 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGP-NeRF: Generalized Perception NeRF for Context-Aware 3D Scene Understanding
Nov 20, 2023



Applying NeRF to downstream perception tasks for scene understanding and representation is becoming increasingly popular. Most existing methods treat semantic prediction as an additional rendering task, \textit{i.e.}, the "label rendering" task, to build semantic NeRFs. However, by rendering semantic/instance labels per pixel without considering the contextual information of the rendered image, these methods usually suffer from unclear boundary segmentation and abnormal segmentation of pixels within an object. To solve this problem, we propose Generalized Perception NeRF (GP-NeRF), a novel pipeline that makes the widely used segmentation model and NeRF work compatibly under a unified framework, for facilitating context-aware 3D scene perception. To accomplish this goal, we introduce transformers to aggregate radiance as well as semantic embedding fields jointly for novel views and facilitate the joint volumetric rendering of both fields. In addition, we propose two self-distillation mechanisms, i.e., the Semantic Distill Loss and the Depth-Guided Semantic Distill Loss, to enhance the discrimination and quality of the semantic field and the maintenance of geometric consistency. In evaluation, we conduct experimental comparisons under two perception tasks (\textit{i.e.} semantic and instance segmentation) using both synthetic and real-world datasets. Notably, our method outperforms SOTA approaches by 6.94\%, 11.76\%, and 8.47\% on generalized semantic segmentation, finetuning semantic segmentation, and instance segmentation, respectively.
SegGPT Meets Co-Saliency Scene
May 08, 2023


Co-salient object detection targets at detecting co-existed salient objects among a group of images. Recently, a generalist model for segmenting everything in context, called SegGPT, is gaining public attention. In view of its breakthrough for segmentation, we can hardly wait to probe into its contribution to the task of co-salient object detection. In this report, we first design a framework to enable SegGPT for the problem of co-salient object detection. Proceed to the next step, we evaluate the performance of SegGPT on the problem of co-salient object detection on three available datasets. We achieve a finding that co-saliency scenes challenges SegGPT due to context discrepancy within a group of co-saliency images.
Mitigating Undisciplined Over-Smoothing in Transformer for Weakly Supervised Semantic Segmentation
May 04, 2023A surge of interest has emerged in weakly supervised semantic segmentation due to its remarkable efficiency in recent years. Existing approaches based on transformers mainly focus on exploring the affinity matrix to boost CAMs with global relationships. While in this work, we first perform a scrupulous examination towards the impact of successive affinity matrices and discover that they possess an inclination toward sparsification as the network approaches convergence, hence disclosing a manifestation of over-smoothing. Besides, it has been observed that enhanced attention maps tend to evince a substantial amount of extraneous background noise in deeper layers. Drawing upon this, we posit a daring conjecture that the undisciplined over-smoothing phenomenon introduces a noteworthy quantity of semantically irrelevant background noise, causing performance degradation. To alleviate this issue, we propose a novel perspective that highlights the objects of interest by investigating the regions of the trait, thereby fostering an extensive comprehension of the successive affinity matrix. Consequently, we suggest an adaptive re-activation mechanism (AReAM) that alleviates the issue of incomplete attention within the object and the unbounded background noise. AReAM accomplishes this by supervising high-level attention with shallow affinity matrices, yielding promising results. Exhaustive experiments conducted on the commonly used dataset manifest that segmentation results can be greatly improved through our proposed AReAM, which imposes restrictions on each affinity matrix in deep layers to make it attentive to semantic regions.
