 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Convolution for Semantic Segmentation
Jun 01, 2018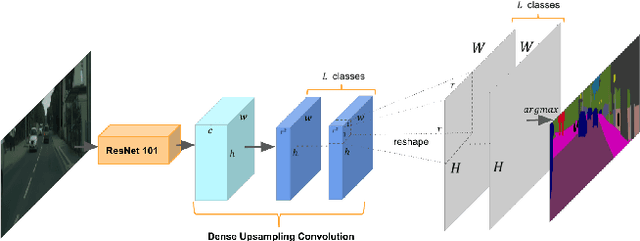
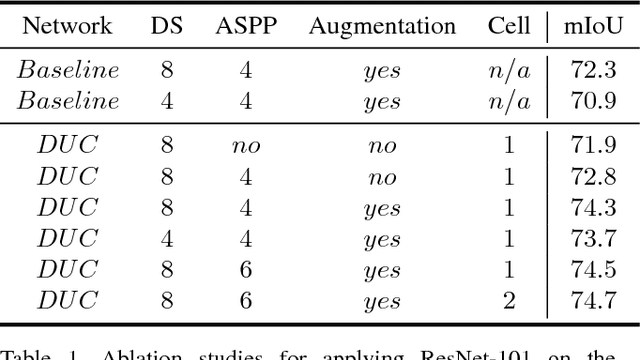
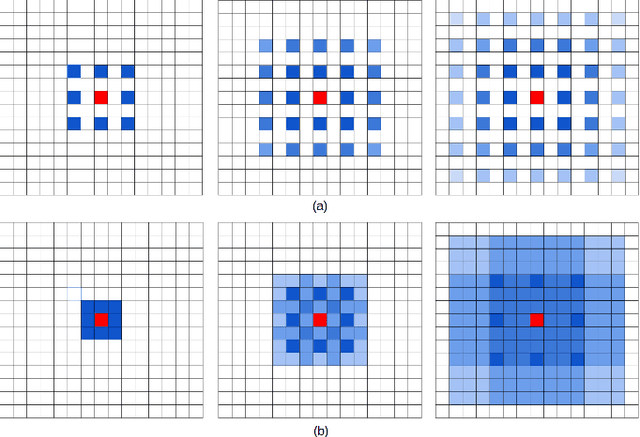
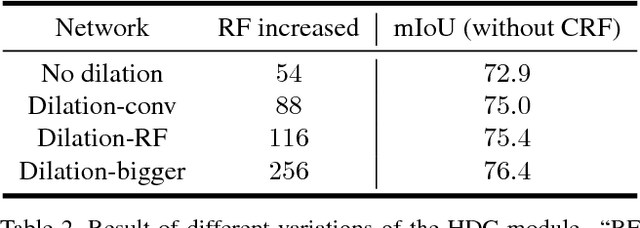
Recent advances in deep learning, especially deep convolutional neural networks (CNNs), have led to significant improvement over previous semantic segmentation systems. Here we show how to improve pixel-wise semantic segmentation by manipulating convolution-related operations that are of both theoretical and practical value. First, we design dense upsampling convolution (DUC) to generate pixel-level prediction, which is able to capture and decode more detailed information that is generally missing in bilinear upsampling. Second, we propose a hybrid dilated convolution (HDC) framework in the encoding phase. This framework 1) effectively enlarges the receptive fields (RF) of the network to aggregate global information; 2) alleviates what we call the "gridding issue" caused by the standard dilated convolution operation. We evaluate our approaches thoroughly on the Cityscapes dataset, and achieve a state-of-art result of 80.1% mIOU in the test set at the time of submission. We also have achieved state-of-the-art overall on the KITTI road estimation benchmark and the PASCAL VOC2012 segmentation task. Our source code can be found at https://github.com/TuSimple/TuSimple-DUC .
