 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWatching the World Go By: Representation Learning from Unlabeled Videos
Mar 18, 2020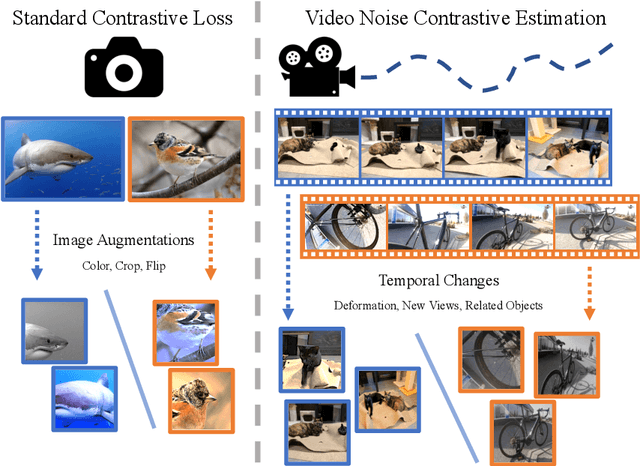


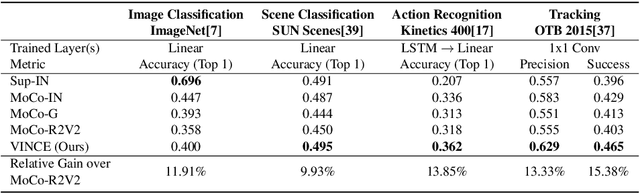
Recent single image unsupervised representation learning techniques show remarkable success on a variety of tasks. The basic principle in these works is instance discrimination: learning to differentiate between two augmented versions of the same image and a large batch of unrelated images. Networks learn to ignore the augmentation noise and extract semantically meaningful representations. Prior work uses artificial data augmentation techniques such as cropping, and color jitter which can only affect the image in superficial ways and are not aligned with how objects actually change e.g. occlusion, deformation, viewpoint change. In this paper, we argue that videos offer this natural augmentation for free. Videos can provide entirely new views of objects, show deformation, and even connect semantically similar but visually distinct concepts. We propose Video Noise Contrastive Estimation, a method for using unlabeled video to learn strong, transferable single image representations. We demonstrate improvements over recent unsupervised single image techniques, as well as over fully supervised ImageNet pretraining, across a variety of temporal and non-temporal tasks.
Human Grasp Classification for Reactive Human-to-Robot Handovers
Mar 12, 2020
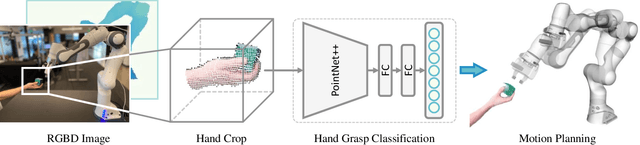

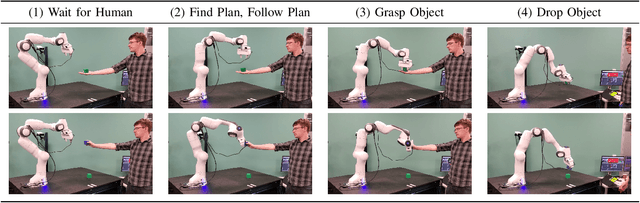
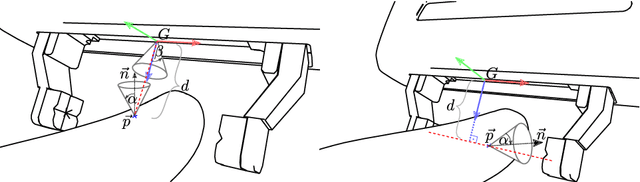
Transfer of objects between humans and robots is a critical capability for collaborative robots. Although there has been a recent surge of interest in human-robot handovers, most prior research focus on robot-to-human handovers. Further, work on the equally critical human-to-robot handovers often assumes humans can place the object in the robot's gripper. In this paper, we propose an approach for human-to-robot handovers in which the robot meets the human halfway, by classifying the human's grasp of the object and quickly planning a trajectory accordingly to take the object from the human's hand according to their intent. To do this, we collect a human grasp dataset which covers typical ways of holding objects with various hand shapes and poses, and learn a deep model on this dataset to classify the hand grasps into one of these categories. We present a planning and execution approach that takes the object from the human hand according to the detected grasp and hand position, and replans as necessary when the handover is interrupted. Through a systematic evaluation, we demonstrate that our system results in more fluent handovers versus two baselines. We also present findings from a user study (N = 9) demonstrating the effectiveness and usability of our approach with naive users in different scenarios. More results and videos can be found at http://wyang.me/handovers.
