 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRUBi: Reducing Unimodal Biases in Visual Question Answering
Jun 24, 2019



Visual Question Answering (VQA) is the task of answering questions about an image. Some VQA models often exploit unimodal biases to provide the correct answer without using the image information. As a result, they suffer from a huge drop in performance when evaluated on data outside their training set distribution. This critical issue makes them unsuitable for real-world settings. We propose RUBi, a new learning strategy to reduce biases in any VQA model. It reduces the importance of the most biased examples, i.e. examples that can be correctly classified without looking at the image. It implicitly forces the VQA model to use the two input modalities instead of relying on statistical regularities between the question and the answer. We leverage a question-only model that captures the language biases by identifying when these unwanted regularities are used. It prevents the base VQA model from learning them by influencing its predictions. This leads to dynamically adjusting the loss in order to compensate for biases. We validate our contributions by surpassing the current state-of-the-art results on VQA-CP v2. This dataset is specifically designed to assess the robustness of VQA models when exposed to different question biases at test time than what was seen during training. Our code is available: github.com/cdancette/rubi.bootstrap.pytorch
SplitNet: Sim2Sim and Task2Task Transfer for Embodied Visual Navigation
May 21, 2019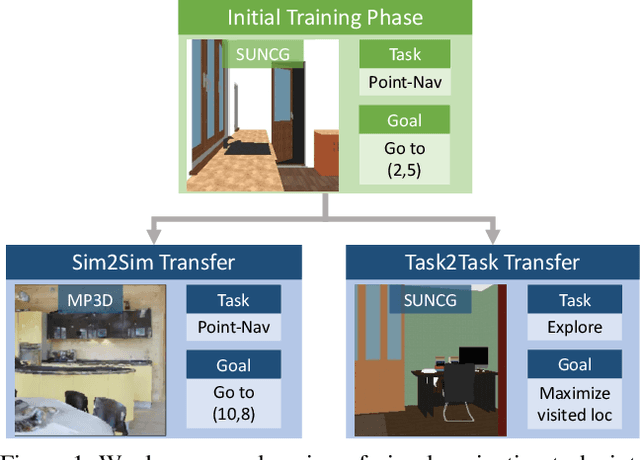
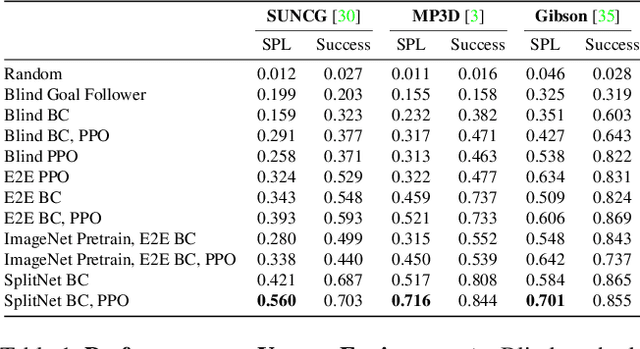
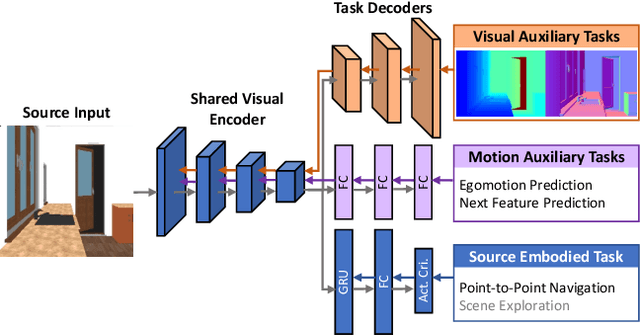
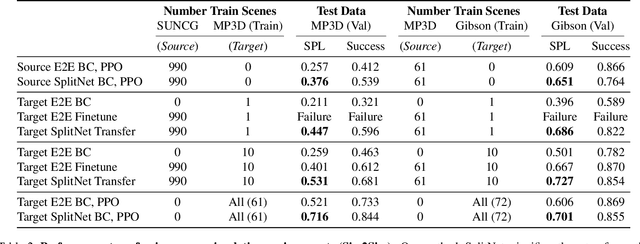
We propose SplitNet, a method for decoupling visual perception and policy learning. By incorporating auxiliary tasks and selective learning of portions of the model, we explicitly decompose the learning objectives for visual navigation into perceiving the world and acting on that perception. We show dramatic improvements over baseline models on transferring between simulators, an encouraging step towards Sim2Real. Additionally, SplitNet generalizes better to unseen environments from the same simulator and transfers faster and more effectively to novel embodied navigation tasks. Further, given only a small sample from a target domain, SplitNet can match the performance of traditional end-to-end pipelines which receive the entire dataset. Code and video are available at https://github.com/facebookresearch/splitnet and https://youtu.be/TJkZcsD2vrc
Towards VQA Models That Can Read
