 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBias Analysis in Unconditional Image Generative Models
Jun 10, 2025



The widespread adoption of generative AI models has raised growing concerns about representational harm and potential discriminatory outcomes. Yet, despite growing literature on this topic, the mechanisms by which bias emerges - especially in unconditional generation - remain disentangled. We define the bias of an attribute as the difference between the probability of its presence in the observed distribution and its expected proportion in an ideal reference distribution. In our analysis, we train a set of unconditional image generative models and adopt a commonly used bias evaluation framework to study bias shift between training and generated distributions. Our experiments reveal that the detected attribute shifts are small. We find that the attribute shifts are sensitive to the attribute classifier used to label generated images in the evaluation framework, particularly when its decision boundaries fall in high-density regions. Our empirical analysis indicates that this classifier sensitivity is often observed in attributes values that lie on a spectrum, as opposed to exhibiting a binary nature. This highlights the need for more representative labeling practices, understanding the shortcomings through greater scrutiny of evaluation frameworks, and recognizing the socially complex nature of attributes when evaluating bias.
CulturalFrames: Assessing Cultural Expectation Alignment in Text-to-Image Models and Evaluation Metrics
Jun 10, 2025The increasing ubiquity of text-to-image (T2I) models as tools for visual content generation raises concerns about their ability to accurately represent diverse cultural contexts. In this work, we present the first study to systematically quantify the alignment of T2I models and evaluation metrics with respect to both explicit as well as implicit cultural expectations. To this end, we introduce CulturalFrames, a novel benchmark designed for rigorous human evaluation of cultural representation in visual generations. Spanning 10 countries and 5 socio-cultural domains, CulturalFrames comprises 983 prompts, 3637 corresponding images generated by 4 state-of-the-art T2I models, and over 10k detailed human annotations. We find that T2I models not only fail to meet the more challenging implicit expectations but also the less challenging explicit expectations. Across models and countries, cultural expectations are missed an average of 44% of the time. Among these failures, explicit expectations are missed at a surprisingly high average rate of 68%, while implicit expectation failures are also significant, averaging 49%. Furthermore, we demonstrate that existing T2I evaluation metrics correlate poorly with human judgments of cultural alignment, irrespective of their internal reasoning. Collectively, our findings expose critical gaps, providing actionable directions for developing more culturally informed T2I models and evaluation methodologies.
MAPL: Parameter-Efficient Adaptation of Unimodal Pre-Trained Models for Vision-Language Few-Shot Prompting
Oct 13, 2022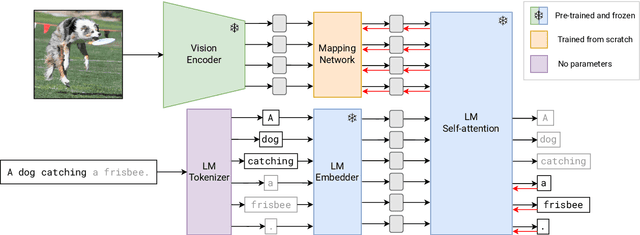

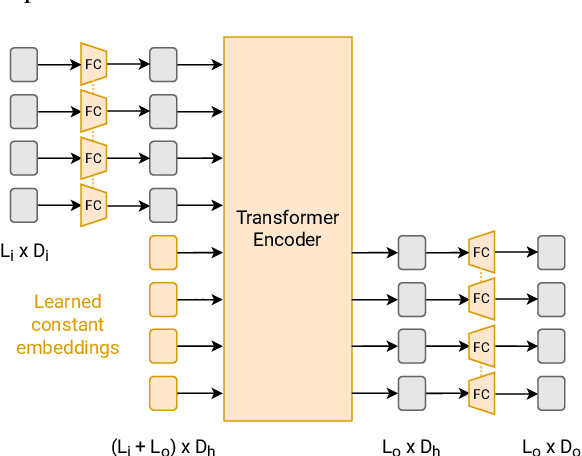
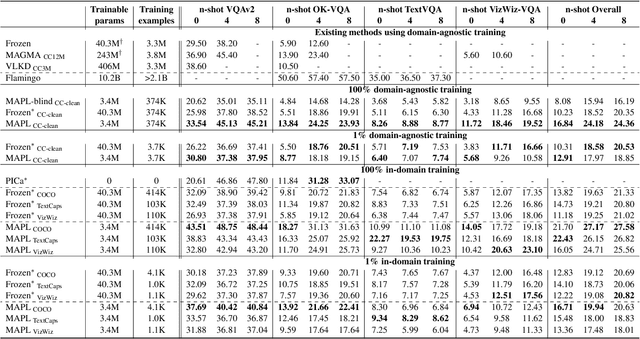
