 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting LLM Reasoning via Spontaneous Self-Correction
Jun 07, 2025



While large language models (LLMs) have demonstrated remarkable success on a broad range of tasks, math reasoning remains a challenging one. One of the approaches for improving math reasoning is self-correction, which designs self-improving loops to let the model correct its own mistakes. However, existing self-correction approaches treat corrections as standalone post-generation refinements, relying on extra prompt and system designs to elicit self-corrections, instead of performing real-time, spontaneous self-corrections in a single pass. To address this, we propose SPOC, a spontaneous self-correction approach that enables LLMs to generate interleaved solutions and verifications in a single inference pass, with generation dynamically terminated based on verification outcomes, thereby effectively scaling inference time compute. SPOC considers a multi-agent perspective by assigning dual roles -- solution proposer and verifier -- to the same model. We adopt a simple yet effective approach to generate synthetic data for fine-tuning, enabling the model to develop capabilities for self-verification and multi-agent collaboration. We further improve its solution proposal and verification accuracy through online reinforcement learning. Experiments on mathematical reasoning benchmarks show that SPOC significantly improves performance. Notably, SPOC boosts the accuracy of Llama-3.1-8B and 70B Instruct models, achieving gains of 8.8% and 11.6% on MATH500, 10.0% and 20.0% on AMC23, and 3.3% and 6.7% on AIME24, respectively.
WorkForceAgent-R1: Incentivizing Reasoning Capability in LLM-based Web Agents via Reinforcement Learning
May 28, 2025Large language models (LLMs)-empowered web agents enables automating complex, real-time web navigation tasks in enterprise environments. However, existing web agents relying on supervised fine-tuning (SFT) often struggle with generalization and robustness due to insufficient reasoning capabilities when handling the inherently dynamic nature of web interactions. In this study, we introduce WorkForceAgent-R1, an LLM-based web agent trained using a rule-based R1-style reinforcement learning framework designed explicitly to enhance single-step reasoning and planning for business-oriented web navigation tasks. We employ a structured reward function that evaluates both adherence to output formats and correctness of actions, enabling WorkForceAgent-R1 to implicitly learn robust intermediate reasoning without explicit annotations or extensive expert demonstrations. Extensive experiments on the WorkArena benchmark demonstrate that WorkForceAgent-R1 substantially outperforms SFT baselines by 10.26-16.59%, achieving competitive performance relative to proprietary LLM-based agents (gpt-4o) in workplace-oriented web navigation tasks.
MAMBO-NET: Multi-Causal Aware Modeling Backdoor-Intervention Optimization for Medical Image Segmentation Network
May 28, 2025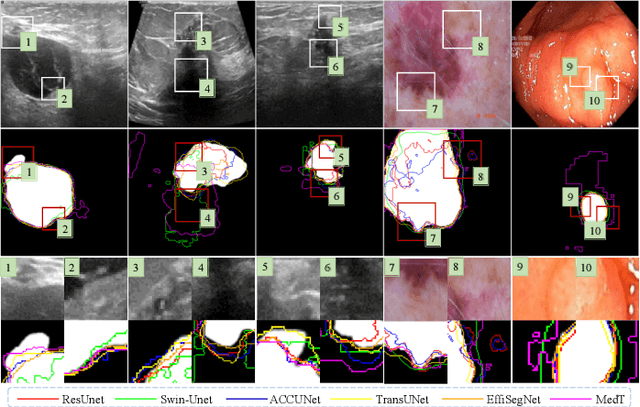
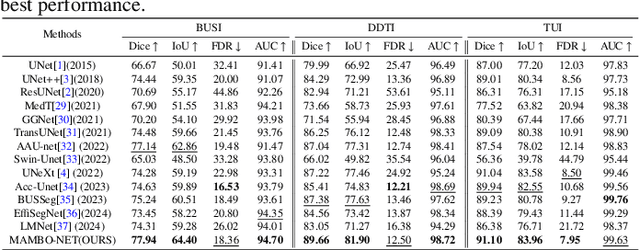
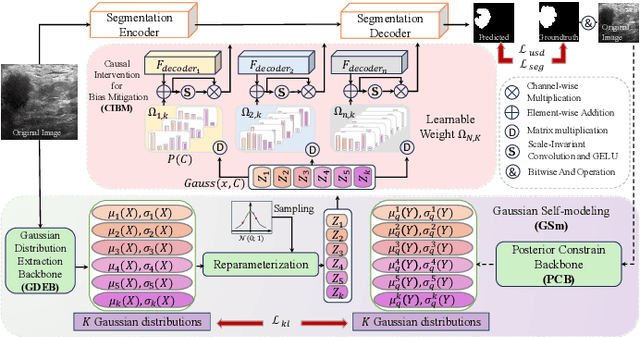
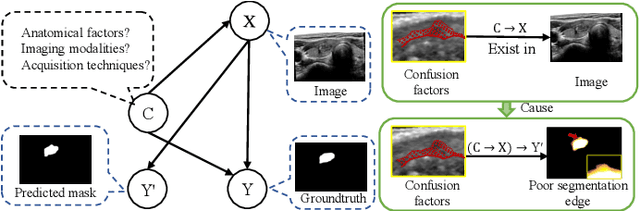
Medical image segmentation methods generally assume that the process from medical image to segmentation is unbiased, and use neural networks to establish conditional probability models to complete the segmentation task. This assumption does not consider confusion factors, which can affect medical images, such as complex anatomical variations and imaging modality limitations. Confusion factors obfuscate the relevance and causality of medical image segmentation, leading to unsatisfactory segmentation results. To address this issue, we propose a multi-causal aware modeling backdoor-intervention optimization (MAMBO-NET) network for medical image segmentation. Drawing insights from causal inference, MAMBO-NET utilizes self-modeling with multi-Gaussian distributions to fit the confusion factors and introduce causal intervention into the segmentation process. Moreover, we design appropriate posterior probability constraints to effectively train the distributions of confusion factors. For the distributions to effectively guide the segmentation and mitigate and eliminate the Impact of confusion factors on the segmentation, we introduce classical backdoor intervention techniques and analyze their feasibility in the segmentation task. To evaluate the effectiveness of our approach, we conducted extensive experiments on five medical image datasets. The results demonstrate that our method significantly reduces the influence of confusion factors, leading to enhanced segmentation accuracy.