May 13, 2019
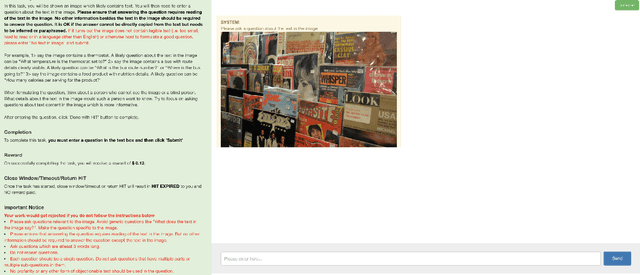
Studies have shown that a dominant class of questions asked by visually impaired users on images of their surroundings involves reading text in the image. But today's VQA models can not read! Our paper takes a first step towards addressing this problem. First, we introduce a new "TextVQA" dataset to facilitate progress on this important problem. Existing datasets either have a small proportion of questions about text (e.g., the VQA dataset) or are too small (e.g., the VizWiz dataset). TextVQA contains 45,336 questions on 28,408 images that require reasoning about text to answer. Second, we introduce a novel model architecture that reads text in the image, reasons about it in the context of the image and the question, and predicts an answer which might be a deduction based on the text and the image or composed of the strings found in the image. Consequently, we call our approach Look, Read, Reason & Answer (LoRRA). We show that LoRRA outperforms existing state-of-the-art VQA models on our TextVQA dataset. We find that the gap between human performance and machine performance is significantly larger on TextVQA than on VQA 2.0, suggesting that TextVQA is well-suited to benchmark progress along directions complementary to VQA 2.0.
Fashion++: Minimal Edits for Outfit Improvement
Apr 19, 2019

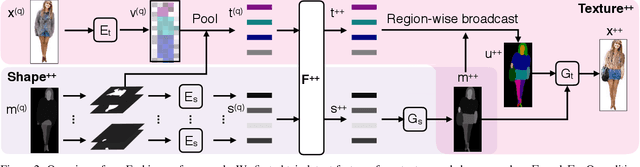
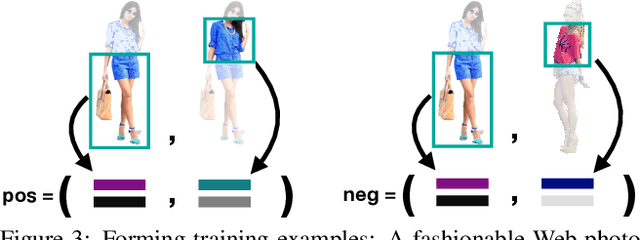
Given an outfit, what small changes would most improve its fashionability? This question presents an intriguing new vision challenge. We introduce Fashion++, an approach that proposes minimal adjustments to a full-body clothing outfit that will have maximal impact on its fashionability. Our model consists of a deep image generation neural network that learns to synthesize clothing conditioned on learned per-garment encodings. The latent encodings are explicitly factorized according to shape and texture, thereby allowing direct edits for both fit/presentation and color/patterns/material, respectively. We show how to bootstrap Web photos to automatically train a fashionability model, and develop an activation maximization-style approach to transform the input image into its more fashionable self. The edits suggested range from swapping in a new garment to tweaking its color, how it is worn (e.g., rolling up sleeves), or its fit (e.g., making pants baggier). Experiments demonstrate that Fashion++ provides successful edits, both according to automated metrics and human opinion. Project page is at http://vision.cs.utexas.edu/projects/FashionPlus.