Image Super-Resolution via Dual-State Recurrent Networks
May 07, 2018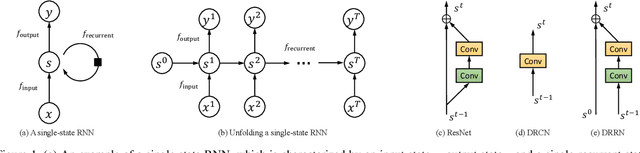
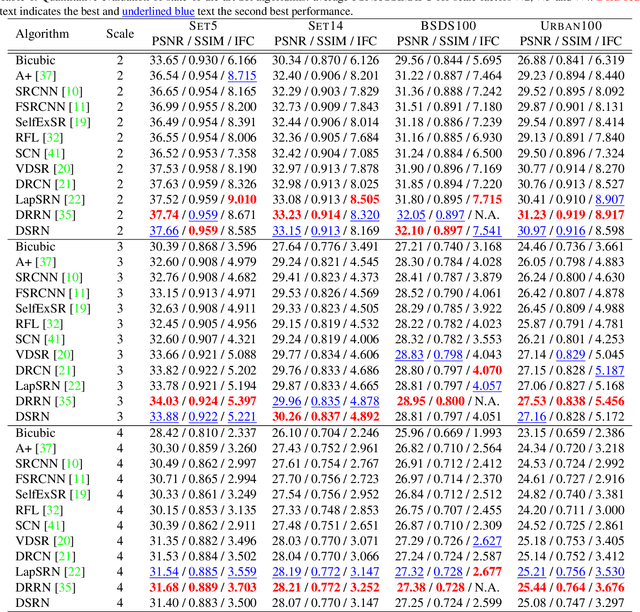
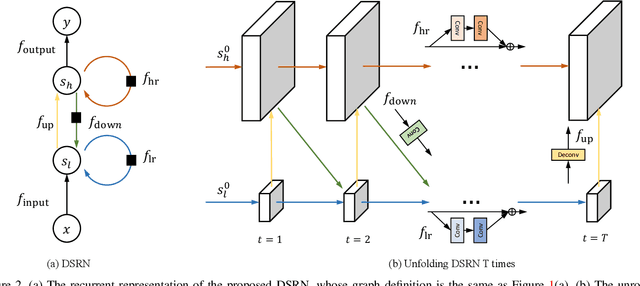
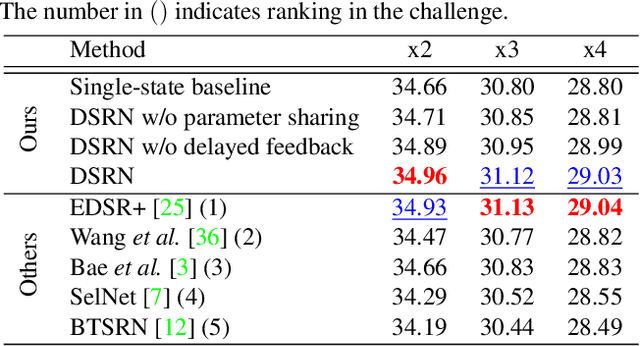
Advances in image super-resolution (SR) have recently benefited significantly from rapid developments in deep neural networks. Inspired by these recent discoveries, we note that many state-of-the-art deep SR architectures can be reformulated as a single-state recurrent neural network (RNN) with finite unfoldings. In this paper, we explore new structures for SR based on this compact RNN view, leading us to a dual-state design, the Dual-State Recurrent Network (DSRN). Compared to its single state counterparts that operate at a fixed spatial resolution, DSRN exploits both low-resolution (LR) and high-resolution (HR) signals jointly. Recurrent signals are exchanged between these states in both directions (both LR to HR and HR to LR) via delayed feedback. Extensive quantitative and qualitative evaluations on benchmark datasets and on a recent challenge demonstrate that the proposed DSRN performs favorably against state-of-the-art algorithms in terms of both memory consumption and predictive accuracy.
