ContextGNN: Beyond Two-Tower Recommendation Systems
Nov 29, 2024



Recommendation systems predominantly utilize two-tower architectures, which evaluate user-item rankings through the inner product of their respective embeddings. However, one key limitation of two-tower models is that they learn a pair-agnostic representation of users and items. In contrast, pair-wise representations either scale poorly due to their quadratic complexity or are too restrictive on the candidate pairs to rank. To address these issues, we introduce Context-based Graph Neural Networks (ContextGNNs), a novel deep learning architecture for link prediction in recommendation systems. The method employs a pair-wise representation technique for familiar items situated within a user's local subgraph, while leveraging two-tower representations to facilitate the recommendation of exploratory items. A final network then predicts how to fuse both pair-wise and two-tower recommendations into a single ranking of items. We demonstrate that ContextGNN is able to adapt to different data characteristics and outperforms existing methods, both traditional and GNN-based, on a diverse set of practical recommendation tasks, improving performance by 20% on average.
Open-Vocabulary Octree-Graph for 3D Scene Understanding
Nov 25, 2024



Open-vocabulary 3D scene understanding is indispensable for embodied agents. Recent works leverage pretrained vision-language models (VLMs) for object segmentation and project them to point clouds to build 3D maps. Despite progress, a point cloud is a set of unordered coordinates that requires substantial storage space and does not directly convey occupancy information or spatial relation, making existing methods inefficient for downstream tasks, e.g., path planning and complex text-based object retrieval. To address these issues, we propose Octree-Graph, a novel scene representation for open-vocabulary 3D scene understanding. Specifically, a Chronological Group-wise Segment Merging (CGSM) strategy and an Instance Feature Aggregation (IFA) algorithm are first designed to get 3D instances and corresponding semantic features. Subsequently, an adaptive-octree structure is developed that stores semantics and depicts the occupancy of an object adjustably according to its shape. Finally, the Octree-Graph is constructed where each adaptive-octree acts as a graph node, and edges describe the spatial relations among nodes. Extensive experiments on various tasks are conducted on several widely-used datasets, demonstrating the versatility and effectiveness of our method.
Improving Transferable Targeted Attacks with Feature Tuning Mixup
Nov 23, 2024



Deep neural networks exhibit vulnerability to adversarial examples that can transfer across different models. A particularly challenging problem is developing transferable targeted attacks that can mislead models into predicting specific target classes. While various methods have been proposed to enhance attack transferability, they often incur substantial computational costs while yielding limited improvements. Recent clean feature mixup methods use random clean features to perturb the feature space but lack optimization for disrupting adversarial examples, overlooking the advantages of attack-specific perturbations. In this paper, we propose Feature Tuning Mixup (FTM), a novel method that enhances targeted attack transferability by combining both random and optimized noises in the feature space. FTM introduces learnable feature perturbations and employs an efficient stochastic update strategy for optimization. These learnable perturbations facilitate the generation of more robust adversarial examples with improved transferability. We further demonstrate that attack performance can be enhanced through an ensemble of multiple FTM-perturbed surrogate models. Extensive experiments on the ImageNet-compatible dataset across various models demonstrate that our method achieves significant improvements over state-of-the-art methods while maintaining low computational cost.
Night-to-Day Translation via Illumination Degradation Disentanglement
Nov 21, 2024
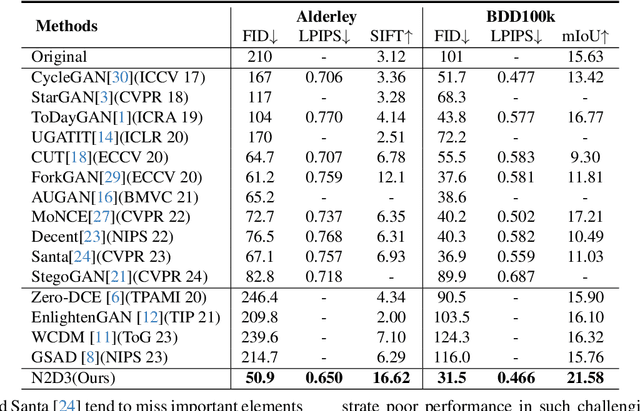

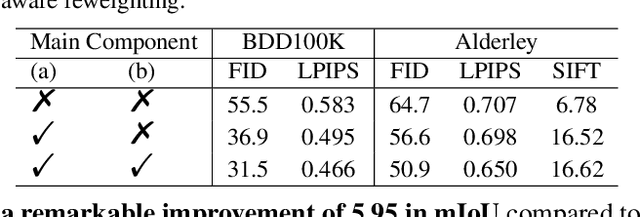
Night-to-Day translation (Night2Day) aims to achieve day-like vision for nighttime scenes. However, processing night images with complex degradations remains a significant challenge under unpaired conditions. Previous methods that uniformly mitigate these degradations have proven inadequate in simultaneously restoring daytime domain information and preserving underlying semantics. In this paper, we propose \textbf{N2D3} (\textbf{N}ight-to-\textbf{D}ay via \textbf{D}egradation \textbf{D}isentanglement) to identify different degradation patterns in nighttime images. Specifically, our method comprises a degradation disentanglement module and a degradation-aware contrastive learning module. Firstly, we extract physical priors from a photometric model based on Kubelka-Munk theory. Then, guided by these physical priors, we design a disentanglement module to discriminate among different illumination degradation regions. Finally, we introduce the degradation-aware contrastive learning strategy to preserve semantic consistency across distinct degradation regions. Our method is evaluated on two public datasets, demonstrating a significant improvement in visual quality and considerable potential for benefiting downstream tasks.
Zero-shot Dynamic MRI Reconstruction with Global-to-local Diffusion Model
Nov 06, 2024



Diffusion models have recently demonstrated considerable advancement in the generation and reconstruction of magnetic resonance imaging (MRI) data. These models exhibit great potential in handling unsampled data and reducing noise, highlighting their promise as generative models. However, their application in dynamic MRI remains relatively underexplored. This is primarily due to the substantial amount of fully-sampled data typically required for training, which is difficult to obtain in dynamic MRI due to its spatio-temporal complexity and high acquisition costs. To address this challenge, we propose a dynamic MRI reconstruction method based on a time-interleaved acquisition scheme, termed the Glob-al-to-local Diffusion Model. Specifically, fully encoded full-resolution reference data are constructed by merging under-sampled k-space data from adjacent time frames, generating two distinct bulk training datasets for global and local models. The global-to-local diffusion framework alternately optimizes global information and local image details, enabling zero-shot reconstruction. Extensive experiments demonstrate that the proposed method performs well in terms of noise reduction and detail preservation, achieving reconstruction quality comparable to that of supervised approaches.