Transferable Task Execution from Pixels through Deep Planning Domain Learning
Mar 08, 2020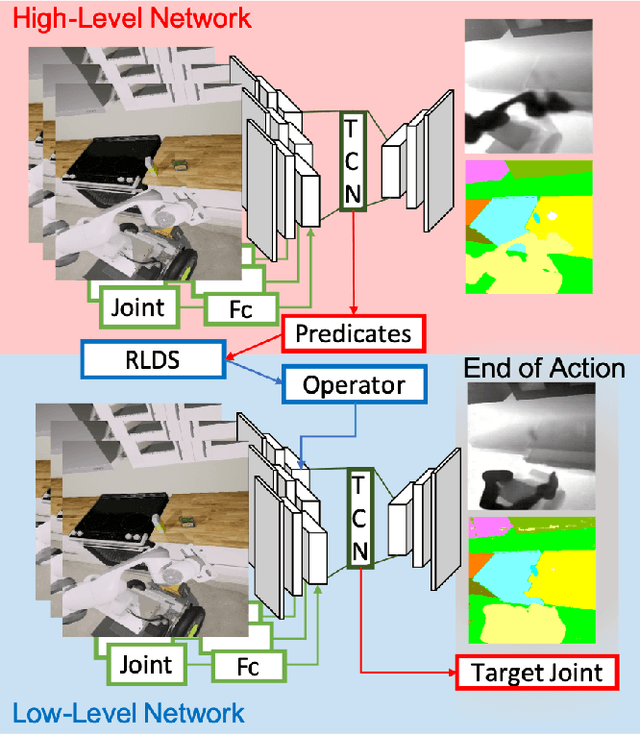
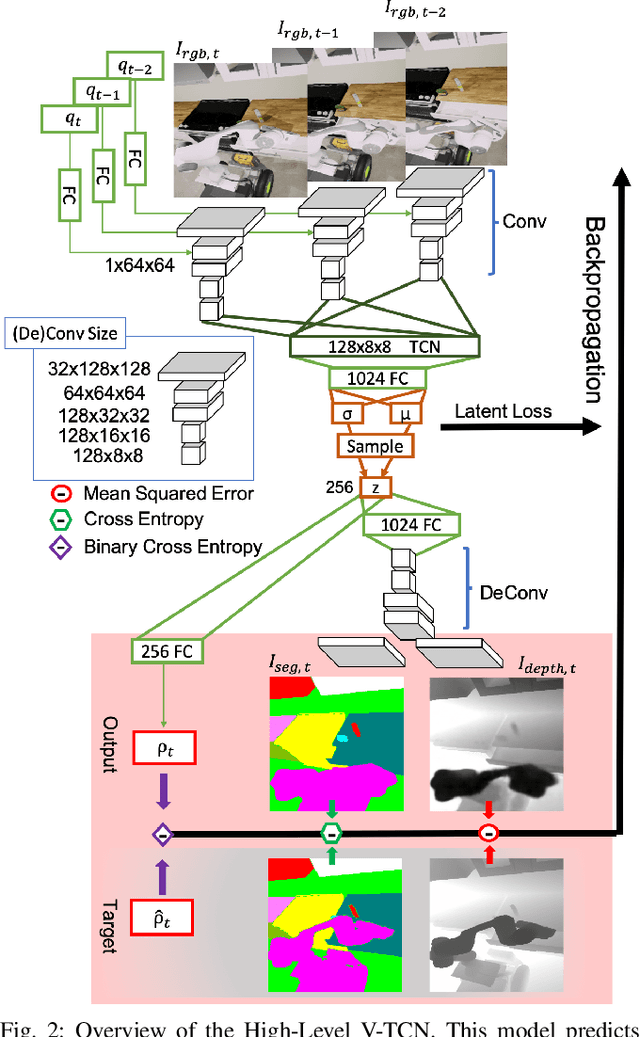
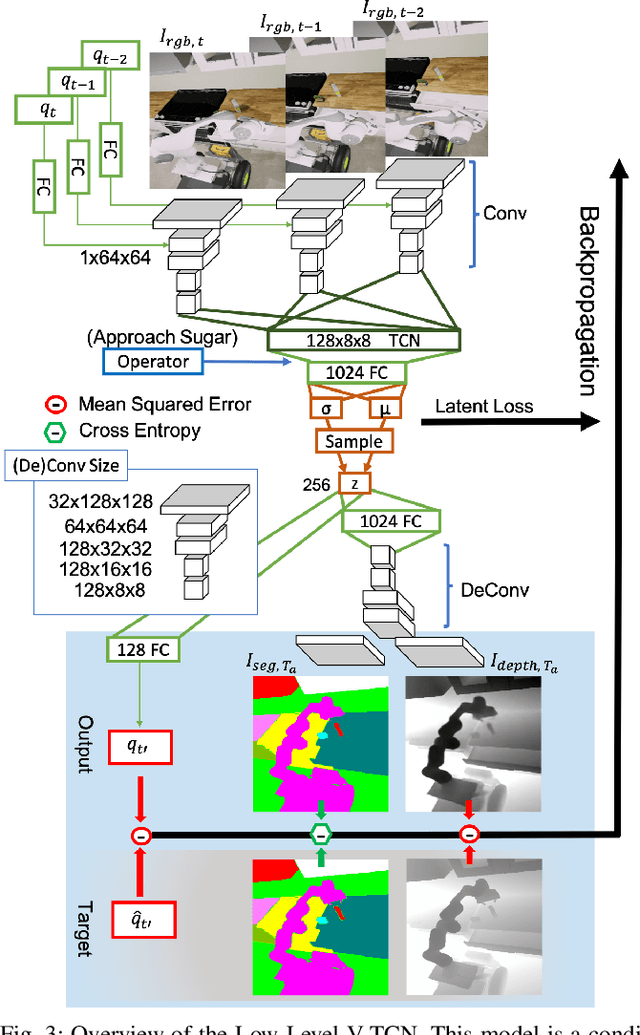

While robots can learn models to solve many manipulation tasks from raw visual input, they cannot usually use these models to solve new problems. On the other hand, symbolic planning methods such as STRIPS have long been able to solve new problems given only a domain definition and a symbolic goal, but these approaches often struggle on the real world robotic tasks due to the challenges of grounding these symbols from sensor data in a partially-observable world. We propose Deep Planning Domain Learning (DPDL), an approach that combines the strengths of both methods to learn a hierarchical model. DPDL learns a high-level model which predicts values for a large set of logical predicates consisting of the current symbolic world state, and separately learns a low-level policy which translates symbolic operators into executable actions on the robot. This allows us to perform complex, multi-step tasks even when the robot has not been explicitly trained on them. We show our method on manipulation tasks in a photorealistic kitchen scenario.