Survey of Face Detection on Low-quality Images
Apr 19, 2018
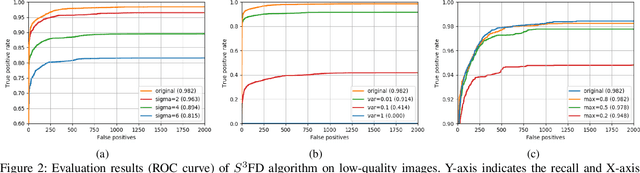
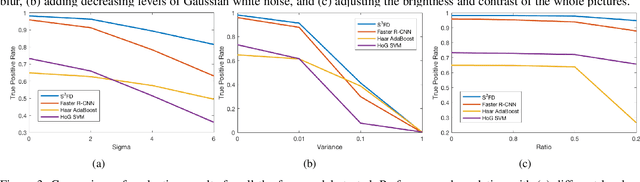
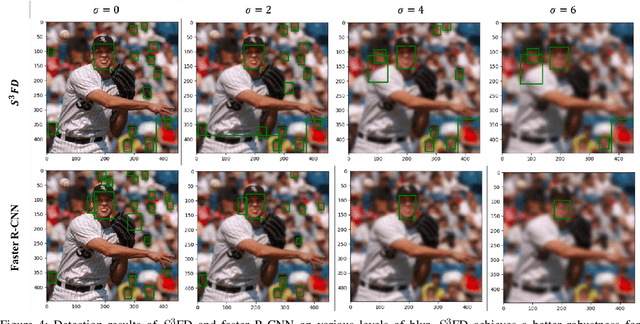
Face detection is a well-explored problem. Many challenges on face detectors like extreme pose, illumination, low resolution and small scales are studied in the previous work. However, previous proposed models are mostly trained and tested on good-quality images which are not always the case for practical applications like surveillance systems. In this paper, we first review the current state-of-the-art face detectors and their performance on benchmark dataset FDDB, and compare the design protocols of the algorithms. Secondly, we investigate their performance degradation while testing on low-quality images with different levels of blur, noise, and contrast. Our results demonstrate that both hand-crafted and deep-learning based face detectors are not robust enough for low-quality images. It inspires researchers to produce more robust design for face detection in the wild.
When Image Denoising Meets High-Level Vision Tasks: A Deep Learning Approach
Apr 16, 2018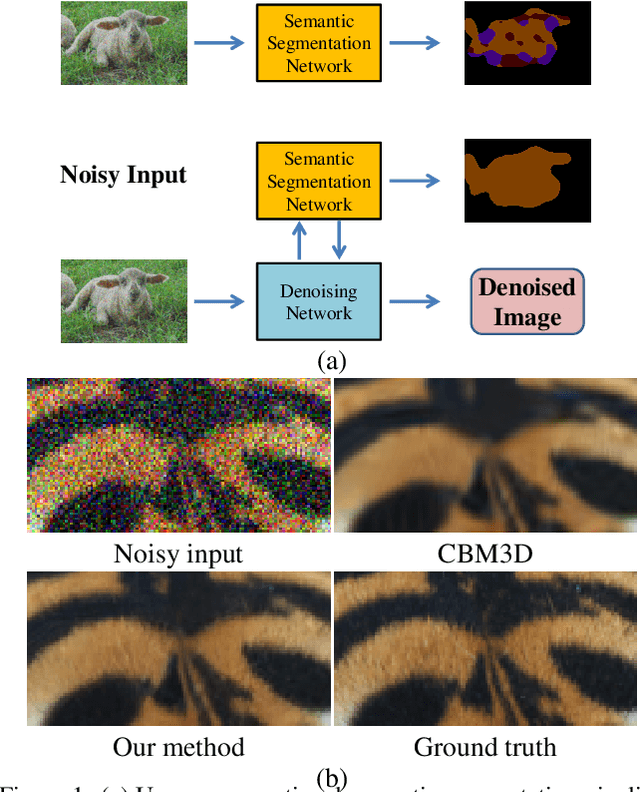
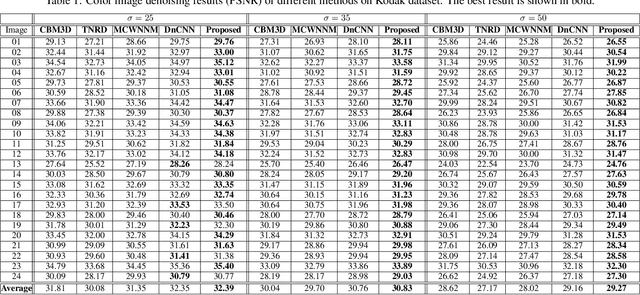
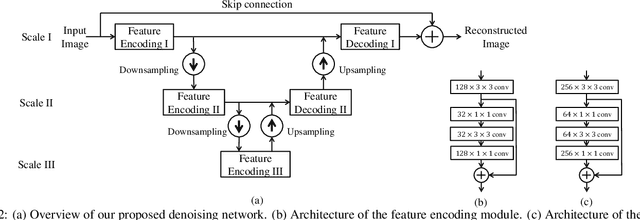
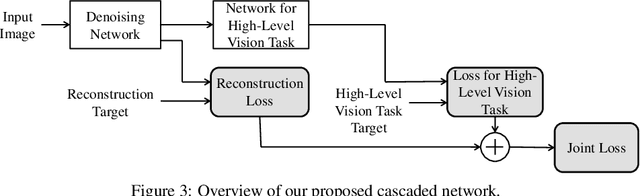
Conventionally, image denoising and high-level vision tasks are handled separately in computer vision. In this paper, we cope with the two jointly and explore the mutual influence between them. First we propose a convolutional neural network for image denoising which achieves the state-of-the-art performance. Second we propose a deep neural network