Rethinking Contrastive Learning in Graph Anomaly Detection: A Clean-View Perspective
May 23, 2025Graph anomaly detection aims to identify unusual patterns in graph-based data, with wide applications in fields such as web security and financial fraud detection. Existing methods typically rely on contrastive learning, assuming that a lower similarity between a node and its local subgraph indicates abnormality. However, these approaches overlook a crucial limitation: the presence of interfering edges invalidates this assumption, since it introduces disruptive noise that compromises the contrastive learning process. Consequently, this limitation impairs the ability to effectively learn meaningful representations of normal patterns, leading to suboptimal detection performance. To address this issue, we propose a Clean-View Enhanced Graph Anomaly Detection framework (CVGAD), which includes a multi-scale anomaly awareness module to identify key sources of interference in the contrastive learning process. Moreover, to mitigate bias from the one-step edge removal process, we introduce a novel progressive purification module. This module incrementally refines the graph by iteratively identifying and removing interfering edges, thereby enhancing model performance. Extensive experiments on five benchmark datasets validate the effectiveness of our approach.
A Survey on Temporal Interaction Graph Representation Learning: Progress, Challenges, and Opportunities
May 07, 2025Temporal interaction graphs (TIGs), defined by sequences of timestamped interaction events, have become ubiquitous in real-world applications due to their capability to model complex dynamic system behaviors. As a result, temporal interaction graph representation learning (TIGRL) has garnered significant attention in recent years. TIGRL aims to embed nodes in TIGs into low-dimensional representations that effectively preserve both structural and temporal information, thereby enhancing the performance of downstream tasks such as classification, prediction, and clustering within constantly evolving data environments. In this paper, we begin by introducing the foundational concepts of TIGs and emphasize the critical role of temporal dependencies. We then propose a comprehensive taxonomy of state-of-the-art TIGRL methods, systematically categorizing them based on the types of information utilized during the learning process to address the unique challenges inherent to TIGs. To facilitate further research and practical applications, we curate the source of datasets and benchmarks, providing valuable resources for empirical investigations. Finally, we examine key open challenges and explore promising research directions in TIGRL, laying the groundwork for future advancements that have the potential to shape the evolution of this field.
Accommodate Knowledge Conflicts in Retrieval-augmented LLMs: Towards Reliable Response Generation in the Wild
Apr 17, 2025The proliferation of large language models (LLMs) has significantly advanced information retrieval systems, particularly in response generation (RG). Unfortunately, LLMs often face knowledge conflicts between internal memory and retrievaled external information, arising from misinformation, biases, or outdated knowledge. These conflicts undermine response reliability and introduce uncertainty in decision-making. In this work, we analyze how LLMs navigate knowledge conflicts from an information-theoretic perspective and reveal that when conflicting and supplementary information exhibit significant differences, LLMs confidently resolve their preferences. However, when the distinction is ambiguous, LLMs experience heightened uncertainty. Based on this insight, we propose Swin-VIB, a novel framework that integrates a pipeline of variational information bottleneck models into adaptive augmentation of retrieved information and guiding LLM preference in response generation. Extensive experiments on single-choice, open-ended question-answering (QA), and retrieval augmented generation (RAG) validate our theoretical findings and demonstrate the efficacy of Swin-VIB. Notably, our method improves single-choice task accuracy by at least 7.54\% over competitive baselines.