In-Hand Object Pose Tracking via Contact Feedback and GPU-Accelerated Robotic Simulation
Mar 07, 2020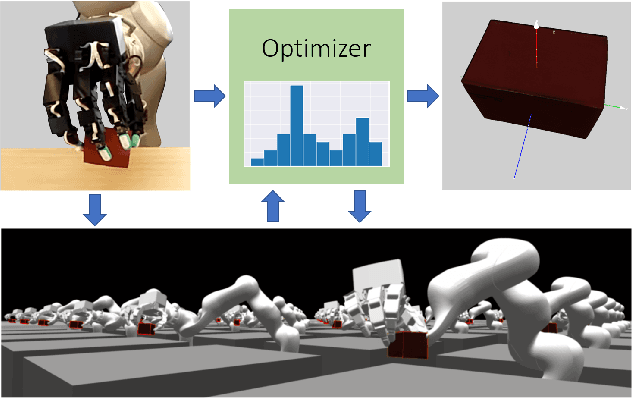
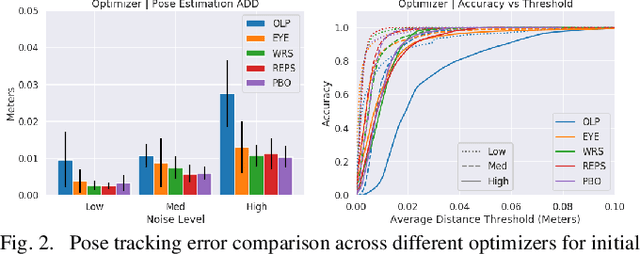

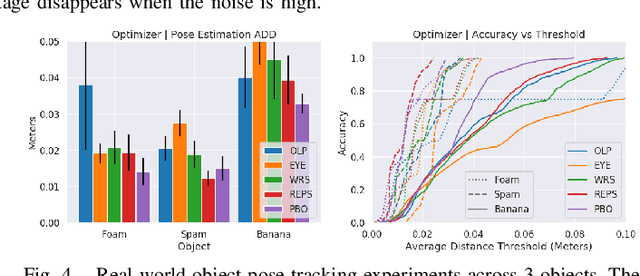
Tracking the pose of an object while it is being held and manipulated by a robot hand is difficult for vision-based methods due to significant occlusions. Prior works have explored using contact feedback and particle filters to localize in-hand objects. However, they have mostly focused on the static grasp setting and not when the object is in motion, as doing so requires modeling of complex contact dynamics. In this work, we propose using GPU-accelerated parallel robot simulations and derivative-free, sample-based optimizers to track in-hand object poses with contact feedback during manipulation. We use physics simulation as the forward model for robot-object interactions, and the algorithm jointly optimizes for the state and the parameters of the simulations, so they better match with those of the real world. Our method runs in real-time (30Hz) on a single GPU, and it achieves an average point cloud distance error of 6mm in simulation experiments and 13mm in the real-world ones. View experiment videos at https://sites.google.com/view/in-hand-object-pose-tracking/
Information Theoretic Model Predictive Q-Learning
Dec 31, 2019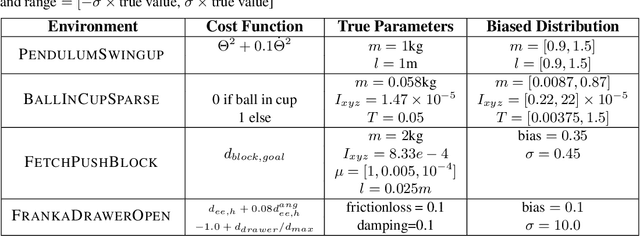
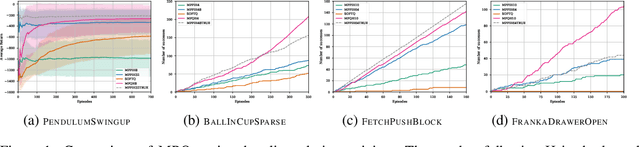
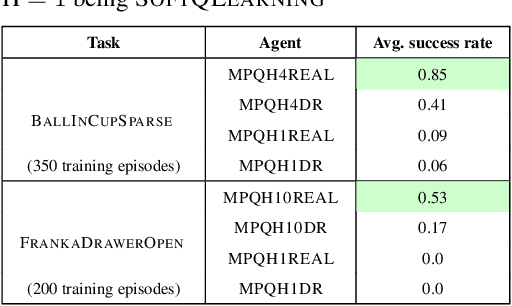
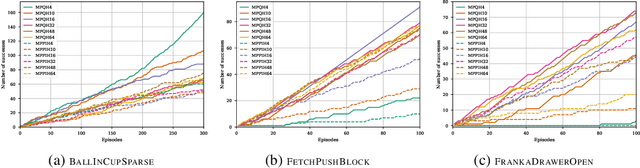
Model-free Reinforcement Learning (RL) algorithms work well in sequential decision-making problems when experience can be collected cheaply and model-based RL is effective when system dynamics can be modeled accurately. However, both of these assumptions can be violated in real world problems such as robotics, where querying the system can be prohibitively expensive and real-world dynamics can be difficult to model accurately. Although sim-to-real approaches such as domain randomization attempt to mitigate the effects of biased simulation,they can still suffer from optimization challenges such as local minima and hand-designed distributions for