solution that cascades two modules for image denoising and various high-level tasks, respectively, and use the joint loss for updating only the denoising network via back-propagation. We demonstrate that on one hand, the proposed denoiser has the generality to overcome the performance degradation of different high-level vision tasks. On the other hand, with the guidance of high-level vision information, the denoising network can generate more visually appealing results. To the best of our knowledge, this is the first work investigating the benefit of exploiting image semantics simultaneously for image denoising and high-level vision tasks via deep learning. The code is available online https://github.com/Ding-Liu/DeepDenoising.
Learning Simple Thresholded Features with Sparse Support Recovery
Apr 16, 2018
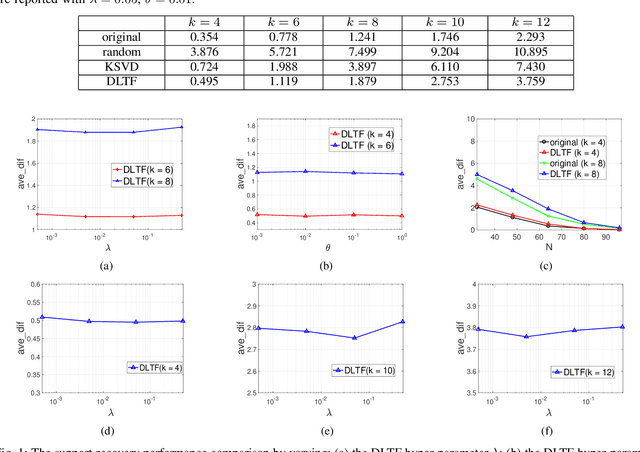
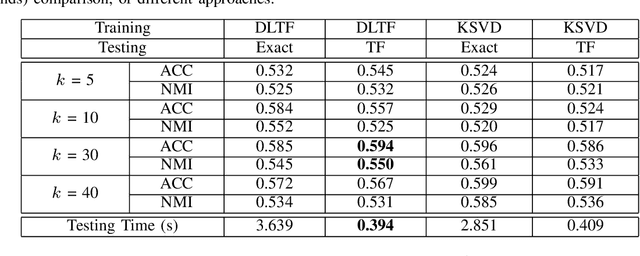

The thresholded feature has recently emerged as an extremely efficient, yet rough empirical approximation, of the time-consuming sparse coding inference process. Such an approximation has not yet been rigorously examined, and standard dictionaries often lead to non-optimal performance when used for computing thresholded features. In this paper, we first present two theoretical recovery guarantees for the thresholded feature to exactly recover the nonzero support of the sparse code. Motivated by them, we then formulate the Dictionary Learning for Thresholded Features (DLTF) model, which learns an optimized dictionary for applying the thresholded feature. In particular, for the $(k, 2)$ norm involved, a novel proximal operator with log-linear time complexity $O(m\log