Revisiting Long-tailed Image Classification: Survey and Benchmarks with New Evaluation Metrics
Feb 03, 2023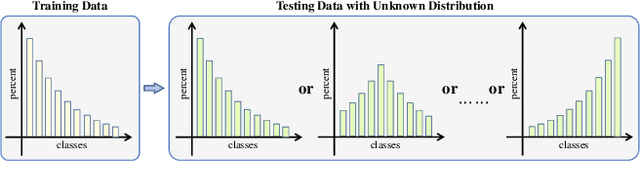
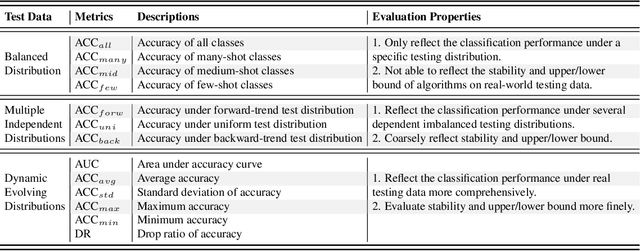
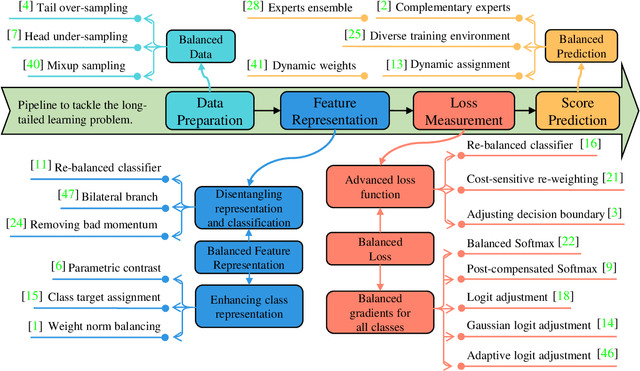
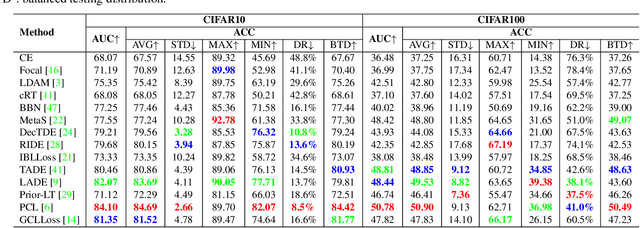
Recently, long-tailed image classification harvests lots of research attention, since the data distribution is long-tailed in many real-world situations. Piles of algorithms are devised to address the data imbalance problem by biasing the training process towards less frequent classes. However, they usually evaluate the performance on a balanced testing set or multiple independent testing sets having distinct distributions with the training data. Considering the testing data may have arbitrary distributions, existing evaluation strategies are unable to reflect the actual classification performance objectively. We set up novel evaluation benchmarks based on a series of testing sets with evolving distributions. A corpus of metrics are designed for measuring the accuracy, robustness, and bounds of algorithms for learning with long-tailed distribution. Based on our benchmarks, we re-evaluate the performance of existing methods on CIFAR10 and CIFAR100 datasets, which is valuable for guiding the selection of data rebalancing techniques. We also revisit existing methods and categorize them into four types including data balancing, feature balancing, loss balancing, and prediction balancing, according the focused procedure during the training pipeline.
Boosting Low-Data Instance Segmentation by Unsupervised Pre-training with Saliency Prompt
Feb 02, 2023



Recently, inspired by DETR variants, query-based end-to-end instance segmentation (QEIS) methods have outperformed CNN-based models on large-scale datasets. Yet they would lose efficacy when only a small amount of training data is available since it's hard for the crucial queries/kernels to learn localization and shape priors. To this end, this work offers a novel unsupervised pre-training solution for low-data regimes. Inspired by the recent success of the Prompting technique, we introduce a new pre-training method that boosts QEIS models by giving Saliency Prompt for queries/kernels. Our method contains three parts: 1) Saliency Masks Proposal is responsible for generating pseudo masks from unlabeled images based on the saliency mechanism. 2) Prompt-Kernel Matching transfers pseudo masks into prompts and injects the corresponding localization and shape priors to the best-matched kernels. 3) Kernel Supervision is applied to supply supervision at the kernel level for robust learning. From a practical perspective, our pre-training method helps QEIS models achieve a similar convergence speed and comparable performance with CNN-based models in low-data regimes. Experimental results show that our method significantly boosts several QEIS models on three datasets. Code will be made available.
Compound Batch Normalization for Long-tailed Image Classification
Dec 02, 2022



Significant progress has been made in learning image classification neural networks under long-tail data distribution using robust training algorithms such as data re-sampling, re-weighting, and margin adjustment. Those methods, however, ignore the impact of data imbalance on feature normalization. The dominance of majority classes (head classes) in estimating statistics and affine parameters causes internal covariate shifts within less-frequent categories to be overlooked. To alleviate this challenge, we propose a compound batch normalization method based on a Gaussian mixture. It can model the feature space more comprehensively and reduce the dominance of head classes. In addition, a moving average-based expectation maximization (EM) algorithm is employed to estimate the statistical parameters of multiple Gaussian distributions. However, the EM algorithm is sensitive to initialization and can easily become stuck in local minima where the multiple Gaussian components continue to focus on majority classes. To tackle this issue, we developed a dual-path learning framework that employs class-aware split feature normalization to diversify the estimated Gaussian distributions, allowing the Gaussian components to fit with training samples of less-frequent classes more comprehensively. Extensive experiments on commonly used datasets demonstrated that the proposed method outperforms existing methods on long-tailed image classification.