Emergence of Compositional Language with Deep Generational Transmission
Apr 19, 2019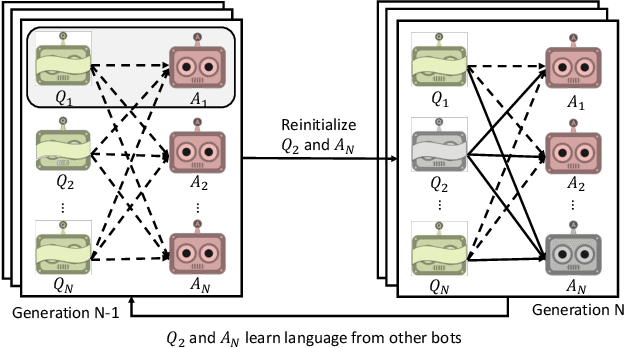
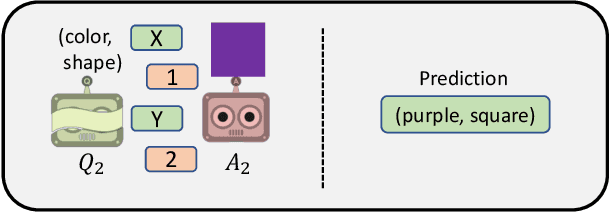
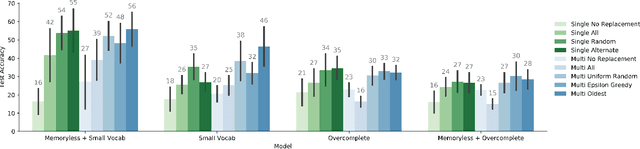
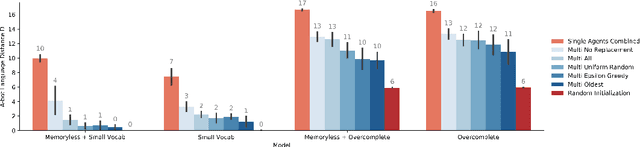
Consider a collaborative task that requires communication. Two agents are placed in an environment and must create a language from scratch in order to coordinate. Recent work has been interested in what kinds of languages emerge when deep reinforcement learning agents are put in such a situation, and in particular in the factors that cause language to be compositional-i.e. meaning is expressed by combining words which themselves have meaning. Evolutionary linguists have also studied the emergence of compositional language for decades, and they find that in addition to structural priors like those already studied in deep learning, the dynamics of transmitting language from generation to generation contribute significantly to the emergence of compositionality. In this paper, we introduce these cultural evolutionary dynamics into language emergence by periodically replacing agents in a population to create a knowledge gap, implicitly inducing cultural transmission of language. We show that this implicit cultural transmission encourages the resulting languages to exhibit better compositional generalization and suggest how elements of cultural dynamics can be further integrated into populations of deep agents.