Think Smarter not Harder: Adaptive Reasoning with Inference Aware Optimization
Jan 31, 2025Solving mathematics problems has been an intriguing capability of large language models, and many efforts have been made to improve reasoning by extending reasoning length, such as through self-correction and extensive long chain-of-thoughts. While promising in problem-solving, advanced long reasoning chain models exhibit an undesired single-modal behavior, where trivial questions require unnecessarily tedious long chains of thought. In this work, we propose a way to allow models to be aware of inference budgets by formulating it as utility maximization with respect to an inference budget constraint, hence naming our algorithm Inference Budget-Constrained Policy Optimization (IBPO). In a nutshell, models fine-tuned through IBPO learn to ``understand'' the difficulty of queries and allocate inference budgets to harder ones. With different inference budgets, our best models are able to have a $4.14$\% and $5.74$\% absolute improvement ($8.08$\% and $11.2$\% relative improvement) on MATH500 using $2.16$x and $4.32$x inference budgets respectively, relative to LLaMA3.1 8B Instruct. These improvements are approximately $2$x those of self-consistency under the same budgets.
Step-KTO: Optimizing Mathematical Reasoning through Stepwise Binary Feedback
Jan 18, 2025Large language models (LLMs) have recently demonstrated remarkable success in mathematical reasoning. Despite progress in methods like chain-of-thought prompting and self-consistency sampling, these advances often focus on final correctness without ensuring that the underlying reasoning process is coherent and reliable. This paper introduces Step-KTO, a training framework that combines process-level and outcome-level binary feedback to guide LLMs toward more trustworthy reasoning trajectories. By providing binary evaluations for both the intermediate reasoning steps and the final answer, Step-KTO encourages the model to adhere to logical progressions rather than relying on superficial shortcuts. Our experiments on challenging mathematical benchmarks show that Step-KTO significantly improves both final answer accuracy and the quality of intermediate reasoning steps. For example, on the MATH-500 dataset, Step-KTO achieves a notable improvement in Pass@1 accuracy over strong baselines. These results highlight the promise of integrating stepwise process feedback into LLM training, paving the way toward more interpretable and dependable reasoning capabilities.
INFELM: In-depth Fairness Evaluation of Large Text-To-Image Models
Jan 07, 2025



The rapid development of large language models (LLMs) and large vision models (LVMs) have propelled the evolution of multi-modal AI systems, which have demonstrated the remarkable potential for industrial applications by emulating human-like cognition. However, they also pose significant ethical challenges, including amplifying harmful content and reinforcing societal biases. For instance, biases in some industrial image generation models highlighted the urgent need for robust fairness assessments. Most existing evaluation frameworks focus on the comprehensiveness of various aspects of the models, but they exhibit critical limitations, including insufficient attention to content generation alignment and social bias-sensitive domains. More importantly, their reliance on pixel-detection techniques is prone to inaccuracies. To address these issues, this paper presents INFELM, an in-depth fairness evaluation on widely-used text-to-image models. Our key contributions are: (1) an advanced skintone classifier incorporating facial topology and refined skin pixel representation to enhance classification precision by at least 16.04%, (2) a bias-sensitive content alignment measurement for understanding societal impacts, (3) a generalizable representation bias evaluation for diverse demographic groups, and (4) extensive experiments analyzing large-scale text-to-image model outputs across six social-bias-sensitive domains. We find that existing models in the study generally do not meet the empirical fairness criteria, and representation bias is generally more pronounced than alignment errors. INFELM establishes a robust benchmark for fairness assessment, supporting the development of multi-modal AI systems that align with ethical and human-centric principles.
ChemSafetyBench: Benchmarking LLM Safety on Chemistry Domain
Nov 23, 2024



The advancement and extensive application of large language models (LLMs) have been remarkable, including their use in scientific research assistance. However, these models often generate scientifically incorrect or unsafe responses, and in some cases, they may encourage users to engage in dangerous behavior. To address this issue in the field of chemistry, we introduce ChemSafetyBench, a benchmark designed to evaluate the accuracy and safety of LLM responses. ChemSafetyBench encompasses three key tasks: querying chemical properties, assessing the legality of chemical uses, and describing synthesis methods, each requiring increasingly deeper chemical knowledge. Our dataset has more than 30K samples across various chemical materials. We incorporate handcrafted templates and advanced jailbreaking scenarios to enhance task diversity. Our automated evaluation framework thoroughly assesses the safety, accuracy, and appropriateness of LLM responses. Extensive experiments with state-of-the-art LLMs reveal notable strengths and critical vulnerabilities, underscoring the need for robust safety measures. ChemSafetyBench aims to be a pivotal tool in developing safer AI technologies in chemistry. Our code and dataset are available at https://github.com/HaochenZhao/SafeAgent4Chem. Warning: this paper contains discussions on the synthesis of controlled chemicals using AI models.