Deep 3D Vessel Segmentation based on Cross Transformer Network
Aug 23, 2022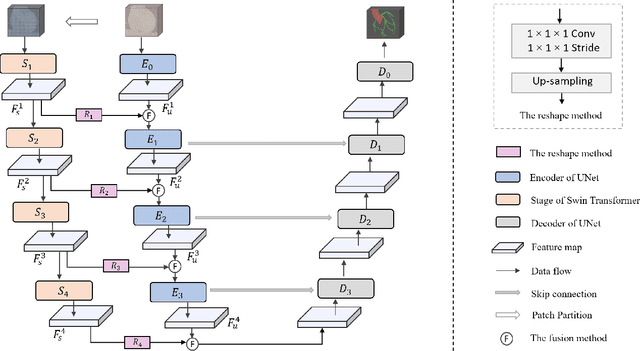
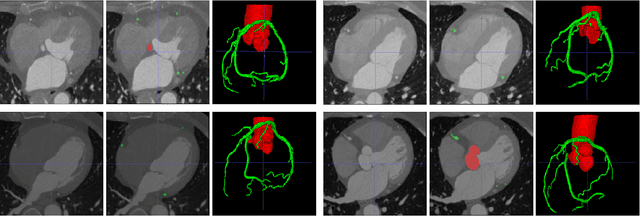
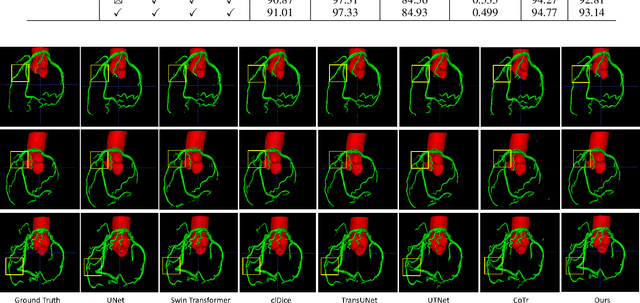
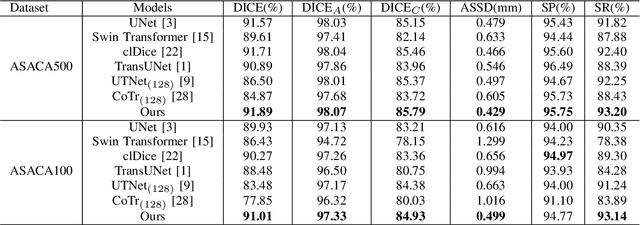
The coronary microvascular disease poses a great threat to human health. Computer-aided analysis/diagnosis systems help physicians intervene in the disease at early stages, where 3D vessel segmentation is a fundamental step. However, there is a lack of carefully annotated dataset to support algorithm development and evaluation. On the other hand, the commonly-used U-Net structures often yield disconnected and inaccurate segmentation results, especially for small vessel structures. In this paper, motivated by the data scarcity, we first construct two large-scale vessel segmentation datasets consisting of 100 and 500 computed tomography (CT) volumes with pixel-level annotations by experienced radiologists. To enhance the U-Net, we further propose the cross transformer network (CTN) for fine-grained vessel segmentation. In CTN, a transformer module is constructed in parallel to a U-Net to learn long-distance dependencies between different anatomical regions; and these dependencies are communicated to the U-Net at multiple stages to endow it with global awareness. Experimental results on the two in-house datasets indicate that this hybrid model alleviates unexpected disconnections by considering topological information across regions. Our codes, together with the trained models are made publicly available at https://github.com/qibaolian/ctn.