Counterfactual Visual Explanations
Apr 16, 2019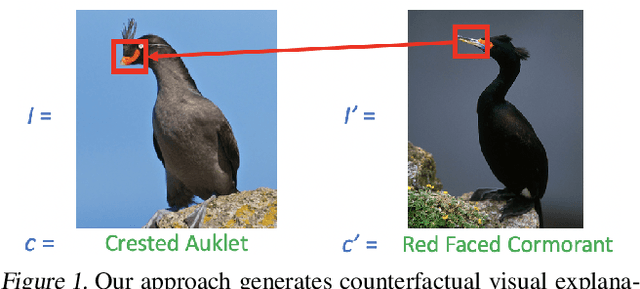
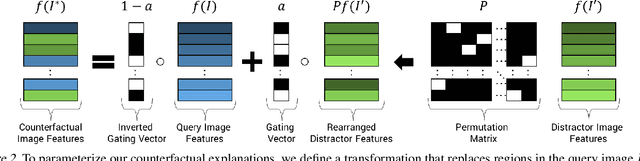
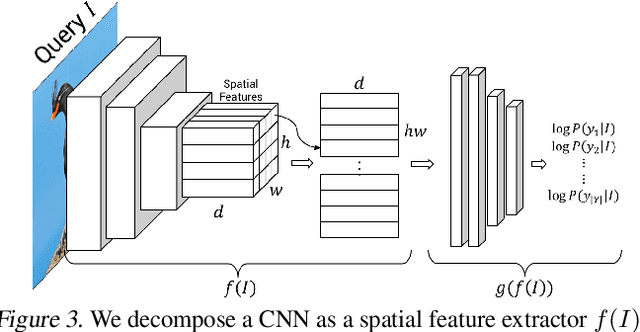
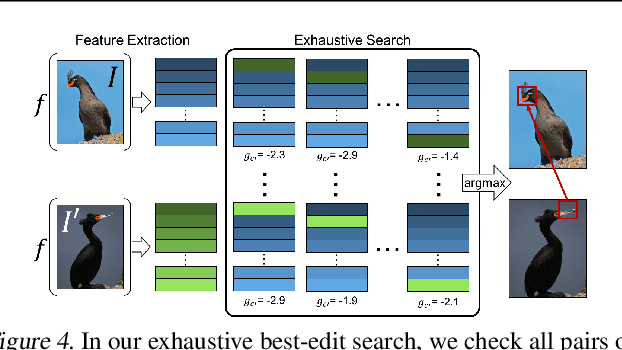
A counterfactual query is typically of the form 'For situation X, why was the outcome Y and not Z?'. A counterfactual explanation (or response to such a query) is of the form "If X was X*, then the outcome would have been Z rather than Y." In this work, we develop a technique to produce counterfactual visual explanations. Given a 'query' image $I$ for which a vision system predicts class $c$, a counterfactual visual explanation identifies how $I$ could change such that the system would output a different specified class $c'$. To do this, we select a 'distractor' image $I'$ that the system predicts as class $c'$ and identify spatial regions in $I$ and $I'$ such that replacing the identified region in $I$ with the identified region in $I'$ would push the system towards classifying $I$ as $c'$. We apply our approach to multiple image classification datasets generating qualitative results showcasing the interpretability and discriminativeness of our counterfactual explanations. To explore the effectiveness of our explanations in teaching humans, we present machine teaching experiments for the task of fine-grained bird classification. We find that users trained to distinguish bird species fare better when given access to counterfactual explanations in addition to training examples.
Embodied Visual Recognition
Apr 09, 2019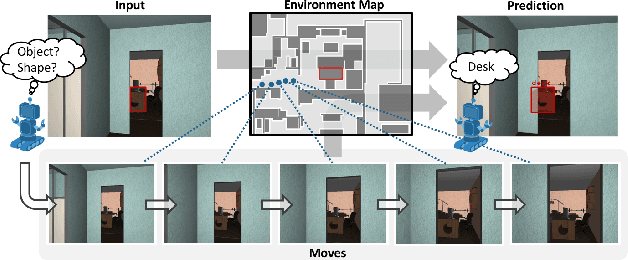
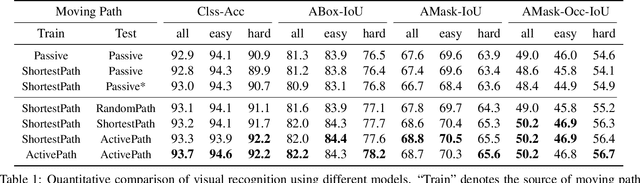
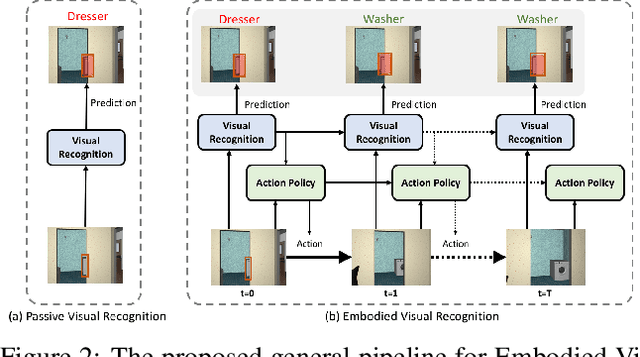
Passive visual systems typically fail to recognize objects in the amodal setting where they are heavily occluded. In contrast, humans and other embodied agents have the ability to move in the environment, and actively control the viewing angle to better understand object shapes and semantics. In this work, we introduce the task of Embodied Visual Recognition (EVR): An agent is instantiated in a 3D environment close to an occluded target object, and is free to move in the environment to perform object classification, amodal object localization, and amodal object segmentation. To address this, we develop a new model called Embodied Mask R-CNN, for agents to learn to move strategically to improve their visual recognition abilities. We conduct experiments using the House3D environment. Experimental results show that: 1) agents with embodiment (movement) achieve better visual recognition performance than passive ones; 2) in order to improve visual recognition abilities, agents can learn strategical moving paths that are different from shortest paths.