Large pre-trained models have proved to be remarkable zero- and (prompt-based) few-shot learners in unimodal vision and language tasks. We propose MAPL, a simple and parameter-efficient method that reuses frozen pre-trained unimodal models and leverages their strong generalization capabilities in multimodal vision-language (VL) settings. MAPL learns a lightweight mapping between the representation spaces of unimodal models using aligned image-text data, and can generalize to unseen VL tasks from just a few in-context examples. The small number of trainable parameters makes MAPL effective at low-data and in-domain learning. Moreover, MAPL's modularity enables easy extension to other pre-trained models. Extensive experiments on several visual question answering and image captioning benchmarks show that MAPL achieves superior or competitive performance compared to similar methods while training orders of magnitude fewer parameters. MAPL can be trained in just a few hours using modest computational resources and public datasets. We plan to release the code and pre-trained models.
Image Retrieval from Contextual Descriptions
Mar 29, 2022


The ability to integrate context, including perceptual and temporal cues, plays a pivotal role in grounding the meaning of a linguistic utterance. In order to measure to what extent current vision-and-language models master this ability, we devise a new multimodal challenge, Image Retrieval from Contextual Descriptions (ImageCoDe). In particular, models are tasked with retrieving the correct image from a set of 10 minimally contrastive candidates based on a contextual description. As such, each description contains only the details that help distinguish between images. Because of this, descriptions tend to be complex in terms of syntax and discourse and require drawing pragmatic inferences. Images are sourced from both static pictures and video frames. We benchmark several state-of-the-art models, including both cross-encoders such as ViLBERT and bi-encoders such as CLIP, on ImageCoDe. Our results reveal that these models dramatically lag behind human performance: the best variant achieves an accuracy of 20.9 on video frames and 59.4 on static pictures, compared with 90.8 in humans. Furthermore, we experiment with new model variants that are better equipped to incorporate visual and temporal context into their representations, which achieve modest gains. Our hope is that ImageCoDE will foster progress in grounded language understanding by encouraging models to focus on fine-grained visual differences.
Question-Conditioned Counterfactual Image Generation for VQA
Nov 14, 2019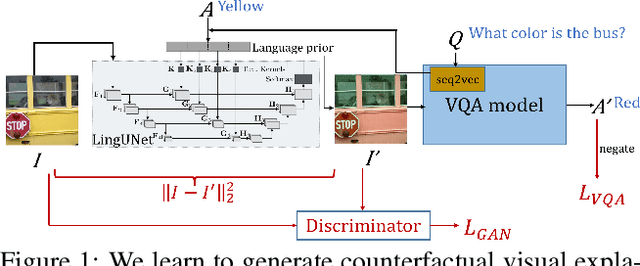

While Visual Question Answering (VQA) models continue to push the state-of-the-art forward, they largely remain black-boxes - failing to provide insight into how or why an answer is generated. In this ongoing work, we propose addressing this shortcoming by learning to generate counterfactual images for a VQA model - i.e. given a question-image pair, we wish to generate a new image such that i) the VQA model outputs a different answer, ii) the new image is minimally different from the original, and iii) the new image is realistic. Our hope is that providing such counterfactual examples allows users to investigate and understand the VQA model's internal mechanisms.