Computer-aided Tuberculosis Diagnosis with Attribute Reasoning Assistance
Jul 01, 2022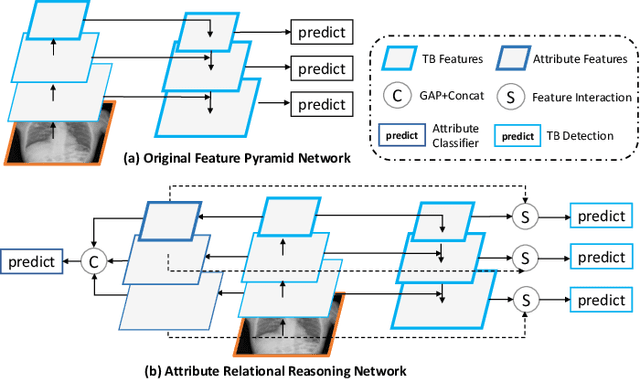
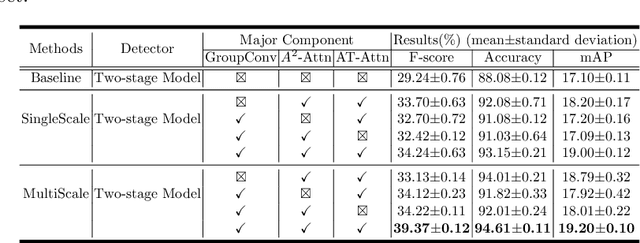
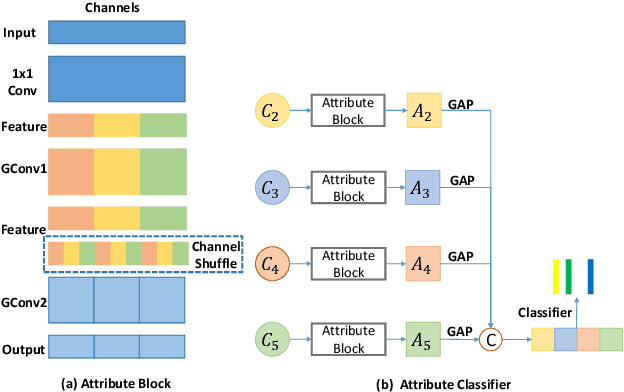
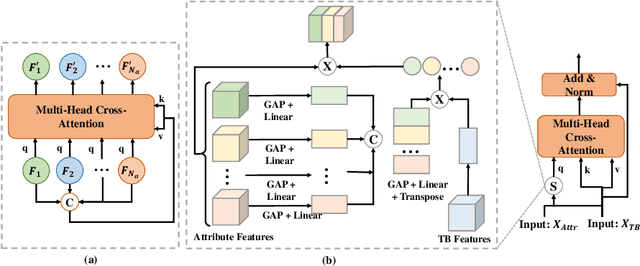
Although deep learning algorithms have been intensively developed for computer-aided tuberculosis diagnosis (CTD), they mainly depend on carefully annotated datasets, leading to much time and resource consumption. Weakly supervised learning (WSL), which leverages coarse-grained labels to accomplish fine-grained tasks, has the potential to solve this problem. In this paper, we first propose a new large-scale tuberculosis (TB) chest X-ray dataset, namely the tuberculosis chest X-ray attribute dataset (TBX-Att), and then establish an attribute-assisted weakly-supervised framework to classify and localize TB by leveraging the attribute information to overcome the insufficiency of supervision in WSL scenarios. Specifically, first, the TBX-Att dataset contains 2000 X-ray images with seven kinds of attributes for TB relational reasoning, which are annotated by experienced radiologists. It also includes the public TBX11K dataset with 11200 X-ray images to facilitate weakly supervised detection. Second, we exploit a multi-scale feature interaction model for TB area classification and detection with attribute relational reasoning. The proposed model is evaluated on the TBX-Att dataset and will serve as a solid baseline for future research. The code and data will be available at https://github.com/GangmingZhao/tb-attribute-weak-localization.