m)$ is derived. We evaluate the performance of DLTF on a vast range of synthetic and real-data tasks, where DLTF demonstrates remarkable efficiency, effectiveness and robustness in all experiments. In addition, we briefly discuss the potential link between DLTF and deep learning building blocks.
Enhance Visual Recognition under Adverse Conditions via Deep Networks
Dec 20, 2017

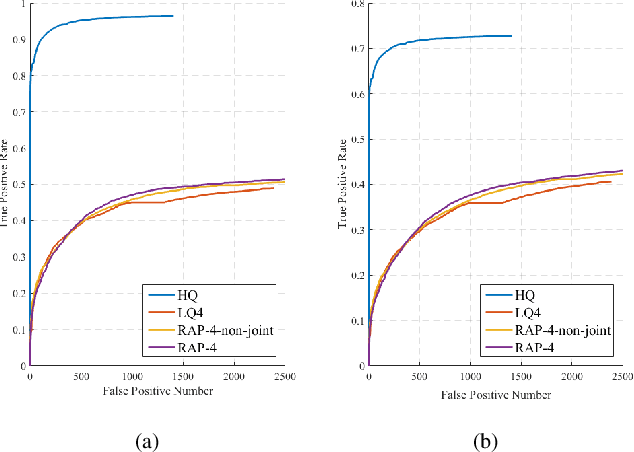

Visual recognition under adverse conditions is a very important and challenging problem of high practical value, due to the ubiquitous existence of quality distortions during image acquisition, transmission, or storage. While deep neural networks have been extensively exploited in the techniques of low-quality image restoration and high-quality image recognition tasks respectively, few studies have been done on the important problem of recognition from very low-quality images. This paper proposes a deep learning based framework for improving the performance of image and video recognition models under adverse conditions, using robust adverse pre-training or its aggressive variant. The robust adverse pre-training algorithms leverage the power of pre-training and generalizes conventional unsupervised pre-training and data augmentation methods. We further develop a transfer learning approach to cope with real-world datasets of unknown adverse conditions. The proposed framework is comprehensively evaluated on a number of image and video recognition benchmarks, and obtains significant performance improvements under various single or mixed adverse conditions. Our visualization and analysis further add to the explainability of results.