Embodied Question Answering in Photorealistic Environments with Point Cloud Perception
Apr 06, 2019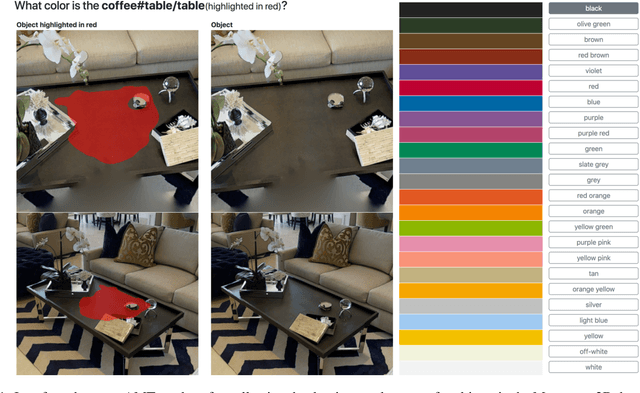
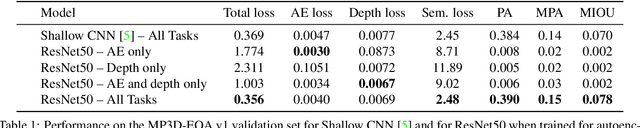
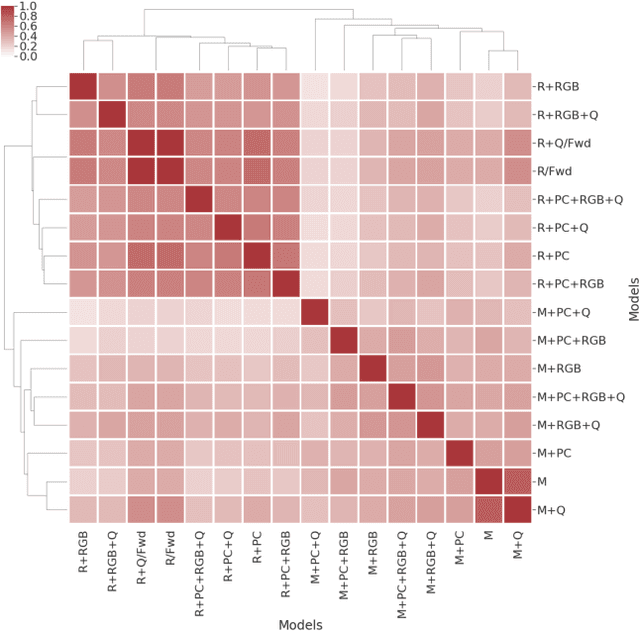
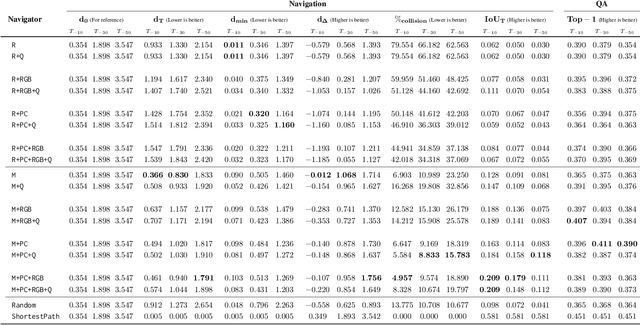
To help bridge the gap between internet vision-style problems and the goal of vision for embodied perception we instantiate a large-scale navigation task -- Embodied Question Answering [1] in photo-realistic environments (Matterport 3D). We thoroughly study navigation policies that utilize 3D point clouds, RGB images, or their combination. Our analysis of these models reveals several key findings. We find that two seemingly naive navigation baselines, forward-only and random, are strong navigators and challenging to outperform, due to the specific choice of the evaluation setting presented by [1]. We find a novel loss-weighting scheme we call Inflection Weighting to be important when training recurrent models for navigation with behavior cloning and are able to out perform the baselines with this technique. We find that point clouds provide a richer signal than RGB images for learning obstacle avoidance, motivating the use (and continued study) of 3D deep learning models for embodied navigation.
Habitat: A Platform for Embodied AI Research
Apr 02, 2019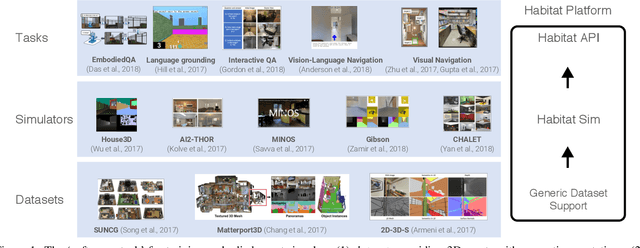
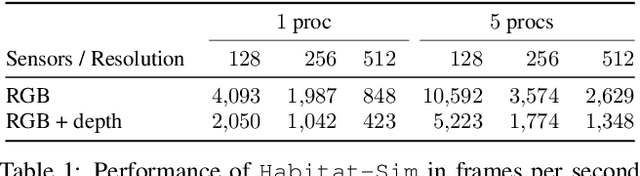

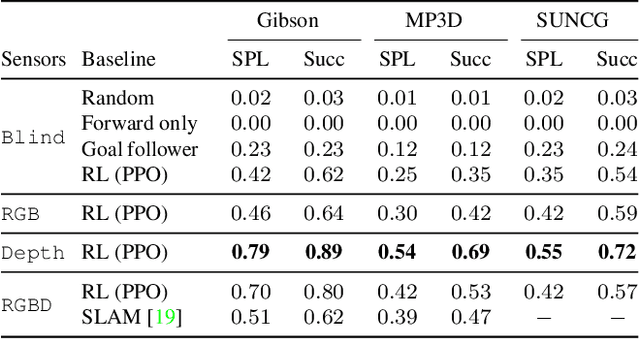