Explaining Classifiers with Causal Concept Effect (CaCE)
Jul 16, 2019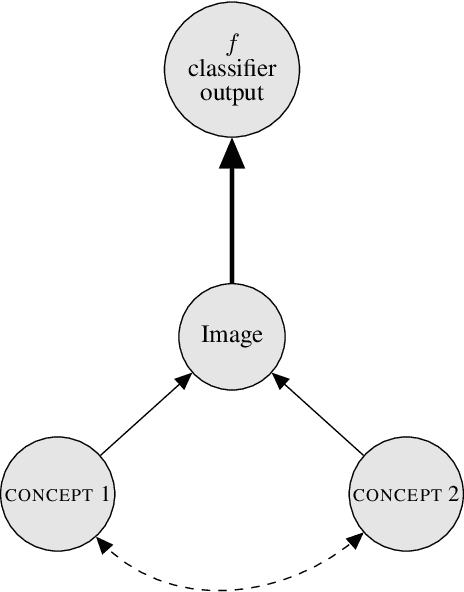
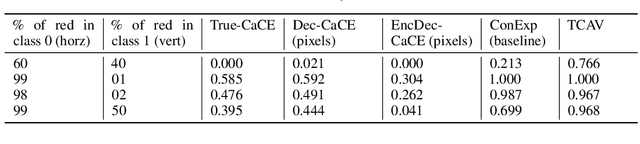


How can we understand classification decisions made by deep neural nets? We propose answering this question by using ideas from causal inference. We define the ``Causal Concept Effect'' (CaCE) as the causal effect that the presence or absence of a concept has on the prediction of a given deep neural net. We then use this measure as a mean to understand what drives the network's prediction and what does not. Yet many existing interpretability methods rely solely on correlations, resulting in potentially misleading explanations. We show how CaCE can avoid such mistakes. In high-risk domains such as medicine, knowing the root cause of the prediction is crucial. If we knew that the network's prediction was caused by arbitrary concepts such as the lighting conditions in an X-ray room instead of medically meaningful concept, this would prevent us from disastrous deployment of such models. Estimating CaCE is difficult in situations where we cannot easily simulate the do-operator. As a simple solution, we propose learning a generative model, specifically a Variational AutoEncoder (VAE) on image pixels or image embeddings extracted from the classifier to measure VAE-CaCE. We show that VAE-CaCE is able to correctly estimate the true causal effect as compared to other baselines in controlled settings with synthetic and semi-natural high dimensional images.
Counterfactual Visual Explanations
Apr 16, 2019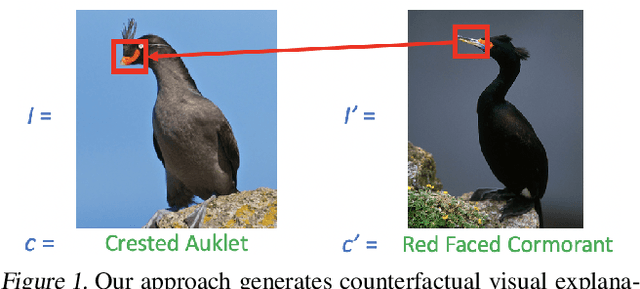
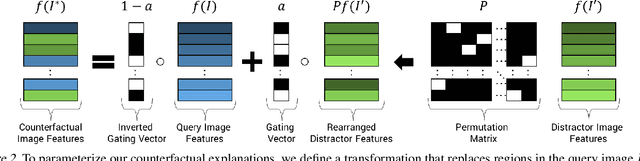
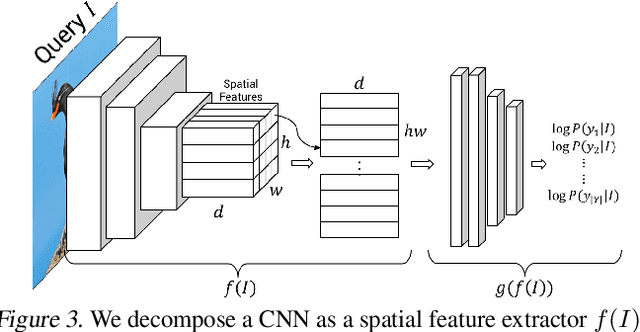
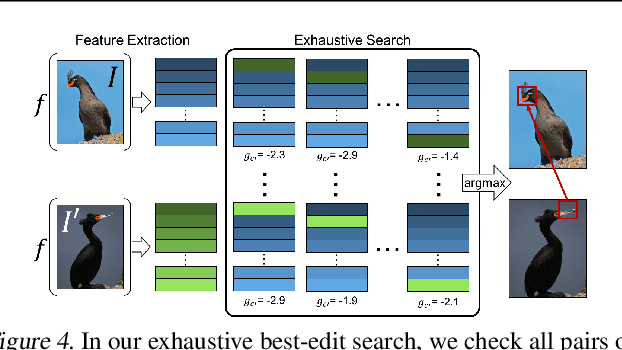
A counterfactual query is typically of the form 'For situation X, why was the outcome Y and not Z?'. A counterfactual explanation (or response to such a query) is of the form "If X was X*, then the outcome would have been Z rather than Y." In this work, we develop a technique to produce counterfactual visual explanations. Given a 'query' image $I$ for which a vision system predicts class $c$, a counterfactual visual explanation identifies how $I$ could change such that the system would output a different specified class $c'$. To do this, we select a 'distractor' image $I'$ that the system predicts as class $c'$ and identify spatial regions in $I$ and $I'$ such that replacing the identified region in $I$ with the identified region in $I'$ would push the system towards classifying $I$ as $c'$. We apply our approach to multiple image classification