Learning Object Detectors from Scratch with Gated Recurrent Feature Pyramids
Dec 04, 2017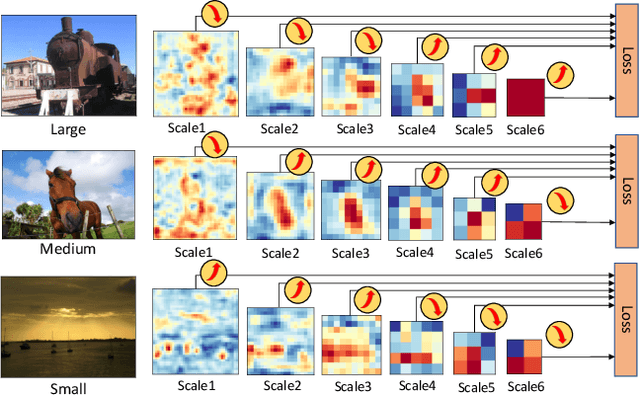

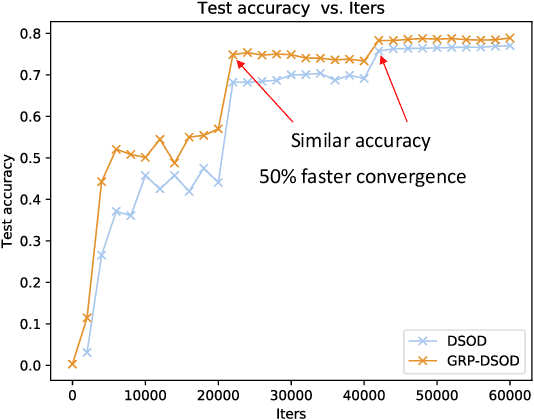
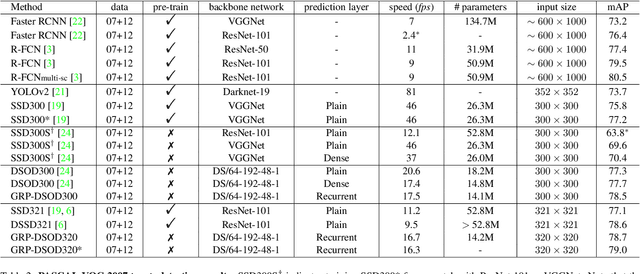
In this paper, we propose gated recurrent feature pyramid for the problem of learning object detection from scratch. Our approach is motivated by the recent work of deeply supervised object detector (DSOD), but explores new network architecture that dynamically adjusts the supervision intensities of intermediate layers for various scales in object detection. The benefits of the proposed method are two-fold: First, we propose a recurrent feature-pyramid structure to squeeze rich spatial and semantic features into a single prediction layer that further reduces the number of parameters to learn (DSOD need learn 1/2, but our method need only 1/3). Thus our new model is more fit for learning from scratch, and can converge faster than DSOD (using only 50% of iterations). Second, we introduce a novel gate-controlled prediction strategy to adaptively enhance or attenuate supervision at different scales based on the input object size. As a result, our model is more suitable for detecting small objects. To the best of our knowledge, our study is the best performed model of learning object detection from scratch. Our method in the PASCAL VOC 2012 comp3 leaderboard (which compares object detectors that are trained only with PASCAL VOC data) demonstrates a significant performance jump, from previous 64% to our 77% (VOC 07++12) and 72.5% (VOC 12). We also evaluate the performance of our method on PASCAL VOC 2007, 2012 and MS COCO datasets, and find that the accuracy of our learning from scratch method can even beat a lot of the state-of-the-art detection methods which use pre-trained models from ImageNet. Code is available at: https://github.com/szq0214/GRP-DSOD .