We present Habitat, a new platform for research in embodied artificial intelligence (AI). Habitat enables training embodied agents (virtual robots) in highly efficient photorealistic 3D simulation, before transferring the learned skills to reality. Specifically, Habitat consists of the following: 1. Habitat-Sim: a flexible, high-performance 3D simulator with configurable agents, multiple sensors, and generic 3D dataset handling (with built-in support for SUNCG, Matterport3D, Gibson datasets). Habitat-Sim is fast -- when rendering a scene from the Matterport3D dataset, Habitat-Sim achieves several thousand frames per second (fps) running single-threaded, and can reach over 10,000 fps multi-process on a single GPU, which is orders of magnitude faster than the closest simulator. 2. Habitat-API: a modular high-level library for end-to-end development of embodied AI algorithms -- defining embodied AI tasks (e.g. navigation, instruction following, question answering), configuring and training embodied agents (via imitation or reinforcement learning, or via classic SLAM), and benchmarking using standard metrics. These large-scale engineering contributions enable us to answer scientific questions requiring experiments that were till now impracticable or `merely' impractical. Specifically, in the context of point-goal navigation (1) we revisit the comparison between learning and SLAM approaches from two recent works and find evidence for the opposite conclusion -- that learning outperforms SLAM, if scaled to total experience far surpassing that of previous investigations, and (2) we conduct the first cross-dataset generalization experiments {train, test} x {Matterport3D, Gibson} for multiple sensors {blind, RGB, RGBD, D} and find that only agents with depth (D) sensors generalize across datasets. We hope that our open-source platform and these findings will advance research in embodied AI.