datasets generating qualitative results showcasing the interpretability and discriminativeness of our counterfactual explanations. To explore the effectiveness of our explanations in teaching humans, we present machine teaching experiments for the task of fine-grained bird classification. We find that users trained to distinguish bird species fare better when given access to counterfactual explanations in addition to training examples.
Making the V in VQA Matter: Elevating the Role of Image Understanding in Visual Question Answering
May 15, 2017
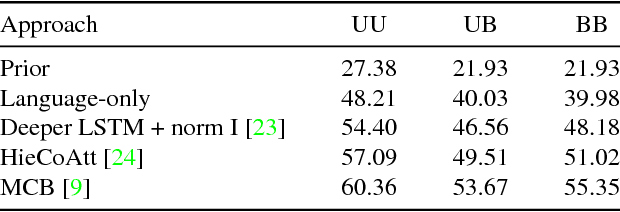
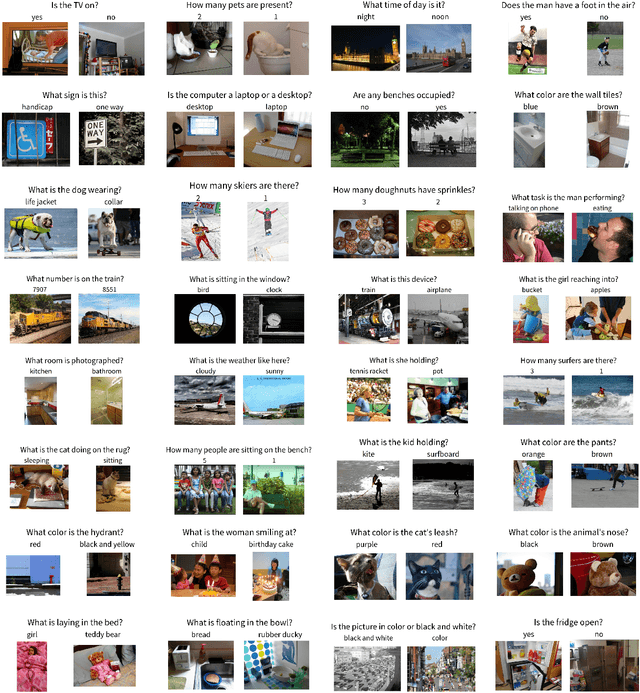
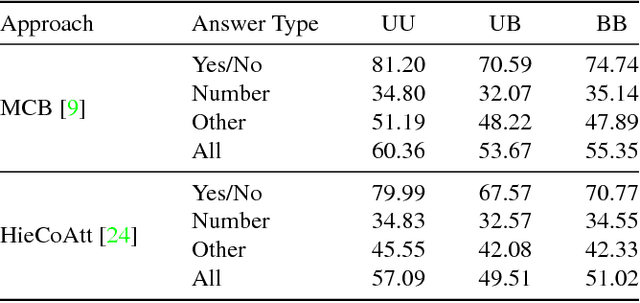
Problems at the intersection of vision and language are of significant importance both as challenging research questions and for the rich set of applications they enable. However, inherent structure in our world and bias in our language tend to be a simpler signal for learning than visual modalities, resulting in models that ignore visual information, leading to an inflated sense of their capability. We propose to counter these language priors for the task of Visual Question Answering (VQA) and make vision (the V in VQA) matter! Specifically, we balance the popular VQA dataset by collecting complementary images such that every question in our balanced dataset is associated with not just a single image, but rather a pair of similar images that result in two different answers to the question. Our dataset is by construction more balanced than the original VQA dataset and has approximately twice the number of image-question pairs. Our complete balanced dataset is publicly available at www.visualqa.org as part of the 2nd iteration of the Visual Question Answering Dataset and Challenge (VQA v2.0). We further benchmark a number of state-of-art VQA models on our balanced dataset. All models perform significantly worse on our balanced dataset, suggesting that these models have indeed learned to exploit language priors. This finding provides the first concrete empirical evidence for what seems to be a qualitative sense among practitioners. Finally, our data collection protocol for identifying complementary images enables us to develop a novel interpretable model, which in addition to providing an answer to the given (image, question) pair, also provides a counter-example based explanation. Specifically, it identifies an image that is similar to the original image, but it believes has a different answer to the same question. This can help in building trust for machines among their users.