Robust Emotion Recognition from Low Quality and Low Bit Rate Video: A Deep Learning Approach
Sep 10, 2017
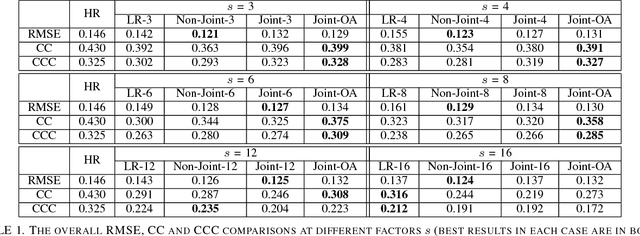
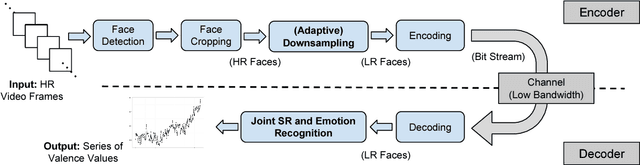
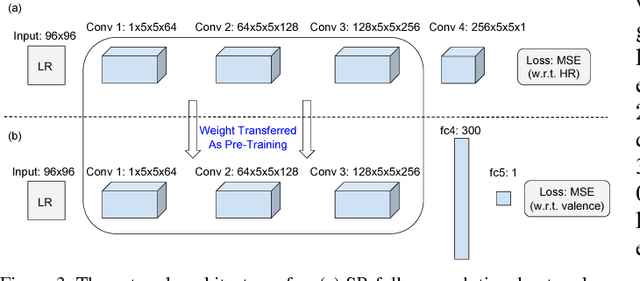
Emotion recognition from facial expressions is tremendously useful, especially when coupled with smart devices and wireless multimedia applications. However, the inadequate network bandwidth often limits the spatial resolution of the transmitted video, which will heavily degrade the recognition reliability. We develop a novel framework to achieve robust emotion recognition from low bit rate video. While video frames are downsampled at the encoder side, the decoder is embedded with a deep network model for joint super-resolution (SR) and recognition. Notably, we propose a novel max-mix training strategy, leading to a single "One-for-All" model that is remarkably robust to a vast range of downsampling factors. That makes our framework well adapted for the varied bandwidths in real transmission scenarios, without hampering scalability or efficiency. The proposed framework is evaluated on the AVEC 2016 benchmark, and demonstrates significantly improved stand-alone recognition performance, as well as rate-distortion (R-D) performance, than either directly recognizing from LR frames, or separating SR and recognition.
Learning Audio Sequence Representations for Acoustic Event Classification
Jul 27, 2017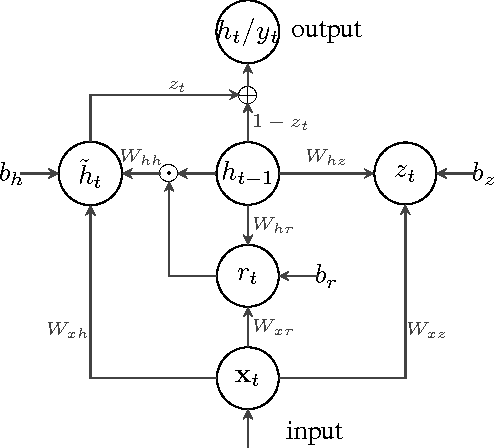
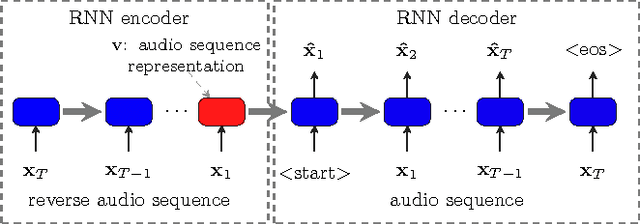
Acoustic Event Classification (AEC) has become a significant task for machines to perceive the surrounding auditory scene. However, extracting effective representations that capture the underlying characteristics of the acoustic events is still challenging. Previous methods mainly focused on designing the audio features in a 'hand-crafted' manner. Interestingly, data-learnt features have been recently reported to show better performance. Up to now, these were only considered on the frame-level. In this paper, we propose an unsupervised learning framework to learn a vector representation of an audio sequence for AEC. This framework consists of a Recurrent Neural Network (RNN) encoder and a RNN decoder, which respectively transforms the variable-length audio sequence into a fixed-length vector and reconstructs the input sequence on the generated vector. After training the encoder-decoder, we feed the audio sequences to the encoder and then take the learnt vectors as the audio sequence representations. Compared with previous methods, the proposed method can not only deal with the problem of arbitrary-lengths of audio streams, but also learn the salient information of the sequence. Extensive evaluation on a large-size acoustic event database is performed, and the empirical results demonstrate that the learnt audio sequence representation yields a significant performance improvement by a large margin compared with other state-of-the-art hand-crafted sequence features for AEC.