Align2Ground: Weakly Supervised Phrase Grounding Guided by Image-Caption Alignment
Mar 27, 2019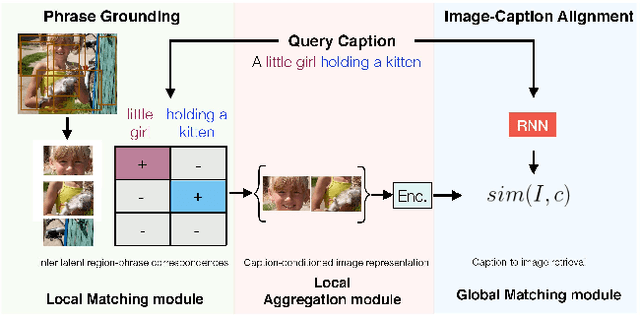
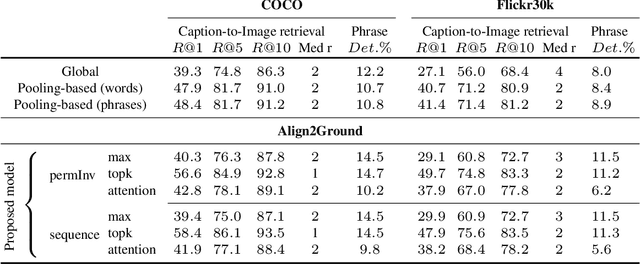

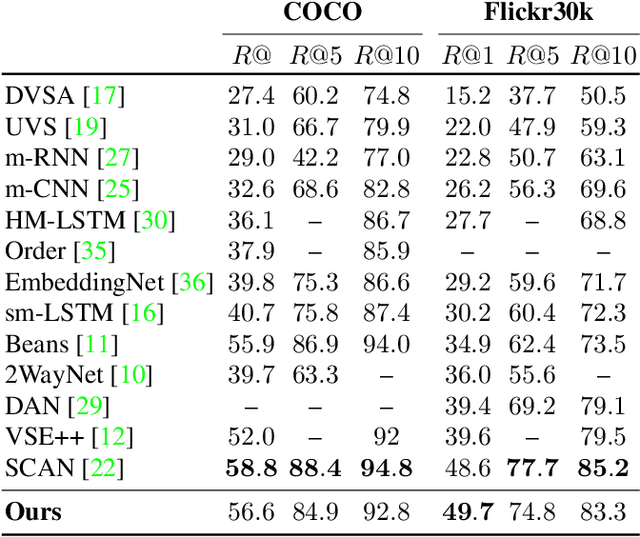
We address the problem of grounding free-form textual phrases by using weak supervision from image-caption pairs. We propose a novel end-to-end model that uses caption-to-image retrieval as a `downstream' task to guide the process of phrase localization. Our method, as a first step, infers the latent correspondences between regions-of-interest (RoIs) and phrases in the caption and creates a discriminative image representation using these matched RoIs. In a subsequent step, this (learned) representation is aligned with the caption. Our key contribution lies in building this `caption-conditioned' image encoding which tightly couples both the tasks and allows the weak supervision to effectively guide visual grounding. We provide an extensive empirical and qualitative analysis to investigate the different components of our proposed model and compare it with competitive baselines. For phrase localization, we report an improvement of 4.9% (absolute) over the prior state-of-the-art on the VisualGenome dataset. We also report results that are at par with the state-of-the-art on the downstream caption-to-image retrieval task on COCO and Flickr30k datasets.