CloudCV: Large Scale Distributed Computer Vision as a Cloud Service
Feb 13, 2017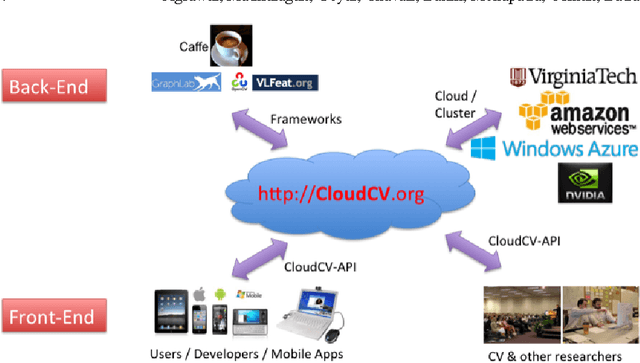
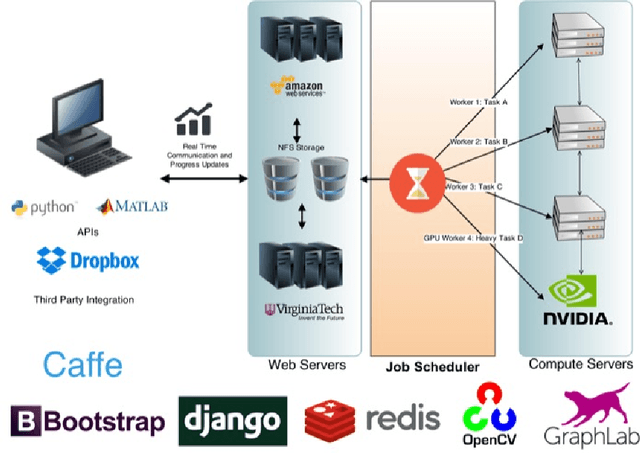
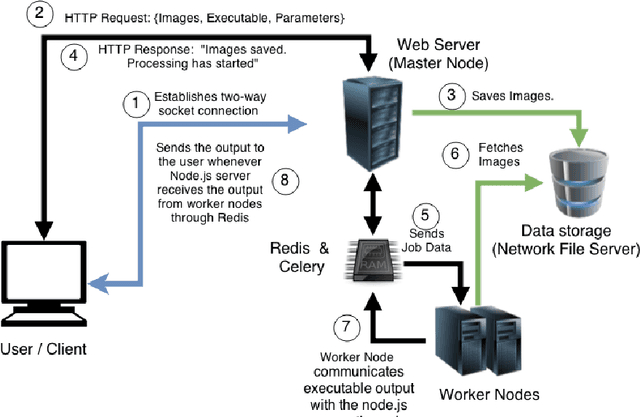
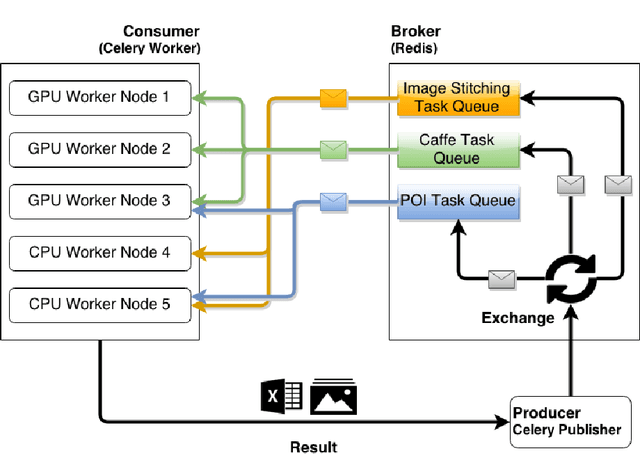
We are witnessing a proliferation of massive visual data. Unfortunately scaling existing computer vision algorithms to large datasets leaves researchers repeatedly solving the same algorithmic, logistical, and infrastructural problems. Our goal is to democratize computer vision; one should not have to be a computer vision, big data and distributed computing expert to have access to state-of-the-art distributed computer vision algorithms. We present CloudCV, a comprehensive system to provide access to state-of-the-art distributed computer vision algorithms as a cloud service through a Web Interface and APIs.