randomization, making it difficult to learn an accurate global value function or policy that directly transfers to the real world. In contrast to RL, Model Predictive Control (MPC) algorithms use a simulator to optimize a simple policy class online, constructing a closed-loop controller that can effectively contend with real-world dynamics. MPC performance is usually limited by factors such as model bias and the limited horizon of optimization. In this work, we present a novel theoretical connection between information theoretic MPC and entropy regularized RL and develop a Q-learning algorithm that can leverage biased models. We validate the proposed algorithm on sim-to-sim control tasks to demonstrate the improvements over optimal control and reinforcement learning from scratch. Our approach paves the way for deploying reinforcement learning algorithms on real-robots in a systematic manner.
LatentFusion: End-to-End Differentiable Reconstruction and Rendering for Unseen Object Pose Estimation
Dec 13, 2019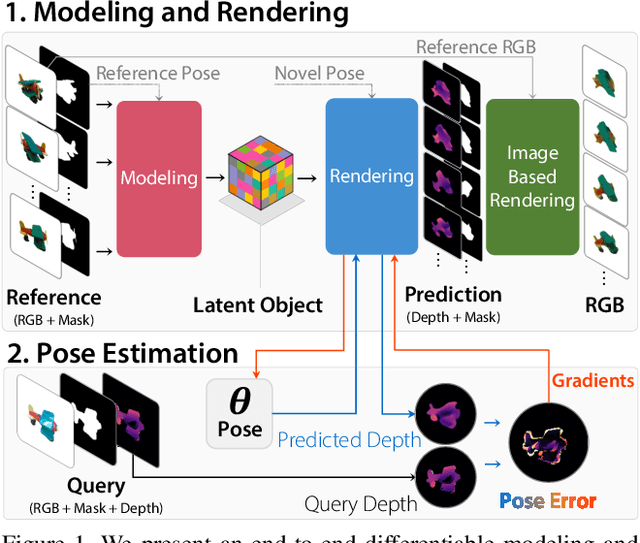
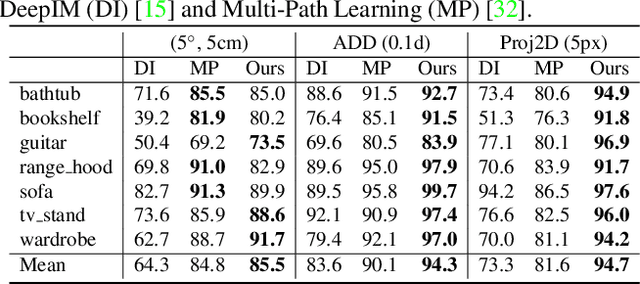
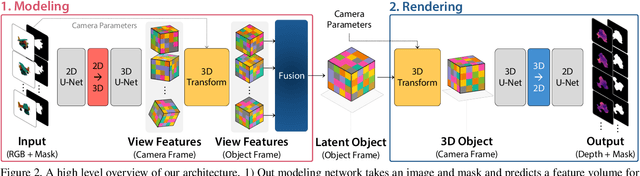
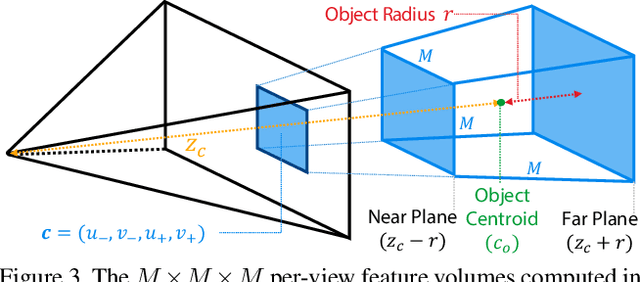
Current 6D object pose estimation methods usually require a 3D model for each object. These methods also require additional training in order to incorporate new objects. As a result, they are difficult to scale to a large number of objects and cannot be directly applied to unseen objects. In this work, we propose a novel framework for 6D pose estimation of unseen objects. We design an end-to-end neural network that reconstructs a latent 3D representation of an object using a small number of reference views of the object. Using the learned 3D representation, the network is able to render the object from arbitrary views. Using this neural renderer, we directly optimize for pose given an input image. By training our network with a large number of 3D shapes for reconstruction and rendering, our network generalizes well to unseen objects. We present a new dataset for unseen object pose estimation--MOPED. We evaluate the performance of our method for unseen object pose estimation on MOPED as well as the ModelNet dataset.