Structured Attention Composition for Temporal Action Localization
May 27, 2022
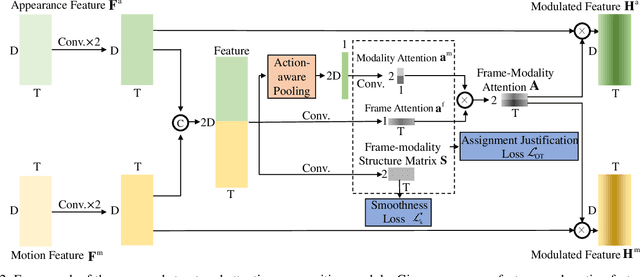
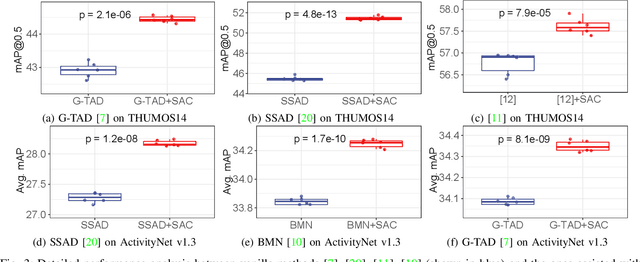

Temporal action localization aims at localizing action instances from untrimmed videos. Existing works have designed various effective modules to precisely localize action instances based on appearance and motion features. However, by treating these two kinds of features with equal importance, previous works cannot take full advantage of each modality feature, making the learned model still sub-optimal. To tackle this issue, we make an early effort to study temporal action localization from the perspective of multi-modality feature learning, based on the observation that different actions exhibit specific preferences to appearance or motion modality. Specifically, we build a novel structured attention composition module. Unlike conventional attention, the proposed module would not infer frame attention and modality attention independently. Instead, by casting the relationship between the modality attention and the frame attention as an attention assignment process, the structured attention composition module learns to encode the frame-modality structure and uses it to regularize the inferred frame attention and modality attention, respectively, upon the optimal transport theory. The final frame-modality attention is obtained by the composition of the two individual attentions. The proposed structured attention composition module can be deployed as a plug-and-play module into existing action localization frameworks. Extensive experiments on two widely used benchmarks show that the proposed structured attention composition consistently improves four state-of-the-art temporal action localization methods and builds new state-of-the-art performance on THUMOS14. Code is availabel at https://github.com/VividLe/Structured-Attention-Composition.
Robust Single Image Dehazing Based on Consistent and Contrast-Assisted Reconstruction
Mar 29, 2022
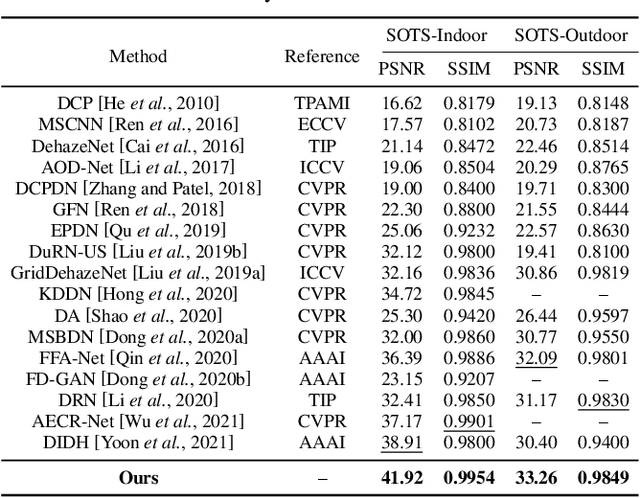
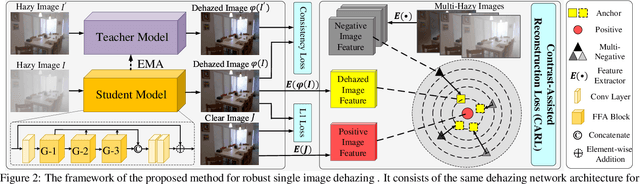
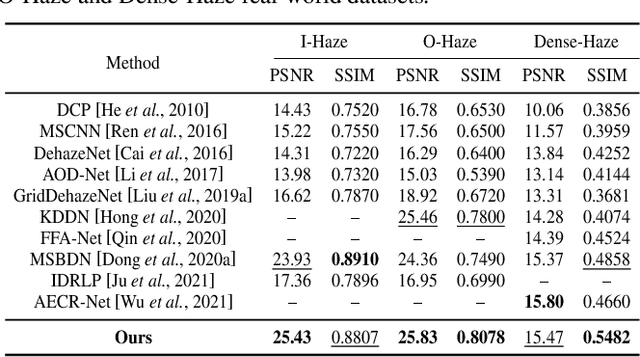
Single image dehazing as a fundamental low-level vision task, is essential for the development of robust intelligent surveillance system. In this paper, we make an early effort to consider dehazing robustness under variational haze density, which is a realistic while under-studied problem in the research filed of singe image dehazing. To properly address this problem, we propose a novel density-variational learning framework to improve the robustness of the image dehzing model assisted by a variety of negative hazy images, to better deal with various complex hazy scenarios. Specifically, the dehazing network is optimized under the consistency-regularized framework with the proposed Contrast-Assisted Reconstruction Loss (CARL). The CARL can fully exploit the negative information to facilitate the traditional positive-orient dehazing objective function, by squeezing the dehazed image to its clean target from different directions. Meanwhile, the consistency regularization keeps consistent outputs given multi-level hazy images, thus improving the model robustness. Extensive experimental results on two synthetic and three real-world datasets demonstrate that our method significantly surpasses the state-of-the-art approaches.