Resolving Language and Vision Ambiguities Together: Joint Segmentation & Prepositional Attachment Resolution in Captioned Scenes
Sep 26, 2016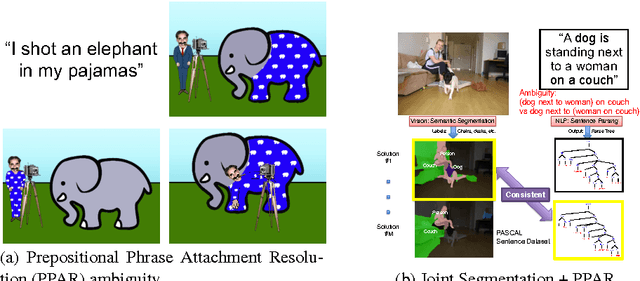
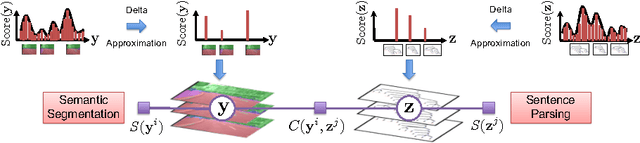
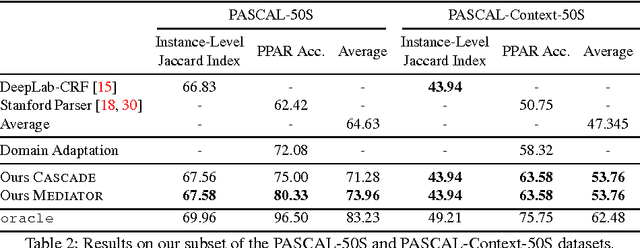
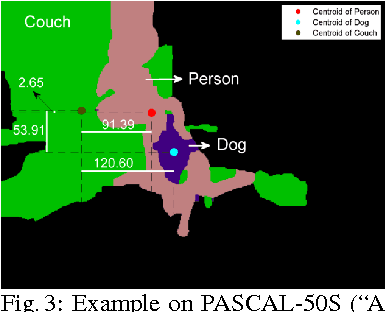
We present an approach to simultaneously perform semantic segmentation and prepositional phrase attachment resolution for captioned images. Some ambiguities in language cannot be resolved without simultaneously reasoning about an associated image. If we consider the sentence "I shot an elephant in my pajamas", looking at language alone (and not using common sense), it is unclear if it is the person or the elephant wearing the pajamas or both. Our approach produces a diverse set of plausible hypotheses for both semantic segmentation and prepositional phrase attachment resolution that are then jointly reranked to select the most consistent pair. We show that our semantic segmentation and prepositional phrase attachment resolution modules have complementary strengths, and that joint reasoning produces more accurate results than any module operating in isolation. Multiple hypotheses are also shown to be crucial to improved multiple-module reasoning. Our vision and language approach significantly outperforms the Stanford Parser (De Marneffe et al., 2006) by 17.91% (28.69% relative) and 12.83% (25.28% relative) in two different experiments. We also make small improvements over DeepLab-CRF (Chen et al., 2015).