A Billion Ways to Grasp: An Evaluation of Grasp Sampling Schemes on a Dense, Physics-based Grasp Data Set
Dec 11, 2019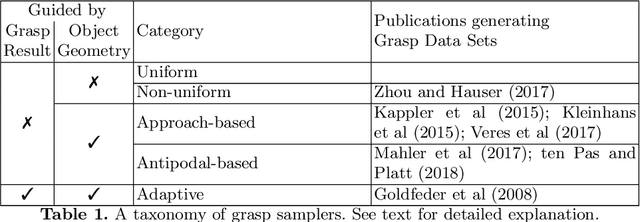


Robot grasping is often formulated as a learning problem. With the increasing speed and quality of physics simulations, generating large-scale grasping data sets that feed learning algorithms is becoming more and more popular. An often overlooked question is how to generate the grasps that make up these data sets. In this paper, we review, classify, and compare different grasp sampling strategies. Our evaluation is based on a fine-grained discretization of SE(3) and uses physics-based simulation to evaluate the quality and robustness of the corresponding parallel-jaw grasps. Specifically, we consider more than 1 billion grasps for each of the 21 objects from the YCB data set. This dense data set lets us evaluate existing sampling schemes w.r.t. their bias and efficiency. Our experiments show that some popular sampling schemes contain significant bias and do not cover all possible ways an object can be grasped.
6-DOF Grasping for Target-driven Object Manipulation in Clutter
Dec 08, 2019

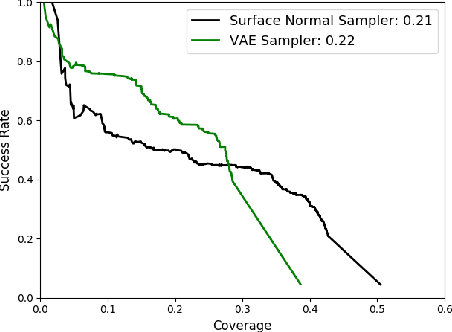
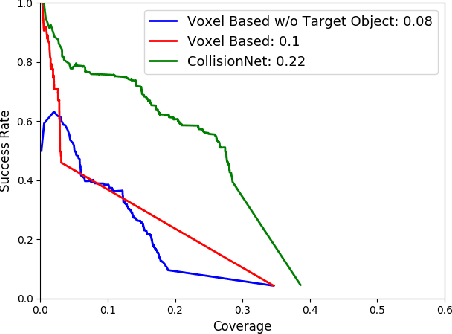
Grasping in cluttered environments is a fundamental but challenging robotic skill. It requires both reasoning about unseen object parts and potential collisions with the manipulator. Most existing data-driven approaches avoid this problem by limiting themselves to top-down planar grasps which is insufficient for many real-world scenarios and greatly limits possible grasps. We present a method that plans 6-DOF grasps for any desired object in a cluttered scene from partial point cloud observations. Our method achieves a grasp success of 80.3%, outperforming baseline approaches by 17.6% and clearing 9 cluttered table scenes (which contain 23 unknown objects and 51 picks in total) on a real robotic platform. By using our learned collision checking module, we can even reason about effective grasp sequences to retrieve objects that are not immediately accessible. Supplementary video can be found at https://youtu.be/w0B5S-gCsJk.