Learning a Mixture of Deep Networks for Single Image Super-Resolution
Jan 03, 2017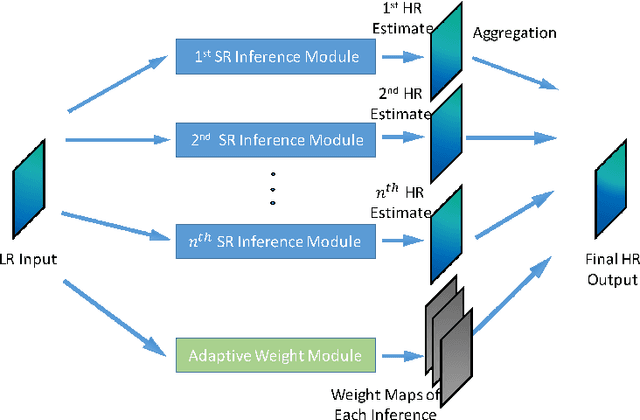
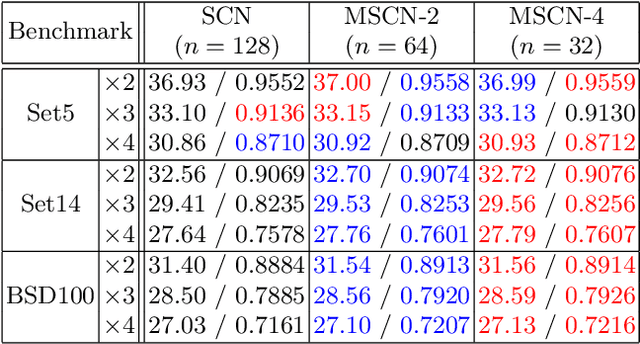
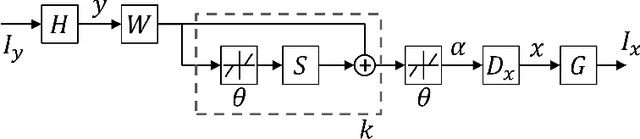
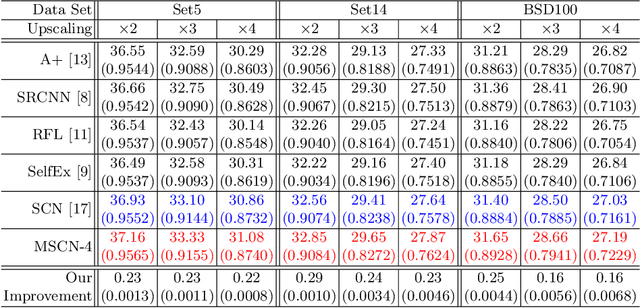
Single image super-resolution (SR) is an ill-posed problem which aims to recover high-resolution (HR) images from their low-resolution (LR) observations. The crux of this problem lies in learning the complex mapping between low-resolution patches and the corresponding high-resolution patches. Prior arts have used either a mixture of simple regression models or a single non-linear neural network for this propose. This paper proposes the method of learning a mixture of SR inference modules in a unified framework to tackle this problem. Specifically, a number of SR inference modules specialized in different image local patterns are first independently applied on the LR image to obtain various HR estimates, and the resultant HR estimates are adaptively aggregated to form the final HR image. By selecting neural networks as the SR inference module, the whole procedure can be incorporated into a unified network and be optimized jointly. Extensive experiments are conducted to investigate the relation between restoration performance and different network architectures. Compared with other current image SR approaches, our proposed method achieves state-of-the-arts restoration results on a wide range of images consistently while allowing more flexible design choices. The source codes are available in http://www.ifp.illinois.edu/~dingliu2/accv2016.