Camera-to-Robot Pose Estimation from a Single Image
Dec 05, 2019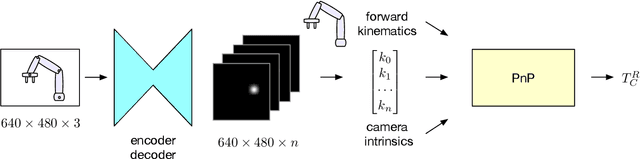

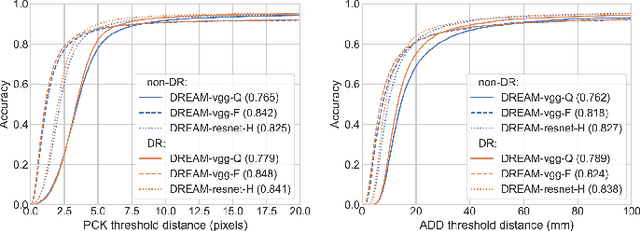
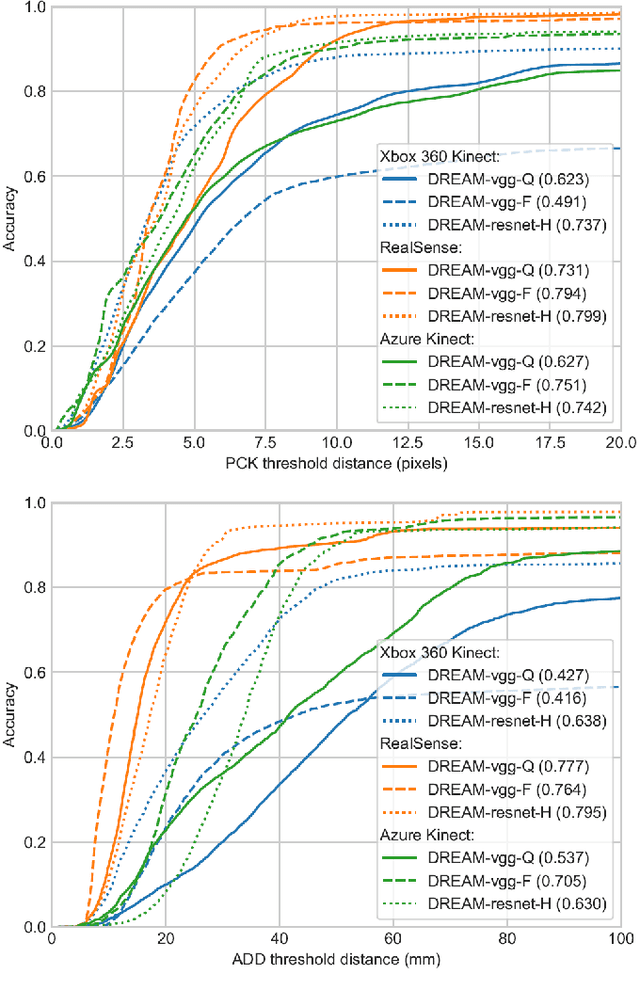
We present an approach for estimating the pose of a camera with respect to a robot from a single image. Our method uses a deep neural network to process an RGB image from the camera to detect 2D keypoints on the robot. The network is trained entirely on simulated data using domain randomization. Perspective-$n$-point (P$n$P) is then used to recover the camera extrinsics, assuming that the joint configuration of the robot manipulator is known. Unlike classic hand-eye calibration systems, our method does not require an off-line calibration step but rather is capable of computing the camera extrinsics from a single frame, thus opening the possibility of on-line calibration. We show experimental results for three different camera sensors, demonstrating that our approach is able to achieve accuracy with a single frame that is better than that of classic off-line hand-eye calibration using multiple frames. With additional frames, accuracy improves even further. Code, datasets, and pretrained models for three widely-used robot manipulators will be made available.
ALFRED: A Benchmark for Interpreting Grounded Instructions for Everyday Tasks
Dec 03, 2019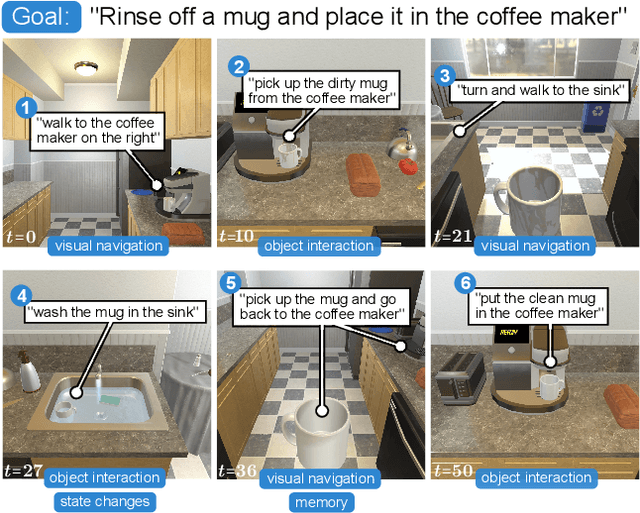
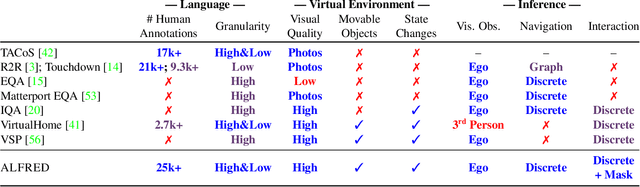
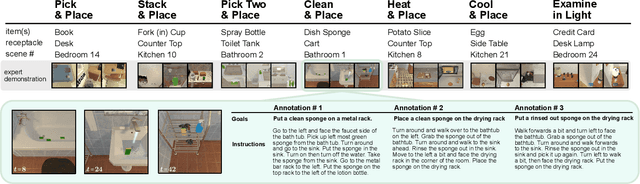
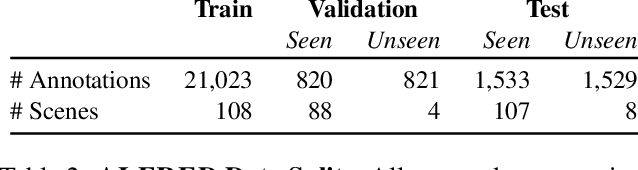
We present ALFRED (Action Learning From Realistic Environments and Directives), a benchmark for learning a mapping from natural language instructions and egocentric vision to sequences of actions for household tasks. Long composition rollouts with non-reversible state changes are among the phenomena we include to shrink the gap between research benchmarks and real-world applications. ALFRED consists of expert demonstrations in interactive visual environments for 25k natural language directives. These directives contain both high-level goals like "Rinse off a mug and place it in the coffee maker." and low-level language instructions like "Walk to the coffee maker on the right." ALFRED tasks are more complex in terms of sequence length, action space, and language than existing vision-and-language task datasets. We show that a baseline model designed for recent embodied vision-and-language tasks performs poorly on ALFRED, suggesting that there is significant room for developing innovative grounded visual language understanding models with this benchmark.